用较少的人力迭代创建标记的信号集
这个例子展示了一个迭代的基于深度学习的工作流程,以减少人类标记的工作量来标记信号。
标记信号数据是一项繁琐而昂贵的任务,需要大量人力。找到减少这种工作量的方法可以显著加快针对信号处理问题的深度学习解决方案的开发。金宝搏官方网站
考虑在信号数据集中标记感兴趣的区域的任务。第一种方法是手工标记所有数据。这种方法需要很多时间和精力。本例中探索的另一种方法迭代地处理标记过程。在每次迭代中,从未标记的数据集中选择一个信号子集,并发送到预训练的深度网络进行自动标记。人工标签人员检查生成的标签并纠正错误的标签。将经过验证的标记信号添加到训练数据集中,用扩展的训练数据重新训练深度网络。
在每次迭代中,人类标记者仍然必须访问并检查网络标记的所有信号。然而,任务从从零开始标记信号转变为纠正由可靠网络产生的不准确标签。后一项任务需要较少的人工标记工作。在每一次新的迭代中,网络使用越来越多的数据进行训练,导致网络的预测和标记性能提高。因此,在每次迭代中,纠正标签所需的人工干预越来越少。
中给出的过程使用深度学习的波形分割训练长短期记忆(LSTM)网络,该网络可以将ECG信号样本分类为属于感兴趣的三个区域之一。
数据
本例考虑使用QT数据库中公开可用的数据标记ECG信号区域[1] [2].数据包括105名患者大约15分钟的心电图记录。为了获得每个记录,检查人员将两个电极放在患者胸部的不同位置,从而产生双通道信号。数据库提供由自动化专家系统生成的信号区域标签[3.].标签对应心电测量中P波、T波、QRS复区的位置。自动专家系统对105个双通道心电信号中的每个通道进行独立标记,并对210个心电信号进行独立处理,这些信号与区域标签一起存储在210个mat文件中。文件可在以下位置索取://www.tatmou.com/金宝appsupportfiles/SPT/data/QTDatabaseECGData1.zip.
方法下载数据集download金宝appSupportFile函数。
%下载数据datasetZipFile = matlab.internal.examples.download金宝appSupportFile(“SPT”,“数据/ QTDatabaseECGData1.zip”);datasetFolder = fullfile(fileparts(datasetZipFile),“QTDataset”);如果~存在(datasetFolder“dir”)解压缩(datasetZipFile fileparts (datasetZipFile));结束
的解压缩操作创建datasetFolder文件夹中有210个mat文件。每个文件包含一个心电信号变量ecgSignal以及变量中区域标签的表signalRegionLabels.每个文件还包含信号的采样率变量Fs.在本例中,所有信号的采样率都为250hz。
创建一个信号数据存储以访问文件中的数据。属性指定要从每个文件中读取的信号变量名称SignalVariableNames参数。
sds = signalDatastore(数据目录,“SignalVariableNames”,[“ecgSignal”,“signalRegionLabels”]);
方法时,数据存储返回一个双元素单元格数组,其中包含一个心电信号和一个区域标签表读函数。使用预览函数可以看到,第一个文件的内容是一个225,000个样本长的心电信号和一个包含3385个区域标签的表。
数据=预览(sds)
data =2×1单元格数组{225000×1 double} {3385×2 table}
查看区域标签表的前几行,观察每一行都包含区域限制索引和区域类值(P、T或QRS)。
{2}(数据)
ROILimits值__________ _____ 83 117 P 130 153 QRS 201 246 T 285 319 P 332 357 QRS 412 457 T 477 507 P 524 547 QRS
将前1000个样本的标签可视化signalMask对象。
MGroundTruth = signalMask(数据{2});plotsigroi (MGroundTruth、数据{1}(1:1000))

将感兴趣的区域标签转换为分类序列,以便能够训练深度网络来执行序列到序列的分类。使用变换当从磁盘读取信号数据时,数据存储应用转换的功能。
numFiles = nummel (sds.Files);SDS = transform(SDS,@getmask);
调整信号和标签的大小(分裂),以获得长度为5000个样本的多个片段,并使用傅里叶同步压缩变换(FSST)将每个ECG片段转换到时频域。
sds = transform(sds,@ resizadata);sdsFSST = transform(sds,@(x,fs)extractFSSTFeatures(x,250));
将70%的文件用于培训,30%用于测试。打乱数据集,以便随机选择训练和测试信号。
rng默认的[trainIdx,~, testdx] = dividerand(numFiles,0.7,0,0.3);trainDs =子集(sds,trainIdx);%调整5000个样本信号和标签trainDsFSST =子集(sdsFSST,trainIdx);% fsst转换的信号和标签testDsFSST =子集(sdsFSST, testdx);
使用数据存储的readall方法将所有数据读入内存。该操作将读取每个ECG信号,并应用上述所有转换来返回多个傅里叶同步压缩转换的ECG片段。使用UseParallel选项,以使用计算机中可用的处理器并行转换数据集,只要您有并行计算工具箱™。
获取fsst转换信号ecgFSSTData = readall(trainDsFSST,UseParallel=true);
使用“本地”配置文件启动并行池(parpool)…连接到并行池(工人数:8)。
testFSSTData = readall(testDsFSST,UseParallel=true);ecgFSST = ecgFSSTData(:,1);ecgLabels = ecgFSSTData(:,2);testECGFSST = testFSSTData(:,1);testLabels = testFSSTData(:,2);得到时域信号段,以便绘制一些标记结果ecgData = readall(训练);ecgSignals = ecgData(:,1);
这个例子表明,通过迭代训练深度网络,可以减少信号标记中涉及的人力。在每次迭代中:
网络使用先前标记的帧标记未标记数据帧的子集。
人工贴标员手动纠正任何贴标错误。
修正后的标记被添加到先前标记的帧中。
扩展的标记信号集用于训练下一次迭代的网络。
为了进行定量比较,模拟两种情况:
对于基线场景,其中一个人从头开始标记整个数据集,使用完整的标记训练网络
ecgFrames集。对于第二个场景,假设
ecgFrames数据是未标记的,使用迭代方法标记它
全标记心电数据集的预测性能
建立一个BiLSTM网络,并对其进行全标记训练ecgFrames设置以获得预测性能上限。如上所述,这种方法需要对整个数据集进行蛮力标记,因此需要最大的人工标记工作。用标记的训练网络ecgFrames在测试数据集上设置并计算预测精度。
网络体系结构
使用深度学习层创建一个BiLSTM网络。
指定一个
sequenceInputLayer大小为信号的FSST中的特征数量,即频域样本的总数(本例中为40)。指定一个
bilstmLayer200个隐藏节点,并设置OutputMode来序列因为每个信号样本都有一个标签。指定一个
fullyConnectedLayer输出大小为4,分别对应P波、QRS复波、T波、N/A四类。添加一个
softmaxLayer和一个classificationLayer输出估计的标签。
%使用完全模拟的未标记数据集进行训练层= [...sequenceInputLayer(大小(ecgFSST {1}, 1)) bilstmLayer(200年“OutputMode”,“序列”) fullyConnectedLayer(4) softmaxLayer classificationLayer];
使用traningOptions指定优化求解器和训练网络的超参数。本例使用ADAM优化器和一个小批处理大小为50。使用CPU或GPU训练网络。使用GPU需要并行计算工具箱™。要查看支持哪些gpu,请参见金宝appGPU计算要求(并行计算工具箱).有关其他参数的信息,请参见trainingOptions(深度学习工具箱).本例使用GPU进行训练,使用'ExecutionEnvironment'名-值对。
选项= trainingOptions(“亚当”,...“MaxEpochs”10...“MiniBatchSize”, 50岁,...“ExecutionEnvironment”,“图形”,...“InitialLearnRate”, 0.01,...“LearnRateDropPeriod”6...“LearnRateSchedule”,“分段”,...“GradientThreshold”, 1...“洗牌”,“every-epoch”,...“阴谋”,“训练进步”,...“详细”0,...“DispatchInBackground”,真正的);
用完全标记的训练网络ecgFrames数据集。
baselineNet = trainNetwork(ecgFSST,ecgLabels,layers,options);

使用训练好的网络对测试帧进行分类,并计算平均预测精度。基线预测准确率约为90%。
predictLabelsAll =分类(baselineNet,testECGFSST,“MiniBatchSize”, 50);accuracyAll = mean(cellfun(@(x,y)mean(x==y),predictLabelsAll,testLabels));流('基线预测精度为%2.1f%%.\n', accuracyAll * 100);
基线预测准确率为89.9%。
迭代标记与人在循环
为了减少标记工作,可以尝试一种迭代方法:假设ecgFrames数据集最初是未标记的,数据是手动标记的。实际上,该示例使用数据集提供的ground truth标签。
训练初始网络
开始时,从ecgFrames手动设置并标记它们。用这个初始标记集训练一个BiLSTM网络,作为迭代过程的初始步骤。
numInitFrames = 25;currentTrainingSet = ecgFSST(1:numInitFrames,1);currentTrainingLabels = ecgLabels(1:numInitFrames);
将训练选项设置为拥有更多的训练周期和更小的迷你批大小,因为初始训练数据集中只有25帧。
选项= trainingOptions(“亚当”,...“MaxEpochs”, 20岁,...“MiniBatchSize”5,...“ExecutionEnvironment”,“图形”,...“InitialLearnRate”, 0.01,...“LearnRateDropPeriod”6...“LearnRateSchedule”,“分段”,...“GradientThreshold”, 1...“洗牌”,“every-epoch”,...“阴谋”,“没有”,...“详细”0,...“DispatchInBackground”,真正的);
使用初始训练数据集训练BiLSTM网络,并使用用于建立性能基线的相同测试数据集预测标签。该初始网络的预测准确率在40%左右。
initNet = trainNetwork(currentTrainingSet,currentTrainingLabels,layers,options);initPrediction =分类(initNet,testECGFSST,“MiniBatchSize”, 50);initAccuracy = mean(cellfun(@(x,y)mean(x==y),initPrediction,testLabels));流('预测精度为%2.1f%%.\n', initAccuracy * 100);
预测精度为43.7%。
标签
在下一步中,选择200个新的数据帧ecgFrames将它们设置并输入预先训练好的网络,initNet,以自动标记信号。
迭代= 1;%每次迭代要标记的帧数numFrames = 200;选择下一组要标记的帧indexNext = numInitFrames+1:numInitFrames+numFrames;使用分类来标记新帧当前预测=分类(initNet,ecgFSST(indexNext),“MiniBatchSize”, 50);
评估网络生成的标记结果,并将其与地面真相进行比较。找出在这个网络下心电信号的最佳和最差表现的指标。
errs = cellfun(@(x,y)sum(x~=y),ecgLabels(indexNext),currentPrediction);[~,bestIndex] = min(errs);[~,worstIndex] = max(errs);
在最好的情况下,绘制前750个样本,这些样本覆盖了ground-truth标签和网络预测的标签。
ecgSignalOfInterest = ecgSignals{indexNext(bestIndex)};groundTruthLabels = ecgLabels{indexNext(bestIndex)};predictedLabels = currentPrediction{bestIndex};MGroundTruth = signalMask(groundTruthLabels);图plotsigroi(MGroundTruth,ecgSignalOfInterest(1:50 50))“真相——最好的情况”)

mexpected = signalMask(predictedLabels);图plotsigroi(mexpected,ecgSignalOfInterest(1:50 50))“按网络标注-最好的情况”)

网络很好地标记了这个框架。因此,一个检查网络结果的人可以很容易地纠正预测的标签。
然而,在某些情况下,网络的标记性能没有那么强。绘制在最坏情况下获得的结果。
ecgSignalOfInterest = ecgSignals{indexNext(worstIndex)};groundTruthLabels = ecgLabels{indexNext(worstIndex)};predictedLabels = currentPrediction{worstIndex};MGroundTruth = signalMask(groundTruthLabels);图plotsigroi(MGroundTruth,ecgSignalOfInterest(1:50 50))“真相——最坏的情况”)

mexpected = signalMask(predictedLabels);图plotsigroi(mexpected,ecgSignalOfInterest(1:50 50))“网络标签-最坏的情况”)

网络在这个信号上的性能不是很好。在这种情况下,人工标注人员必须对预测的标签进行多次修正。
为了量化200个数据帧的校正工作,计算网络的标记错误率和每帧必须由人工标记人员校正的平均样本数量。
numSamplesPerFrame = 5000;networkLabelingErrorRate(迭代)= 1-mean(cellfun(@(x,y)mean(x==y),currentPrediction,ecgLabels(indexNext)));averageNumOfCorrectionsPerFrame(迭代)= networkLabelingErrorRate(迭代)* numSamplesPerFrame;流('每帧的平均修正数是%2.1f.\n'averageNumOfCorrectionsPerFrame(迭代));
平均每帧修正数为2211.3。
对于第一次迭代,平均每帧大约有2200个样本必须由人工校正。每帧校正样本是一个方便的度量来显示人类的努力。但请注意,在实际操作中,人工贴标员不必校正每个样品的标签。相反,人工标记人员只需扩展或缩短区域限制。
在第一次迭代结束时,人工将检查200帧并修改带有错误值的标签。在网络和人工标签器的帮助下,数据帧在迭代结束时具有正确的标签。
在下一次迭代中,200个新标记的帧可以添加到currentTrainingSet设置为重新训练网络并重复标记迭代。这个图表说明了在第一次迭代之后的每个迭代中的工作流程:

重复标记迭代
通过添加新校正的标记帧来扩展训练集,再选择200个数据帧进行标记,重复标记迭代,直到性能满意为止。
包括初始训练集和200个新标记的数据帧maxIter = 15;indexTraining = 1:numInitFrames+numFrames;networkAccuracy = 0 (1,15);networkAccuracy(迭代)= initAccuracy;选项= trainingOptions(“亚当”,...“MaxEpochs”, 20岁,...“MiniBatchSize”, 50岁,...“ExecutionEnvironment”,“图形”,...“InitialLearnRate”, 0.01,...“LearnRateDropPeriod”6...“LearnRateSchedule”,“分段”,...“GradientThreshold”, 1...“洗牌”,“every-epoch”,...“阴谋”,“没有”,...“详细”, 0);为iteration = 2:maxIter%扩展训练数据集currentTrainingSet = ecgFSST(indexTraining,1);通过将基本真理标签分配给对象来模拟人类纠正扩展训练集%currentTrainingLabels = ecgLabels(indexTraining);使用扩展训练集训练网络currentNet = trainNetwork(currentTrainingSet,currentTrainingLabels,layers,options);为测试数据集预测标签,并计算精度为%与基线性能进行比较currentTestSetPrediction = category (currentNet,testECGFSST,“MiniBatchSize”, 50);networkAccuracy(迭代)= mean(cellfun(@(x,y)mean(x==y),currentTestSetPrediction,testLabels));为人工标签器获取另一个numFrames数据帧indexNext = indexTraining(end)+1:indexTraining(end)+numFrames;在此迭代中测量每帧人工修正的平均数量current预测=分类(currentNet,ecgFSST(indexNext),“MiniBatchSize”, 50);networkLabelingErrorRate(迭代)= 1-mean(cellfun(@(x,y)mean(x==y),currentPrediction,ecgLabels(indexNext)));averageNumOfCorrectionsPerFrame(迭代)= networkLabelingErrorRate(迭代)* numSamplesPerFrame;indexTraining = 1:indexNext(end);结束
标签的性能
经过15次标记迭代,总共有2825个数据帧currentTrainingSet,对应于6543个数据帧中所包含的完整数据帧的一半左右ecgDataset集。用2825帧训练的网络的预测精度已经非常接近基线精度。
accuDiff = accuracyAll-networkAccuracy(end);流('精度差为%2.1f%%.\n', accuDiff * 100);
精度差为2.1%。
在每次迭代中,绘制测试数据集相对于训练数据集大小的网络预测精度。显示用完全标记的数据集获得的精度的上限。随着越来越多的数据帧被验证,网络的预测精度提高。
figure examinedDataSize = 25:200:2825;情节(examinedDataSize networkAccuracy,“* - - - - - -”)举行在%预测精度上限情节(examinedDataSize (15) * accuracyAll,“r——”网格)在包含(“训练集大小”)标题(“测试数据集的准确性”xlim([25 2825])“标签网络”,“上界”,“位置”,“东南”)

随着迭代的进行,每帧人工修正的平均数量随着训练数据集的增加而减少。随着更多的数据帧被验证并用于训练网络,更正所选帧的标签所需的人力就更少了。
图绘制(examinedDataSize averageNumOfCorrectionsPerFrame,“* - - - - - -”网格)在包含(“训练集大小”)标题(“每帧人工修正的平均数量”) xlim([25 2825])
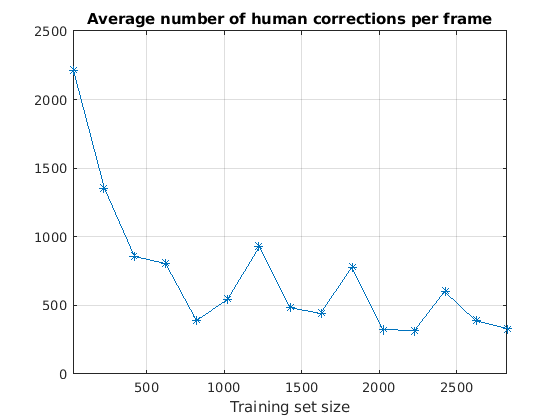
在所有15次标记迭代中,平均每帧约有700个信号样本需要人工校正。如前所述,在实践中,人类通过扩展或缩短区域限制而不是通过更改单个示例标签来更正标记的区域。
流('每帧的平均修正数是%2.1f.\n'意思是(averageNumOfCorrectionsPerFrame));
平均每帧修正数为716.9。
结论
这个例子表明,仅标记一半的ECG数据集允许深度网络实现与使用完全标记的数据集训练时相同的网络所达到的预测精度相似。通过提出的迭代标记工作流程,人工标记人员只需要查看一半的数据集,并平均每帧校正700个信号样本。另一方面,强力标记需要查看数据集中的每一帧,并从零开始标记其所有样本。
参考文献
Goldberger, Ary L., Luis A. N. Amaral, Leon Glass, Jeffery M. Hausdorff, Plamen Ch. Ivanov, Roger G. Mark, Joseph E. Mietus, George B. Moody,彭仲康和H. Eugene Stanley。“PhysioBank, PhysioToolkit,和PhysioNet:复杂生理信号新研究资源的组成部分。”循环。卷101,第23期,2000年,第e215-e220页。[流通电子页;http://circ.ahajournals.org/content/101/23/e215.full]。
[2]拉古纳、巴勃罗、罗杰·g·马克、阿里·l·戈德伯格和乔治·b·穆迪。心电图QT和其他波形间隔测量算法评估数据库心脏病学中的计算机。Vol.24, 1997, pp. 673-676。
[3]拉古纳,巴勃罗,雷蒙Jané,和Pere Caminal。多导联心电信号中波边界的自动检测:CSE数据库的验证计算机和生物医学研究。第27卷第1期,1994年,第45-60页。
另请参阅
您也可以从以下列表中选择一个网站: