ClassificationSVM
金宝app支持向量机(SVM)用于一类和二值分类
描述
ClassificationSVM是一个金宝app支持向量机(SVM)分类器为一个班和两个班的学习。训练有素的ClassificationSVM分类器存储训练数据、参数值、先验概率、支持向量和算法实现信息。金宝app使用这些分类器来执行一些任务,例如拟合一个分数到后验概率的转换函数(见fitPosterior)和预测新数据的标签(见预测).
创建
创建一个ClassificationSVM对象的使用fitcsvm.
属性
对象的功能
紧凑的 |
减少机器学习模型的规模 |
compareHoldout |
使用新数据比较两种分类模型的准确度 |
crossval |
交叉验证机器学习模型 |
discard金宝appSupportVectors |
丢弃线性支持向量金宝app机分类器的支持向量 |
边缘 |
为支持向量机分类器寻找分类边缘金宝app |
fitPosterior |
拟合支持向量机分类器的后验概率金宝app |
incrementalLearner |
将二值分类支持向量机模型转换为增量学习器金宝app |
损失 |
查找支持向量机分类器的分类错误金宝app |
保证金 |
为支持向量机(SVM)分类器寻找分类边界金宝app |
partialDependence |
计算部分依赖 |
plotPartialDependence |
创建部分依赖图(PDP)和个人条件期望图(ICE) |
预测 |
使用支持向量机分类器对观测数据进行分类金宝app |
resubEdge |
Resubstitution分类边缘 |
石灰 |
局部可解释的模型不可知解释(LIME) |
resubLoss |
Resubstitution分类损失 |
再精 |
Resubstitution分类保证金 |
resubPredict |
使用训练的分类器对训练数据进行分类 |
的简历 |
恢复训练支持向量机分类器金宝app |
沙普利 |
沙普利值 |
testckfold |
通过重复交叉验证比较两种分类模型的准确率 |
例子
训练支持向量机分类器
载入费雪的虹膜数据集。去掉萼片的长度和宽度以及所有观察到的刚毛鸢尾。
负载fisheriris第1 = ~ strcmp(物种,“setosa”);X =量(第1 3:4);y =物种(第1);
使用处理后的数据集训练支持向量机分类器。
SVMModel = fitcsvm (X, y)
SVMModel=ClassificationSVM ResponseName:'Y'分类预测值:[]类名:{'versicolor''virginica'}ScoreTransform:'none'numobervations:100 Alpha:[24x1 double]偏差:-14.4149内核参数:[1x1结构]框约束:[100x1 double]收敛信息:[1x1结构]IsupportVector:[100x1逻辑]解算器:“SMO”属性、方法金宝app
SVMModel是一个培训ClassificationSVM分类器。显示的属性SVMModel.例如,要确定类的顺序,可以使用点符号。
classOrder = SVMModel。一会
classOrder =2 x1细胞{“癣”}{' virginica '}
第一节课(“多色的”)是否定类,而第二个(“virginica”)是积极类。属性可以在训练期间更改类的顺序“类名”名称-值对的论点。
绘制数据的散点图,并圈出支持向量。金宝app
sv = SVMModel.金宝appSupportVectors;图gscatter (X (: 1), (:, 2), y)在情节(sv (: 1), sv (:, 2),“柯”,“MarkerSize”(10)图例(“多色的”,“virginica”,“金宝app支持向量”)举行从
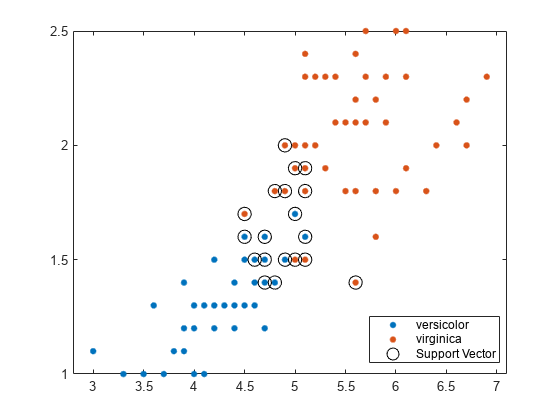
支持向量金宝app是发生在或超出其估计的类边界上的观察结果。
通过在训练期间使用金宝app“BoxConstraint”名称-值对的论点。
训练和交叉验证SVM分类器
加载电离层数据集。
负载电离层
训练并交叉验证SVM分类器。标准化预测数据并指定类的顺序。
rng(1);%的再现性CVSVMModel = fitcsvm (X, Y,“标准化”,真的,...“类名”,{“b”,‘g’},“CrossVal”,“上”)
CVSVMModel = ClassificationPartitionedModel CrossValidatedModel: 'SVM' PredictorNames: {1x34 cell} ResponseName: 'Y' NumObservations: 351 KFold: 10 Partition: [1x1 cvpartition] ClassNames: {'b' ' 'g'} ScoreTransform: 'none'属性,方法
CVSVMModel是一个ClassificationPartitionedModel旨在支持向量机分类器。默认情况下,该软件实现10倍交叉验证。
或者,您可以交叉验证一个经过培训的ClassificationSVM将它传递给crossval.
使用点符号检查一个训练过的折叠。
CVSVMModel。训练有素的{1}
ans = CompactClassificationSVM ResponseName: 'Y' CategoricalPredictors: [] ClassNames: {'b' ' 'g'} ScoreTransform: 'none' Alpha: [78x1 double] Bias: -0.2209 KernelParameters: [1x1 struct] Mu: [1x34 double] Sigma: [1x34 double金宝app] SupportVectors: [78x34 double] SupportVectorLabels: [78x1 double]属性,方法
每条折线都是CompactClassificationSVM分类器对90%的数据进行训练。
估计泛化误差。
genError = kfoldLoss (CVSVMModel)
genError = 0.1168
平均而言,泛化误差约为12%。
更多关于
算法
支持向量机二值分类算法的数学公式见金宝app支持向量机的二进制分类和理解支持向量机金宝app.
南,<定义>,空字符向量(''),空字符串(""),fitcsvm删除与缺失响应相对应的整行数据。计算总权重时(请参阅下一个项目符号),fitcsvm忽略与至少缺少一个预测因子的观测相对应的任何权重。在平衡类问题中,这种行为会导致不平衡的先验概率。因此,观察框约束可能不相等箱约束.fitcsvm删除权重为零或先验概率为零的观察值。对于两类学习,如果你指定代价矩阵 (见
成本),然后软件更新类先验概率p(见之前)pc通过将处罚纳入 .明确地
fitcsvm完成这些步骤:计算
正常化pc*更新后的先验概率和是1。
K为类数。
将成本矩阵重置为默认值
从零先验概率类对应的训练数据中去除观测值。
对两种学习,
fitcsvm规范化所有观察权重(请参见权重)求和为1。然后,该函数对归一化权重进行重归一化,使其总和为观测所属类的更新先验概率。即观察的总权重j在课堂上k是wj是标准化的观测权值吗j;pc,k更新的类先验概率是多少k(见以前的子弹)。
对两种学习,
fitcsvm为训练数据中的每个观测值指定一个方框约束。观察框约束的公式j是n为训练样本量,C0初始框约束(参见
“BoxConstraint”名称-值对参数)和 观察的总权重是多少j(见以前的子弹)。如果你设置
“标准化”,真的和“成本”,“先前的”,或“重量”名称-值对参数fitcsvm使用相应的加权平均值和加权标准差对预测进行标准化。也就是说,fitcsvm标准化预测j(xj)使用xjk是观察k(行)的预测j(列)。
假设
p是你在训练数据中期望的和你设置的异常值的比例吗OutlierFraction, p.对于单班学习,软件训练的偏差项为100
p%的观察在训练数据中有负的分数。该软件实现了稳健学习两级学习。换句话说,该软件试图删除100个
p%的观测值时,优化算法收敛。被移走的观测值对应的是幅度很大的梯度。
如果你的预测数据包含分类变量,那么软件通常对这些变量使用完全哑编码。该软件为每个类别变量的每一级创建一个虚拟变量。
的
预测器名称属性为每个原始预测器变量名存储一个元素。例如,假设有三个预测因子,其中一个是具有三个层次的分类变量。然后预测器名称是包含预测变量原始名称的字符向量的1 × 3单元格数组。的
扩展预测器名称属性存储每个预测变量的一个元素,包括虚拟变量。例如,假设有三个预测因子,其中一个是具有三个层次的分类变量。然后扩展预测器名称是一个包含预测变量和新的虚拟变量名称的字符向量的1 × 5单元格数组。类似地,
β属性存储每个预测器(包括虚拟变量)的一个beta系数。的
金宝appSupportVectors属性存储支持向量的预测值,包括虚拟变量。金宝app例如,假设有米金宝app支持向量和三个预测因子,其中一个是三级分类变量金宝appSupportVectors是一个n5矩阵。的
X属性将训练数据存储为原始输入,不包含虚拟变量。当输入是一个表时,X只包含用作预测器的列。
对于表中指定的预测器,如果任何变量包含有序(有序)类别,该软件对这些变量使用有序编码。
的变量k软件创建了有序的关卡k- 1虚拟变量。的j第一个哑变量为1对于级别高达j,+1的水平j+ 1通过k.
中的虚拟变量的名称
扩展预测器名称属性指示具有该值的第一级+1这个年代的tware storesk- 1虚拟变量的附加预测器名称,包括级别2、3、…k.
所有连接器实现l1 soft-margin最小化。
对于单类学习,软件估计拉格朗日乘数,α1,...,αn,这样
工具书类
Hastie, T., R. Tibshirani, J. Friedman。统计学习的要素,第二版。纽约:施普林格,2008年。
Scholkopf, B., J. C. Platt, J. C. shaw - taylor, A. J. Smola, R. C. Williamson。"估算高维分布的支持度"金宝app神经第一版., Vol. 13, no . 7, 2001, pp. 1443-1471。
克里斯汀尼尼,N。c。肖-泰勒。支持向量机和其他基于核的学习方法简介金宝app.英国剑桥:剑桥大学出版社,2000年。
[4] Scholkopf, B.和A. Smola。核学习:支持向量机,正则化,优化和超越,自适应金宝app计算和机器学习。麻省理工学院出版社,2002年。
扩展功能
你也可以从以下列表中选择一个网站:
