比较多重分布拟合
这个例子展示了如何将多个概率分布对象拟合到同一组样本数据,并获得每个分布拟合数据的程度的可视化比较。
步骤1。加载示例数据。
加载示例数据。
负载carsmall
这个数据包括每加仑行驶的英里数(英里/加仑)按原产国分类的不同汽车制造商和型号的测量值(起源)、模型年(Model_Year)和其他车辆特性。
步骤2。创建分类数组。
变换起源并从样本数据中删除意大利汽车。因为只有一辆意大利车,fitdist不能使用内核发行版以外的发行版来适应该组。
起源=分类(cellstr(起源));MPG2 = MPG(原点~ =“意大利”);Origin2 =来源(来源~ =“意大利”);Origin2 = removecats (Origin2,“意大利”);
步骤3。按组拟合多个分布。
使用fitdist以适应Weibull,正常,逻辑,和内核分布到每个国家的起源组英里/加仑数据。
[WeiByOrig、国家]= fitdist (MPG2“威布尔”,“通过”, Origin2);[NormByOrig、国家]= fitdist (MPG2“正常”,“通过”, Origin2);[LogByOrig、国家]= fitdist (MPG2“物流”,“通过”, Origin2);[KerByOrig、国家]= fitdist (MPG2“内核”,“通过”, Origin2);
WeiByOrig
WeiByOrig =1×5单元阵列列1到2 {1x1 probb。WeibullDistribution}{1x1 prob.WeibullDistribution} Columns 3 through 4 {1x1 prob.WeibullDistribution} {1x1 prob.WeibullDistribution} Column 5 {1x1 prob.WeibullDistribution}
国家
国家=5 x1细胞{“法国”}{“德国”}{‘日本’}{“瑞典”}{'美国'}
每个国家组现在有四个与之相关的分布对象。例如,单元格数组WeiByOrig包含5个Weibull分布对象,每个对象对应示例数据中表示的每个国家。同样,单元格数组NormByOrig包含5个正态分布对象,以此类推。每个对象都包含包含有关数据、分布和参数的信息的属性。数组国家按分布对象存储在单元格数组中的相同顺序列出每个组的原产国。
步骤4。计算每个分发版的pdf。
提取美国的四个概率分布对象,并计算每个分布的pdf。如步骤3所示,USA位于每个单元阵列的位置5。
WeiUSA = WeiByOrig {5};NormUSA = NormByOrig {5};LogUSA = LogByOrig {5};KerUSA = KerByOrig {5};x = 0:1:50;pdf_Wei = pdf (WeiUSA x);pdf_Norm = pdf (NormUSA x);pdf_Log = pdf (LogUSA x);pdf_Ker = pdf (KerUSA x);
第5步。为每个发行版绘制pdf。
绘制每个适合美国数据的分布的pdf,叠加在样本数据的直方图上。规格化直方图更容易显示。
创建美国样本数据的直方图。
data = MPG (Origin2 = =“美国”);图直方图(数据、10“归一化”,“pdf”,“FaceColor”, 1, 0.8, 0);
绘制每个配套件的pdf文件。
线(x, pdf_Wei“线型”,“- - -”,“颜色”,“r”)线(x, pdf_Norm“线型”,“-”。,“颜色”,“b”)线(x, pdf_Log“线型”,“——”,“颜色”,‘g’)线(x, pdf_Ker“线型”,“:”,“颜色”,“k”)传说(“数据”,“威布尔”,“正常”,“物流”,“内核”,“位置”,“最佳”)标题(“来自美国的汽车的MPG”)包含(“英里”)
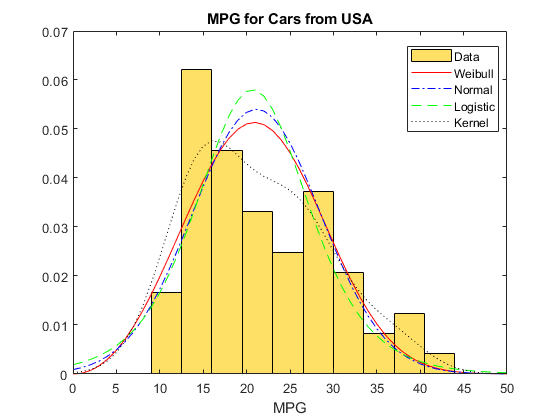
将pdf图叠加到样本数据的直方图上,可以直观地比较每种类型的分布与数据的吻合程度。只有非参数核分布KerUSA接近于揭示原始数据中的两种模式。
步骤6。进一步分组美国数据按年。
为了研究步骤5中显示的两种模式,将英里/加仑按原产国分列的资料(起源)及型号年(Model_Year),用fitdist使内核分布适合每一组。
[KerByYearOrig,名称]= fitdist(英里/加仑,“内核”,“通过”,{起源Model_Year});
每个起源和模型年份的独特组合现在都有一个与之相关联的内核分布对象。
的名字
名称=14 x1细胞{“法国…'}{“法国…'}{'Germany...'} {'Germany...'} {'Germany...'} {'Italy...' } {'Japan...' } {'Japan...' } {'Japan...' } {'Sweden...' } {'Sweden...' } {'USA...' } {'USA...' } {'USA...' }
绘制每个美国模型年的三个概率分布,它们位于单元阵列的第12、13和14位KerByYearOrig.
图保存在为图(x,pdf(kerbyyearorigin {i},x))结束传奇(“1970”,“1976”,“1982”)标题(“美国汽车各车型的MPG”)包含(“英里”)举行从
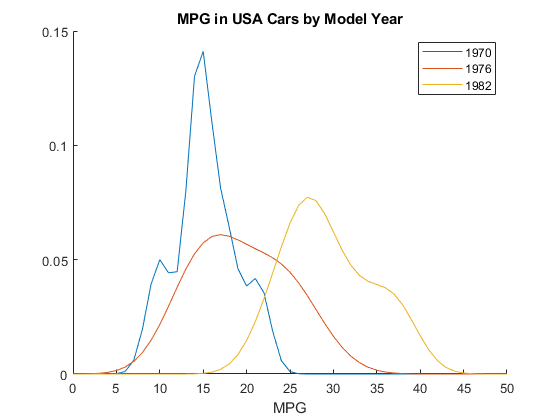
当进一步按模式年分组时,pdf图显示了两个不同的峰值英里/加仑美国产汽车的数据——一个是车型年1970,一个是车型年1982。这就解释了为什么美国每加仑行驶里程合计的直方图显示了两个峰值而不是一个。
另请参阅
相关的话题
你也可以从以下列表中选择一个网站:
