HDL块属性:一般
概述
块实现参数使您能够控制为特定块实现生成的代码的细节。看到设置和查看HDL模型和块参数了解如何在GUI或命令行中选择块实现和参数。
属性名被指定为字符向量。属性值的数据类型特定于该属性。本节描述每个块实现参数的语法,以及参数如何影响生成的代码。
库块的HDL块属性
库块的HDL块属性处理类似于掩码参数。在模型中实例化库块时,该库块的当前HDL块属性被复制到模型中该块的实例中。这些实例的HDL块属性与库块的HDL块属性不同步。也就是说,如果您更改了库块的HDL块属性,更改不会传播到您已经添加到Simulink的库块的实例金宝app®模型。如果您希望库块的HDL块属性与其模型中的实例同步,请创建子系统然后把这个方块放到里面子系统.驻留在库块内的块的HDL块属性与模型中的相应实例同步。
假设一个库包含一个子系统块,将HDL架构设置为模块.当您在模型中实例化此块时,块实例使用模块作为HDL架构。的HDL架构子系统Block in the library to黑箱,现有的例子子系统块在你的模型中仍然使用模块作为HDL架构。的实例子系统块,新的块实例将获得当前HDL块属性的副本,并因此使用黑箱作为HDL架构。如果你想要的HDL架构子系统块在库中要与其在模型中的实例同步,创建一个包装器子系统,其中包含您想要的HDL架构子系统.
AdaptivePipelining
的AdaptivePipelining子系统参数允许您在模型中的子系统上设置自适应管道。
| 自适应流水线设置 | 描述 |
|---|---|
“继承”(默认) |
使用父子系统的自适应管道设置。如果该子系统是最高级别的子系统,则为模型使用自适应管道设置。 |
“上” |
为这个子系统插入自适应管道。 |
'离开' |
不要为这个子系统插入自适应管道,即使父子系统启用了自适应管道。 |
要禁用模型内的子系统的自适应流水线,请设置自适应流水线参数,AdaptivePipelining, 到'离开'子系统。
要了解如何设置模型级自适应管道,请参见自适应流水线.
设置子系统的自适应管道
要从HDL块属性对话框中为子系统设置自适应管道:
右键单击子系统并选择HDL代码>高密度脂蛋白块属性.
为AdaptivePipelining中,选择继承,在,或从.
要从命令行设置子系统的自适应管道,请使用hdlset_param.例如,要关闭子系统的自适应管道,my_dut:
hdlset_param (“my_dut”,“AdaptivePipelining”,'离开')
hdlset_param.
balanceelays.
的balanceelays.子系统参数允许您在模型内的子系统上设置延迟均衡。
| BALACSENTELAYS设置 | 描述 |
|---|---|
“继承”(默认) |
使用父子系统的延迟均衡设置。如果该子系统是最高级别的子系统,则使用该模型的延迟平衡设置。 |
“上” |
平衡这个子系统的延迟。 |
'离开' |
不要为这个子系统均衡延迟,即使父子系统启用了延迟均衡。 |
若要禁用模型内任何子系统的延迟平衡,必须设置模型级延迟平衡参数,balanceelays., 到'离开'.当模型上启用延迟均衡时,单个子系统上的延迟均衡设置将被忽略。
要学习如何设置模型级延迟平衡,请参见平衡延迟.
为子系统设置延迟平衡
使用HDL块属性对话框为子系统设置延迟平衡:
右键单击该子系统。
选择HDL代码>高密度脂蛋白块属性.
为balanceelays.中,选择继承,在,或从.
要从命令行设置子系统的延迟平衡,请使用hdlset_param.例如,要关闭子系统的延迟平衡,my_dut:
hdlset_param (“my_dut”,“BalanceDelays”,'离开')
hdlset_param.
ClockRatePipelining
的ClockRatePipelining子系统参数允许您在模型中的子系统上设置时钟速率管道。
| 时钟频率管道设置 | 描述 |
|---|---|
“继承”(默认) |
使用父子系统的时钟速率流水线设置。如果该子系统是最高级别的子系统,则使用该模型的时钟速率管道设置。 |
“上” |
为这个子系统插入时钟速率管道。 |
'离开' |
不要为这个子系统插入时钟速率管道,即使父子系统启用了时钟速率管道。 |
若要禁用模型中某个子系统的时钟速率流水线,请设置时钟速率流水线参数,ClockRatePipelining, 到'离开'子系统。
要学习如何设置模型级时钟速率流水线,请参阅时钟频率流水线.
为子系统设置时钟速率流水线
使用HDL块属性对话框设置子系统的时钟速率流水线:
右键单击该子系统。
选择HDL代码>高密度脂蛋白块属性.
为ClockRatePipelining中,选择继承,在,或从.
要从命令行设置子系统的时钟速率管道,请使用hdlset_param.例如,要关闭子系统的时钟速率流水线,my_dut:
hdlset_param (“my_dut”,“ClockRatePipelining”,'离开')
hdlset_param.
CodingStyle
当你使用多端口切换块,用CodingStyle参数指定是否要使用if-else或case语句生成HDL代码。默认情况下,HDL Coder™生成if-else语句。如果你有几个多端口切换块,您可以选择指定一个不同的CodingStyle对于每个块。
| CodingStyle设置 | 描述 |
|---|---|
“ifelse_stmt”(默认的) |
在Verilog代码中生成if-else语句,或者在VHDL代码中生成when-else语句多端口切换块。 |
“case_stmt” |
在Verilog代码中生成case语句,或在VHDL代码中生成case-when语句多端口切换块。 |
设置CodingStyle多端口切换堵塞
为a设置codingstyle多端口切换使用HDL块属性对话框:
右键单击多端口切换块。
选择HDL代码>高密度脂蛋白块属性.
为CodingStyle中,选择
ifelse_stmt或case_stmt.
去看CodingStyle从命令行指定一个子系统,使用hdlget_param.例如,要查看为多端口切换块在子系统中,my_dut:
hdlget_param('my_dut / multiport switch','codingstyle')
ans = ' case_stmt '
hdlset_param.
ConstMultiplierOptimization
的ConstMultiplierOptimization实现参数允许您指定规范有符号数字(CSD)或因子CSD优化的使用,以处理生成代码中的系数乘法器操作。
下表显示了ConstMultiplierOptimization参数值。
| ConstMultiplierOptimization设置 | 描述 |
|---|---|
“没有”(默认的) |
默认情况下,HDL编码器不执行CSD或FCSD优化。为增益块生成的代码保留了乘法器操作。 |
“CSD” |
当您指定此选项时,生成的代码将减少模型使用的区域,同时使用规范有符号数字(CSD)技术保持或增加时钟速度。CSD将乘数运算替换为加减运算。CSD通过用最少的非零位数来表示二进制数,从而减少常量乘法所需的加法运算次数。 |
“FCSD” |
这个选项使用因子化CSD (FCSD)技术,它用操作数的某些因子的移位和加减运算代替乘数运算。这些因子通常是质数,但也可以是接近2的幂的数字,这有利于缩小面积。这个选项允许您实现比CSD更大的面积缩减,但代价是降低时钟速度。 |
“汽车” |
当指定此选项时,HDL Coder将在CSD或FCSD优化之间进行选择。编码器根据所需的加法器数量选择最有效的实现方案。当你指定 |
的ConstMultiplierOptimization参数可用于以下块:
获得
Stateflow®图表
真值表
MATLAB函数
MATLAB系统
ConstrainedOutputPipeline
使用ConstrainedOutputPipeline参数指定要放置在块输出上的非负寄存器数。
HDL编码器在您的设计中移动现有的延迟以尝试满足您的限制。没有添加新的寄存器。如果寄存器数量少于编码器满足约束所需的寄存器数量,编码器将报告所需输出寄存器数量与实际输出寄存器数量之间的差异。可以使用输入或输出管道将延迟添加到设计中。
分布式管道不会重新分布使用受约束的输出管道指定的寄存器。
如何指定约束的输出管道
使用GUI为块指定受约束的输出管道:
右键单击该块并选择HDL代码>高密度脂蛋白块属性.
为ConstrainedOutputPipeline,输入在输出端口需要的寄存器数量。
要指定受约束的输出管道,请在命令行输入:
hdlset_param (path_to_block'controweroutputpipine'number_of_output_registers)
中高,在你的模型中,mymodel,输入:hdlset_param (“mymodel /中高辊”,'controweroutputpipine'6)
另请参阅
DistributedPipelining
的DistributedPipelining参数启用管道寄存器分布,这是一种速度优化,使您能够通过减少关键路径来提高时钟速度。
下表显示了该方法的效果DistributedPipelining和OutputPipeline参数。
| DistributedPipelining | OutputPipeline, nStages | 结果 |
|---|---|---|
'离开'(默认) |
未指定的(nStages默认为0) |
HDL编码器不插入管道寄存器。 |
nStages> 0 |
编码器插入nStages输出寄存器在子系统的输出,MATLAB函数块或状态流程图。 |
|
“上” |
未指定的(nStages默认为0) |
编码器不会插入管道寄存器。DistributedPipelining没有效果。 |
nStages> 0 |
编码器的分配nStages子系统内的寄存器,MATLAB函数块,或状态流程图,基于关键路径分析。 |
为了进一步优化使用分布式管道生成的代码,如果可能,请在RTL合成期间执行重定时。
提示
如果插入管道寄存器,最初输出数据可能处于无效状态。若要避免由初始无效样本导致的测试台错误,请禁用这些样本的输出检查。有关更多信息,请参见忽略输出数据检查(样本数).
另请参阅
dot下载188bet金宝搏productstritegy.
如果你使用产品块的矩阵乘法,在你的设计中,使用dot下载188bet金宝搏productstritegy.来指定您想要如何实现矩阵乘法。
的dot下载188bet金宝搏productstritegy.下表列出了选项。
| Dot下载188bet金宝搏ProductStrategy价值 | 描述 |
|---|---|
完全平行的(默认) |
将矩阵乘法运算扩展为乘法器和加法器。例如,如果将两个2x2矩阵乘以,则实现使用四个乘法器和两个加法器来计算结果。 请注意 的dot下载188bet金宝搏productstritegy.必须设置为 |
“完全平行Scalarized” |
将矩阵乘法运算扩展为乘法器和加法器。例如,如果您将两个2x2矩阵相乘,则实现使用8个乘数和4个加法器来计算结果。当您想在乘数和加法器上同时启用共享时,请使用此选项。 |
“连环Multiply-Accumulate” |
使用串行的架构Multiply-Accumulate块来实现矩阵乘法。 在此体系结构中,时钟速率必须比您指定的时钟速率快平行体系结构。您可以在代码生成报告的时钟摘要信息中看到时钟速率。 |
“平行Multiply-Accumulate” |
使用平行的架构Multiply-Accumulate块来实现矩阵乘法。 |
DSPStyle
DSPStyle使您能够在设计中生成包含乘数映射的合成属性的代码。您可以选择是否将特定块的乘数映射到dsp或硬件中的逻辑。
在Xilinx®目标时,生成的代码使用use_dsp属性。为阿尔特拉®目标时,生成的代码使用multstyle属性。
的DSPStyle下表列出了选项。
| DSPStyle价值 | 描述 |
|---|---|
“没有”(默认) |
禁止插入DSP映射合成属性。 |
“上” |
插入综合属性,指示综合工具映射到硬件中的DSP。 |
'离开' |
插入合成属性,指示合成工具映射到硬件中的逻辑。 |
的DSPStyle参数可用于以下块:
获得
产品
产品的元素架构设置为树
子系统
原子子系统
不同的子系统
启用子系统
触发子系统
模型将架构设置为
ModelReference.
层次结构平坦行为
如果您为也具有非默认值的子系统指定层次结构扁平化DSPStyle设置,HDL编码器传播DSPStyle设置为父子系统。
如果平坦的子系统包含获得,产品,或产品的元素块,编码器保持它们的非默认值DSPStyle设置和替换默认值DSPStyle使用扁平子系统进行设置DSPStyle设置。
在生成代码中合成属性
合成属性的生成代码取决于:
目标语言
DSPStyle价值SynthesisTool价值
下表显示了生成代码中合成属性的示例。
| DSPStyle价值 | 开发价值 | 合成池价值 | |
|---|---|---|---|
“阿尔特拉第四的二世” |
“Xilinx ISE”“Xilinx Vivado” |
||
“没有” |
'Verilog' |
|
|
'vhdl' |
|
|
|
“上” |
'Verilog' |
|
|
'vhdl' |
|
|
|
'离开' |
'Verilog' |
|
|
'vhdl' |
|
|
|
合成属性规范的需求
的方法指定一个合成工具SynthesisTool财产。
如何指定合成属性
使用HDL块属性对话框指定合成属性:
右键单击该块。
选择HDL代码>高密度脂蛋白块属性.
为DSPStyle中,选择在,从,或没有任何.
若要从命令行指定合成属性,请使用hdlset_param.例如,假设你有一个模型,my_model,带有DUT子系统,my_dut,它包含a。获得块,my_multiplier.将合成属性插入到映射中my_multiplier,输入:
hdlset_param (“my_model / my_dut / my_multiplier”,'dspstyle',“上”)
hdlset_param.
合成属性规范的限制
当指定非默认值时
DSPStyle块属性,ConstMultiplierOptimization属性必须设置为“没有”.乘法器组件的输入不能使用
双数据类型。获得常数不能是2的幂。
FlattenHierarchy
FlattenHierarchy允许您从设计生成的HDL代码中删除子系统层次结构。
| FlattenHierarchy设置 | 描述 |
|---|---|
“继承”(默认) |
使用父子系统的层次结构扁平化设置。如果这个子系统是最高级别的子系统,不要变平。 |
“上” |
平这个子系统。 |
'离开' |
不要使这个子系统变平,即使父子系统是变平的。 |
要使层次扁平化,你还必须有MaskParameterAsGeneric全局属性设置为'离开'.有关更多信息,请参见从屏蔽子系统生成参数化的HDL代码.
如何扁平化层次结构
使用HDL块属性对话框设置层级扁平化:
在应用程序选项卡上,选择HDL编码器.的HDL代码选项卡出现了。选择子系统然后点击高密度脂蛋白块属性.为FlattenHierarchy中,选择在,从,或继承.
右键单击子系统并选择HDL代码>高密度脂蛋白块属性.为FlattenHierarchy中,选择在,从,或继承.
要从命令行设置层次结构扁平化,请使用hdlset_param.例如,要打开一个子系统的层次扁平化,my_dut:
hdlset_param (“my_dut”,“FlattenHierarchy”,“上”)
hdlset_param.
层次扁平化的局限性
如果一个子系统是:
一个同步子系统或使用国家控制块在
同步模式。模型参考实现。
触发子系统的时间用触发信号作为时钟启用。
一个屏蔽子系统,包含以下任何一个:
公共汽车。
枚举数据类型。
查找表:一维查找表,二维查找表,余弦HDL优化,直接LookupTable(一天),Prelookup,正弦HDL优化,一天的查找表.
MATLAB系统块。
Stateflow块:图表,状态转换表,顺序查看器.
使用直通或无操作实现阻塞。看到直通、无HDL和级联实现.
请注意
此选项在代码生成之前移除子系统边界。它不一定生成具有完全扁平层次结构的HDL代码。
InputPipeline
InputPipeline允许您为选定的块指定带有输入管道的实现。参数值指定生成代码中输入管道阶段的数量(管道深度)。
下面的代码为模型中的每个Sum块指定了两个阶段的输入管道深度:
sblocks = find_system(gcb, 'BlockType', 'Sum'); / /指定块类型for ii=1:length(sblocks),hdlset_param(sblocks{ii},'InputPipeline', 2),结束;
请注意
的InputPipeline设置对没有输入端口的块没有任何影响。
当为管道寄存器生成代码时,HDL Coder会将后缀字符串附加到输入或输出管道寄存器的名称中。默认后缀字符串为_pipe.要自定义后缀字符串,请使用管道Postfix.选项全局设置/常规窗格中HDL代码生成配置参数对话框的窗格。或者,您可以将所需的Postfix作为字符向量传递给makehdl财产PipelinePostfix.例如,请参见管道Postfix..
InstantiateFunctions
对于MATLAB函数块,可以使用InstantiateFunctions参数生成VHDL®实体或Verilog®模块为每一个函数。HDL编码器为每一个生成代码实体或模块在一个单独的文件中。
的InstantiateFunctions选项MATLAB函数块的列表见下表。
| InstantiateFunctions设置 | 描述 |
|---|---|
'离开'(默认) |
为内联函数生成代码。 |
“上” |
生成一个硬件描述语言(VHDL) |
如何为函数生成可实例化的代码
设置InstantiateFunctions参数使用HDL块属性对话框:
右键单击MATLAB函数块。
选择HDL代码>高密度脂蛋白块属性.
为InstantiateFunctions中,选择在.
设置InstantiateFunctions来自命令行的参数,使用hdlset_param.例如,为在a中生成可实例化代码MATLAB函数块,myMatlabFcn,在DUT子系统中,myDUT,输入:
hdlset_param(“my_DUT / my_MATLABFcnBlk”、“InstantiateFunctions”,“上”)
为特定函数生成内联代码
如果您想为某些函数生成可实例化的代码,而不是其他函数,请启用为函数生成可实例化代码的选项,并使用coder.inline.看到coder.inline获取详细信息。
用于功能的可行性代码生成的限制
软件生成内联代码时:
函数调用在条件代码或
为循环。任何函数都是用非常量来调用的
结构体输入。该函数具有状态(如持久变量),并被多次调用。
在设计函数的任何地方都有一个枚举。
InstantiateStages
对于一个级联架构上,可以使用InstantiateStages参数生成VHDL实体或Verilog模块对于每个计算阶段。HDL编码器为每一个生成代码实体或模块在一个单独的文件中。
| InstantiateStages设置 | 描述 |
|---|---|
'离开'(默认) |
在单个VHDL中生成级联阶段 |
“上” |
生成一个硬件描述语言(VHDL) |
LoopOptimization
LoopOptimization控件生成的代码中允许流或展开循环MATLAB函数块。循环流优化区域;循环展开优化速度。
请注意
如果指定MATLAB Datapath公司的架构MATLAB函数块时,您只能展开循环。要流循环,您可以通过指定StreamingFactor.看到使用MATLAB数据路径架构跨MATLAB函数块边界的HDL优化.
| LoopOptimization设置 | 描述 |
|---|---|
“没有”(默认) |
不要优化循环。 |
“展开” |
展开循环。 |
“流” |
流循环。 |
如何优化MATLAB函数块For循环
使用HDL块属性对话框选择循环优化:
右键单击MATLAB函数块。
选择HDL代码>高密度脂蛋白块属性.
为LoopOptimization中,选择
没有任何,展开,或流媒体.
要从命令行中选择循环优化,请使用hdlset_param.例如,打开循环流动MATLAB函数块,my_mlfn:
hdlset_param (“my_mlfn”,“LoopOptimization”,“流”)
hdlset_param.
限制MATLAB函数块循环优化
如果:HDL编码器不能流循环:
循环索引计数。循环索引必须在每次迭代上增加1。
在另一个循环中,在同一层次结构级别上有两个或多个嵌套循环。
任何特定的持久变量都会在循环内部和外部更新。
当持久化变量为:
在循环内部更新,在循环外部读取。
在循环内读取并在循环外更新。
LUTRegisterResetType
使用LUTRegisterResetType阻止参数来控制FPGA上ROM结构的LUT综合。
| LUTRegisterResetType价值 | 描述 |
|---|---|
默认的 |
LUT输出寄存器具有默认的重置逻辑。当您生成HDL时,LUT将被合成为寄存器。 |
没有任何 |
LUT输出寄存器没有复位逻辑。当你生成HDL时,LUT将被合成为ROM。 |
您可以指定LUTRegisterResetType适用于以下类别:
伽马校正
查找表
的NCO HDL优化块忽略此参数。
MapPersistentVarsToRAM
与MapPersistentVarsToRAM的持久化数组,可以使用基于ram的映射MATLAB函数块而不是映射到寄存器。
| MapPersistentVarsToRAM设置 | 映射的行为 |
|---|---|
|
持久数组映射到生成的HDL代码中的寄存器。 |
|
持久数组变量映射到RAM。限制,请参阅内存映射的限制. |
内存映射的限制
当您启用RAM映射时,当所有以下条件都为真时,持久阵列或用户定义的系统对象™私有属性映射到块RAM:
每次读或写访问仅针对单个元素。例如,子矩阵访问和数组复制是不允许的。
地址计算逻辑不是读取的。例如,不允许使用从阵列读取的数据的读取或写入地址的计算。
如果持久化变量或用户定义的System对象私有属性具有循环依赖关系,则将它们初始化为0。例如,如果你有两个持久化变量A和B,那么如果A依赖于B, B依赖于A,那么你就有一个循环依赖关系。
如果访问权限在条件语句中,则条件语句仅使用简单的逻辑表达式(
&&,||,~)或关系操作符。例如,在下面的代码中,r1不映射到RAM:If (mod(i,2) > 0) a = r1(u);Else r1(i) = u;结束
重写复杂的条件,例如调用函数的条件,将它们赋给临时变量,并在条件语句中使用临时变量。例如,映射
r1为RAM,重写前面的代码如下:temp = mod(我,2);If (temp > 0) a = r1(u);Else r1(i) = u;结束
持久数组或用户定义的System对象私有属性值依赖于外部输入。
例如,在下面的代码中,
bigarray不映射到RAM,因为它不依赖于u:函数z = foo(u) persistent CNT bigarray if isempty(CNT) CNT = fi(0,1,16,10,hdlfimath);bigarray = uint8 (0 (1024 1));End z = u + cnt;idx = uint8(问);temp = bigarray (idx + 1);Cnt (:) = Cnt + fi(1,1,16,0,hdlfimath) + temp;bigarray (idx + 1) = idx;
RAMSize是否大于或等于RAMMappingThreshold价值。RAMSize是产品NumElements * WordLength * Complexity.NumElements是数组中元素的个数。字表示数组数据类型的位数。复杂性具有复杂基类型的阵列是2;否则1。
如果上述任何一个条件为假,则持久数组或用户定义的System对象私有属性将映射到HDL代码中的寄存器。
RAMMappingThreshold
的默认值RAMMappingThreshold是256。若要更改阈值,请使用hdlset_param.例如,使用下面的命令修改映射阈值sfir_fixed模型到128位:
hdlset_param (“sfir_fixed”,“RAMMappingThreshold”, 128);
您还可以在“配置参数”对话框中更改RAM映射阈值。有关更多信息,请参见RAM映射阈值(位)部分内存映射参数.
例子
下面的示例演示了如何将持久化数组变量映射到RAMMATLAB函数块,看RAM映射与MATLAB函数块.
MapToRAM
使用MapToRAM将查找表(LUT)映射到RAM。
当模拟内存延迟启用。,MapToRAM属性被禁用余弦HDL优化和正弦HDL优化块。
| Maptoram设置 | 映射的行为 |
“继承”(默认) |
使用父子系统的自适应管道设置。如果该子系统是最高级别的子系统,则为模型使用自适应管道设置。 |
|
块查找表(lut)被映射到FPGA上的逻辑片。 |
|
块查找表(lut)被映射到RAM。 |
OutputPipeline
OutputPipeline允许您为选定的块指定带有输出管道的实现。参数值指定生成代码中输出管道阶段的数量(管道深度)。
下面的代码为模型中的每个Sum块指定了两个阶段的输出管道深度:
sblocks = find_system(gcb, 'BlockType', 'Sum'); / /指定块类型for ii=1:length(sblocks),hdlset_param(sblocks{ii},'OutputPipeline', 2),结束;
请注意
的OutputPipeline设置对没有输出端口的块没有任何影响。
当为管道寄存器生成代码时,HDL Coder会将后缀字符串附加到输入或输出管道寄存器的名称中。默认后缀字符串为_pipe.要自定义后缀字符串,请使用管道Postfix.选项,在“配置参数”对话框中HDL代码生成>全局设置>通用选项卡。或者,您可以使用PipelinePostfix财产与makehdl.例如,请参见管道Postfix..
另请参阅MATLAB函数块的分布式管道插入.
RAMDirective
使用RAMDirective,您可以指定是否要将Simulink模型中的随机访问内存(RAM)块映射到FPGA RAM内存块。金宝app您可以映射大的内存块,例如超来自Xilinx家族和来自Quartus的M144k®家庭。在您的设计中,基于合成工具为RAM块指定这些RAMDirective值。
| 合成工具 | RAM样式属性 | RAMDirective值 |
| 第四的 | ramstyle |
|
| 赛灵思公司 | ram_style |
|
| Microsemi® | syn_ramstyle |
|
为此设置指定值时,HDL编码器会生成一个ramstyle属性。此属性指定您希望合成工具在推断设计中的RAM块时使用的RAM内存单元类型。
当您没有为该设置指定任何值时,HDL Coder不会生成ramstyle属性。合成工具确定用于映射模型中的RAM块的推断RAM的类型。
为RAM块设置RAMDirective
在HDL RAM图书馆,除了双速率双端口RAM,可以指定RAMDirective属性用于所有其他RAM块。
设置RAMDirective对于HDL块属性中的RAM块对话框:
右键单击RAM块。
选择HDL代码>高密度脂蛋白块属性.
在RAMDirective属性,指定表中列出的值。
您也可以设置RAMDirective通过使用hdlset_param函数。
RAMDirective的hdlset_param (< ram_block_name >, < attribute_value >);
在MATLAB中指定这些属性®HDL工作流,使用RAMDirective参数值对高密度脂蛋白。内存实例化。使用下面的命令设置此属性:
hRam =高密度脂蛋白。内存(‘RAMType’, ‘Single Port RAM’, ‘RAMDirective’, ‘ultra’);
例如,生成HDL属性,用于将模型中的RAM块映射到块内存.一个块内存是FPGA上的专用存储单元。块ram的大小可以是4 kb,8KB.,16 kb,32 kb.
将您的RAM块映射到块内存:
指定合成工具。必须将包含以下内容的Xilinx设备作为目标
块内存资源。如果目标设备不包含块RAM,合成工具将忽略此属性,并可能推断该RAM为分布式RAM或Lookup Table (LUT)片。输入RAMDirective值为
块为您的Simuli金宝appnk RAM块在HDL块属性。为您的模型生成HDL代码。
生成的VHDL代码显示ram_style属性设置为块:
属性ram_style:字符串;属性ram_style的ram:信号是“块”;
此生成的Verilog代码显示了ram_style属性设置为块:
(* ram_style = "block" *)
依赖
当使用RAMDirective属性,请确保为您的设计选择了合成工具。
ResetType
使用ResetType块参数抑制复位逻辑生成。
| ResetType价值 | 描述 |
|---|---|
默认的 |
生成复位逻辑。 |
没有任何 |
不要生成重置逻辑。 Reset不应用于生成的寄存器。因此,在初始阶段,当寄存器没有完全加载时,在一些示例中,会出金宝app现Simulink和生成的代码之间的不匹配。 为了避免在初始阶段的测试台错误,请确定充分加载寄存器所需的样本数量。然后,设置忽略输出数据检查(样本数)相应的选项。另请参阅忽略输出数据检查(样本数)在试验台刺激和输出参数. |
您可以指定ResetType适用于以下类别:
图表
卷积Deinterleaver
卷积的分界
延迟
延迟(DSP系统工具箱™)
一般多路复用Deinterleaver
一般多路分界
MATLAB函数
MATLAB系统
内存
利用延迟
真值表
单位延迟启用
单位延迟
MATLAB函数块中的优化逻辑复位
当你设置时ResetType来没有任何为一个MATLAB函数块,HDL编码器不会为MATLAB代码中的持久变量生成重置逻辑。
但是,如果您为块指定了其他优化,编码器可能会插入使用重置逻辑的寄存器。编码器不抑制这些寄存器的复位逻辑生成。因此,如果您设置ResetType来没有任何与其他块优化一起,您生成的代码可能在顶层有一个重置端口。
如何抑制复位逻辑生成
要使用UI抑制块的重置逻辑生成:
右键单击该块并选择HDL代码>高密度脂蛋白块属性.
为ResetType中,选择
没有任何.
要抑制重置逻辑生成,请在命令行中输入:
hdlset_param (path_to_block“ResetType”,“没有一个”)
例如,要抑制“单位延迟”块的复位逻辑生成,UnitDelay1,在一个子系统内,mySubsys,在命令行中输入:
hdlset_param(‘mySubsys / UnitDelay1’、‘ResetType’,‘没有’);
指定同步或异步重置
要指定同步或异步重置,请使用ResetType模型级参数。有关详细信息,请参见重置类型在重置设置和参数.
SerialPartition
在最小/最大块上使用此参数为串行级联架构指定分区。默认设置使用最小的分区数。
| 产生这 架构…… |
设置SerialPartition…… |
|---|---|
| 具有显式指定分区的级联串行 | (p1 p2 p3…pN):的向量N整数,N是串行分区的个数。向量的每个元素指定了对应分区的长度。向量元素的和必须等于输入数据向量的长度。vector元素的值必须按降序排列,但最后两个元素可以相等。例如,对于一个8个元素的输入,分区3 [5]或(4 2 2)是合法的,但是分区呢[2 2 2 2]或[3 2 3]在代码生成时引发错误。 |
| 具有自动优化分区的级联串行 | 0 |
这个特性也用于串行滤波器架构。有关如何配置过滤块,请参见SerialPartition.
SharingFactor
使用SharingFactor指定要映射到单个共享资源的功能等效资源的数量。默认值是0。看到资源共享.
SoftReset
使用SoftReset块参数指定是生成硬件友好的同步复位逻辑,还是生成与Simulink仿真行为匹配的本地复位逻辑。金宝app控件的此属性可用单位延迟可重调块或单位延迟启用可复位块。
| SoftReset价值 | 描述 |
|---|---|
从(默认) |
生成与Simulink模拟行为匹配的本地重置逻辑。金宝app |
在 |
为块生成同步复位逻辑。此选项生成的代码对合成来说更有效,但与Simulink模拟行为不匹配。金宝app |
什么时候SoftReset设置为'离开',则生成以下代码单位延迟可重调堵塞 :
always @(posedge clk或posedge reset) begin: Unit_Delay_Resettable_process if (reset == 1'b1) begin Unit_Delay_Resettable_zero_delay <= 1'b1;Unit_Delay_Resettable_switch_delay < = 2 'b00;end else begin if (enb) begin Unit_Delay_Resettable_zero_delay <= 1'b0;if (UDR_reset == 1'b1) begin Unit_Delay_Resettable_switch_delay <= 2'b00;end else begin Unit_Delay_Resettable_switch_delay <= In1;Unit_Delay_Resettable_1 = (UDR_reset || Unit_Delay_Resettable_zero_delay ?1 'b1: 1 'b0);assign out0 = (Unit_Delay_Resettable_1 == 1'b1 ?2 'b00: Unit_Delay_Resettable_switch_delay);
什么时候SoftReset设置为“上”,则生成以下代码单位延迟可重调堵塞 :
始终@(提出CLK或PRESEDERESERESERED)开始:UNIT_DELAY_RESETTABLE_PROCESS IF(RESET == 1'B1)开始ener_delay_resettable_reg <= 2'b00;结束否则否则如果(eNB)开始(udr_reset!= 1'b0)begin ener_delay_resettable_reg <= 2'b00;exhele else begin ener_delay_resettable_reg <= In1;结束结束结束结束分配OUT0 = UNIT_DELAY_RESETTABLE_REG;
StreamingFactor
通过时间复用串行数据路径和共享硬件资源,将并行数据路径或矢量转换为串行、标量数据路径的数量。默认值是0,它实现完全并行的数据路径。另请参阅流媒体.
UsePipelines
您可以使用此模式产品块分和互惠模式。当您将块的HDL体系结构设置为时,此属性将可用ShiftAdd.该体系结构使用非恢复除法算法,执行多次移位和相加操作来计算商。的ShiftAdd与Newton-Raphson近似方法相比,体系结构提供了更高的精度。
当你使用ShiftAdd架构上,可以使用UsePipelines实现参数,指定是使用非恢复除法的流水线实现还是非流水线实现。
| UsePipelines设置 | 映射的行为 |
|---|---|
|
使用流水线实现不恢复的换档并添加操作分和互惠块。此设置为您的设计增加了更多的延迟,但在目标FPGA设备上实现了更高的最大时钟频率。插入的管道数量与算法计算商或倒数所需的迭代次数匹配。 |
|
使用非流水线实现的不恢复班次并添加操作分和互惠块。此设置不会给您的设计增加延迟。由于除法和倒数都是资源密集型操作,为了在目标FPGA上实现更高的时钟频率,设置UsePipelines来 |
为分块和互惠块设置UsePipelines
设置UsePipelines从HDL块属性对话框获取一个子系统:
右键单击该子系统。
选择HDL代码>高密度脂蛋白块属性.
为UsePipelines中,选择在或从.
设置UsePipelines对于来自命令行的块,使用hdlset_param.例如,关闭UsePipelines为一个分块在子系统中,my_dut:
hdlset_param (“my_dut /鸿沟”,'umerpipelines','离开');
hdlset_param.
UseRAM
的UseRAM实现参数允许对块使用基于ram的映射,而不是映射到移位寄存器。
| UseRAM设置 | 映射的行为 |
|---|---|
|
延迟映射到生成的HDL代码中的移位寄存器,除了一种情况。有关详细信息,请参见流和分布式管道的影响. |
|
当以下条件为真时,延迟映射到双端口RAM块:
如果任何条件为假,延迟映射到HDL代码中的移位寄存器,除非它与其他延迟合并映射到单个RAM。有关更多信息,请参见映射多个延迟到RAM. |
控件的实现参数可用延迟块的Simulink离散库金宝app和延迟(DSP系统工具箱)块在DSP系统工具箱信号操作库中。
映射多个延迟到RAM
HDL编码器还可以将多个等长的延迟合并为一个延迟,然后将合并的延迟映射到单个RAM。这种优化提供了以下好处:
增加单个RAM的占用
共享地址生成逻辑,可最大限度地减少相同的HDL代码的重复
将延迟映射到RAM个人延迟不满足阈值
以下规则控制多个延迟是否可以合并为一个延迟:
延迟必须:
处于子系统层次结构的同一级别。
使用相同的编译样例时间。
有
UseRAM设置为在,或由流媒体或资源共享生成。有相同的
ResetType设置,不能为没有任何.
合并延迟的总字长不能超过128位。
的
RAMSize的值大于或等于RAMMappingThreshold价值。RAMSize是产品DelayLength * WordLength * VectorLength * ComplexLength.DelayLength是延迟总数。字表示合并延迟的数据类型的比特数。VectorLength为向量延迟中元素的个数。VectorLength是1对于标量延迟。ComplexLength为2表示复杂延迟;否则1。
多个延迟映射到块RAM的示例
RAMMappingThreshold下面的模型是100位。
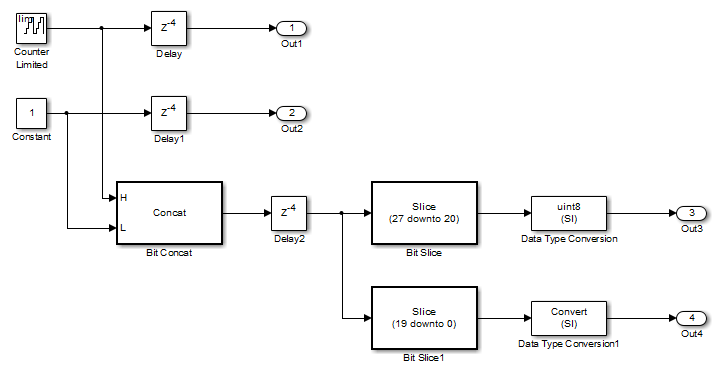
Delay和Delay1块在生成的HDL代码中合并映射为双端口RAM,满足以下条件:
两种延迟块:
都在层次结构的同一层。
使用相同的编译样例时间。
有UseRAM设置为
在在HDL块属性对话框中。有相同的ResetType设置
默认的.
合并延迟的总字长为28位,低于128位的限制。
的
RAMSize合并延迟为112位(4个延迟* 28位字长),大于映射阈值100位。
当您为这个模型生成HDL代码时,HDL Coder会生成额外的文件来指定RAM映射。编码器将这些文件存储在与其他生成的HDL文件相同的源位置,例如hdlsrc文件夹中。
流和分布式管道的影响
什么时候UseRAM是从对于延迟块,HDL编码器默认将延迟映射到移位寄存器。然而,编码器改变了UseRAM设置为在并尝试在以下条件下将延迟映射到RAM:
流媒体是启用对于子系统延迟块。
分布式流水线禁用对于子系统延迟块。
假设分布式管道是启用对于子系统延迟块。
什么时候
UseRAM是从,延迟块参与重定时。什么时候
UseRAM是在,延迟块不参与重定时。HDL编码器不破坏RAM映射标记的延迟。考虑一个有两个的子系统延迟三块,常数块,三产品块:

什么时候
UseRAM是在对于右侧的延迟块,该延迟不会参与重度。

下面的摘要描述了HDL编码器是否尝试将延迟映射到RAM而不是移位寄存器。
UseRAM延迟块的设置 |
使用延迟块为子系统启用的优化 | ||
|---|---|---|---|
| 分布式流水线只 | 只流 | 分布式流水线和流媒体 | |
| 在 | 是的 | 是的 | 是的 |
| 从 | 没有 | 是的,因为映射到RAM而不是移位寄存器可以提供一个区域高效的设计。 | 没有 |
VariablesToPipeline
警告
VariablesToPipeline不推荐。使用coder.hdl.pipeline代替。
VariablesToPipeline参数允许您在一个或多个MATLAB变量的输出处插入一个管道寄存器。将变量列表指定为字符向量,变量之间用空格分隔。
另请参阅管道MATLAB表达式.
你也可以从以下列表中选择一个网站:
