高密度脂蛋白过滤器体系结构
HDL Coder™软件提供了架构选项,可扩展您在实现滤波器设计时对速度与面积权衡的控制。为了实现对生成的HDL代码的理想权衡,您可以指定一个完全并行的体系结构,或者从几个串行体系结构中选择一个。使用。配置串行架构SerialPartition(高密度脂蛋白编码器)和ReuseAccum(高密度脂蛋白编码器)参数。您还可以选择基于帧的过滤器来提高吞吐量。
使用流水线参数来提高过滤器设计的速度性能。使用管道添加到过滤器的加法器逻辑AddPipelineRegisters(高密度脂蛋白编码器)对于标量输入过滤器,和AdderTreePipeline(高密度脂蛋白编码器)对于框架的过滤器。指定管道阶段之前和之后的每个乘数MultiplierInputPipeline(高密度脂蛋白编码器)和MultiplierOutputPipeline(高密度脂蛋白编码器).设置过滤器使用前后的管道阶段数InputPipeline(高密度脂蛋白编码器)和OutputPipeline(高密度脂蛋白编码器).架构图显示了各种可配置管道阶段的位置。
完全并行体系结构
此选项是默认架构。一个完全并行的架构使用专用的乘法器和加法器为每个过滤器点击。丝锥并行执行。完全并行的架构在速度上是最优的。然而,它比串行架构需要更多的乘法器和加法器,因此占用更多的芯片面积。这些图显示了直接形式和完全并行实现的置换过滤器结构的体系结构,以及可配置管道阶段的位置。
直接的形式
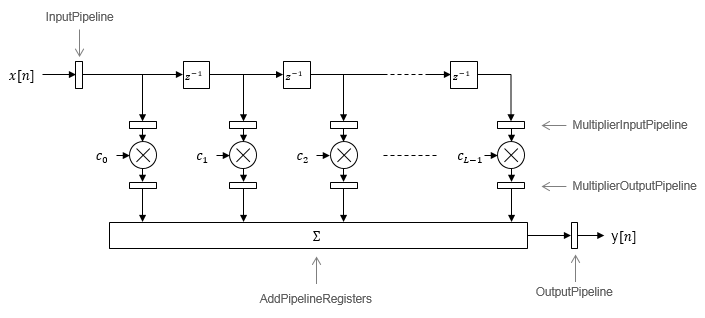
默认情况下,块实现线性加法器逻辑。当你使AddPipelineRegisters,加法器逻辑实现为流水线加法器树。加法器树使用全精度数据类型。如果生成验证模型,则必须在原始模型中使用完全精度,以避免验证不匹配。
转置
![]()
的AddPipelineRegisters参数对转换滤波器的实现没有影响。
串行架构
串行架构能及时重用硬件资源,节省芯片面积。使用。配置串行架构SerialPartition(高密度脂蛋白编码器)和ReuseAccum(高密度脂蛋白编码器)参数。可用的串行架构选项有全系列,部分系列,级联序列.
全系列
全串行架构通过顺序重用乘法器和加法器资源来节省空间。例如,四抽头滤波器设计使用一个乘法器和加法器,每次抽头执行一次乘数累积操作。该设计的倍数累积部分以滤波器输入/输出采样率的四倍运行。这种设计在一定的速度损失和较高的功耗的代价下节省了面积。
在全串行架构中,系统时钟以比滤波器的采样率高得多的速率运行。因此,对于给定的滤波器设计,全串行结构所能达到的最大速度小于并行结构。
部分系列
部分串行架构涵盖了完全并行和完全串行架构之间的速度和区域权衡的全部范围。
在部分串行架构中,过滤器点击被分成许多串行分区。每个分区内的点击按顺序执行,但分区之间是并行执行的。分区的输出在最终输出处相加。
当您选择部分串行架构时,您需要指定分区的数量和每个分区的长度(点击次数)。假设您指定了一个带有两个分区的四次点击过滤器,每个分区有两次点击。系统时钟以两倍滤波器采样率运行。
级联序列
级联-串行体系结构非常类似于部分串行体系结构。就像在部分串行架构中一样,过滤器点击被分成许多串行分区,这些分区彼此并行执行。但是,每个分区的累积输出级联到前一个分区的累加器。因此,所有分区的输出都在第一个分区的累加器处计算。这种技术被称为蓄电池重用.最终的加法器是不需要的,这节省了面积。
级联-串行架构需要额外的系统时钟周期来完成输出的最终总和。因此,相对于非级联部分串行架构中使用的时钟,系统时钟的频率必须稍微增加。
要生成级联-串行架构,请指定启用累加器重用的部分串行架构。如果不指定串行分区,HDL Coder会自动选择一个最佳分区。
串行架构中的延迟
串行化滤波器使设计的总延迟增加一个时钟周期。串行架构使用累加器(带寄存器的加法器)来按顺序添加产品。下载188bet金宝搏额外的最终寄存器用于存储所有串行分区的加和结果,需要额外的时钟周期来进行操作。为了对这个延迟进行建模,HDL Coder在过滤器块之后将一个Delay块插入到生成的模型中。
串行架构的全精度
当您选择串行架构时,代码生成器在HDL代码中使用完全精度。因此,HDL编码器要求生成的模型具有完全的精度。如果生成验证模型,则必须在原始模型中使用完全精度,以避免验证不匹配。
框架体系结构
当您选择基于框架的体系结构并提供米-sample输入帧,编码器实现了一个完全并行的滤波器架构。过滤器包括米每个输入样本的并行子滤波器。

每个子过滤器包括每个米系数。添加子过滤器结果,使每个输出样本是每个系数与一个输入样本相乘的和。

图中显示了两个示例(米= 2),过滤器长度为6个系数。输入是一个向量,有两个值表示时间上的样本。输入样本,x (2 n)和x (2 n + 1),代表了n输入一对。每一秒从每个流的样本被馈送到两个并行的子过滤器。将四个子过滤器结果相加以创建两个输出示例。这样,每个输出样本就是每个系数与一个输入样本相乘的和。
求和被实现为流水线加法器树。集AdderTreePipeline(高密度脂蛋白编码器)指定加法器树各层之间的流水线阶段数。为了提高时钟速度,建议设置为2.为了将乘法器放入FPGA上的DSP块中,在乘法器使用之前和之后添加流水线阶段MultiplierInputPipeline(高密度脂蛋白编码器)和MultiplierOutputPipeline(高密度脂蛋白编码器).

对于对称或反对称系数,滤波器结构重用系数乘数,并根据需要在乘数和求和阶段之间增加设计延迟。
相关的话题
- HDL过滤器块属性(高密度脂蛋白编码器)
- HDL滤波器的分布式算法(高密度脂蛋白编码器)
你也可以从以下列表中选择一个网站: