定点代码生成SVM预测
此示例显示如何为支持向量机(SVM)模型的预测生成定点C / C ++代码。金宝app与通用C / C ++代码生成工作流相比,固定点代码生成需要一个附加步骤,该步骤定义预测所需的变量的定点数据类型。通过使用创建固定点数据类型结构generatelearnerdatatypefcn.,并使用该结构作为输入参数loadLearnerForCoder在一个入学点函数中。您还可以在生成代码之前优化固定点数据类型。
该流程图显示了定点代码生成工作流。

训练SVM模型。
通过使用保存训练的模型
Savelarnerforcoder..通过使用由生成的数据类型函数定义预测所需的变量的定点数据类型
generatelearnerdatatypefcn..定义一个入口点函数加载模型同时使用
loadLearnerForCoder和结构,然后调用预测函数。(可选的)优化的定点数据的类型。
生成定点C/ c++代码。
验证生成的代码。
第5步是可选的步骤,以改善所产生的定点代码的性能。要做到这一点,重复这两个步骤,直到您满意的代码性能:
通过使用用于预测的变量的记录的最小值和最大值
buildInstrumentedMex(定点设计师).使用仪器使用
showInstrumentationResults(定点设计师).然后,调优定点数据类型(如果必要的话),以防止溢出和下流,并提高定点代码的精度。
在此工作流程中,您可以使用从中生成的数据类型函数来定义固定点数据类型generatelearnerdatatypefcn..从算法中分离变量的数据类型使测试更简单。您可以通过使用数据类型函数的输入参数以编程方式在浮点和定点之间进行编程数据类型。此外,此工作流程兼容手动固定点转换工作流程(定点设计师).
数据预处理
加载人口普查1994.数据集。该数据集包括来自美国人口普查局的人口统计数据,用于预测个人每年赚50,000美元。
加载人口普查1994.
考虑一个模型,预测员工的薪酬类别,鉴于其年龄,工人阶级,教育水平,资本收益和损失以及每周工作时间的数量。提取感兴趣的变量并使用表保存它们。
台= adultdata (:, {'年龄',“education_num”,“capital_gain”,'capital_loss','每周几小时'});
打印表的摘要。
摘要(TBL)
变量:年龄:32561 x1双重价值:17分钟37 Max 90 education_num中位数:32561 x1双重价值:1分钟10马克斯16 capital_gain中位数:32561 x1双重价值:最小值0最大99999 capital_loss: 32561 x1双重价值:最小值0最大4356 hours_per_week: 32561 x1双重价值:最小值40 Max 99
变量的比例是不一致的。在这种情况下,您可以使用标准化数据集训练模型,方法是指定'标准化'名称 - 值对参数fitcsvm.然而,添加的操作标准化到定点代码可以降低精度和提高内存的使用。相反,你可以手动标准化的数据集,如本例所示。这个例子也说明了如何检查在最后的内存使用。
固定点代码生成不支持表或分类阵列。金宝app所以,定义预测器数据X使用数字矩阵,并定义类标签Y使用逻辑向量。逻辑向量在二进制分类问题中最有效地使用内存。
X = table2array(TBL);Y = adultdata.salary =='<= 50K';
定义观测权值w.
w = adultdata.fnlwgt;
存储器使用的作为支持向量的模型中的增加数目的训练的模型增加。金宝app为了减少支持向量的数量,可以增加箱约束使用训练的金宝app时候'boxconstraint'名称 - 值对参数或使用用于培训的分布代表数据。请注意,增加框约束可以导致较长的训练时间,并且使用限制数据集可以降低训练模型的准确性。在此示例中,您可以从数据集中随机示例,并使用用于训练的限制数据。
rng (“默认”)%的再现性[x_sampled,idx] = datasample(x,1000,'代替',错误的);y_sampled = y(idx);w_sampled = w(idx);
查找使用训练模型的加权平均值和标准偏差'重量'和'标准化'名称值对参数。
tempmdl = fitcsvm(x_sampled,y_sampled,'重量'w_sampled,'骨箱','高斯','标准化',真正的);亩= tempMdl.Mu;差= tempMdl.Sigma;
如果你不使用“成本”,“之前”, 或者'重量'的名称-值对参数,然后可以通过使用ZScore.函数。
[标准化x_sampled,mu,sigma] = zscore(x_sampled);
通过使用标准化预测器数据亩和σ.
standardizedX =(X-MU)./西格玛;standardizedX_sampled = standardizedX(IDX,:);
您可以使用测试数据集来验证训练的模型和测试仪器化MEX功能。指定测试数据集,并通过使用标准化测试预测数据亩和σ.
xtest = table2array(AdutherTest(:,{'年龄',“education_num”,“capital_gain”,'capital_loss','每周几小时'}));standardizedXTest = (XTest-mu)。/σ;欧美=成人。工资= ='<= 50K';
火车模型
训练二元SVM分类模型。
MDL = fitcsvm(standardizedX_sampled,Y_sampled,'重量'w_sampled,'骨箱','高斯');
MDL.是A.ClassificationSVM模型。
计算培训数据集的分类错误和测试数据集。
损失(MDL,标准化x_sampled,y_sampled)
ans = 0.1663
损失(MDL,标准化标准,ytest)
ans = 0.1905.
SVM分类器错误分类约17%的培训数据和19%的测试数据。
保存模型
将SVM分类模型保存到文件中myMdl.mat通过使用Savelarnerforcoder..
saveLearnerForCoder (Mdl“myMdl”);
定义固定点数据类型
用generatelearnerdatatypefcn.生成一个函数,定义支持向量机模型预测所需变量的定点数据类型。使用所有可用的预测器数据来获得定点数据类型的真实范围。
generateLearnerDataTypeFcn(“myMdl”, (standardizedX;standardizedXTest])
generatelearnerdatatypefcn.生成myMdl_datatype函数。显示的内容mymdl_datatype.m.通过使用类型函数。
类型mymdl_datatype.m.
函数T = myMdl_datatype (dt) % myMdl_datatype为定点定义数据类型生成代码% % T = myMdl_datatype (dt)返回的数据类型结构T,它定义了%所需的变量的数据类型生成定点C / c++代码%机器学习模型的预测。T的每个字段都包含一个fi返回的%定点对象。输入参数dt指定定点对象的% DataType属性。指定dt为'Fixed'(默认)%用于定点代码生成,或指定dt为'Double'以模拟定点代码的%浮点行为。使用输出结构T作为入口点%函数的输入参数和%入口点函数中loadLearnerForCoder的第二个输入参数。有关更多信息,请参见loadLearnerForCoder。%文件:myMdl_datatype。m % Statistics and Machine Learning Toolbox Version 12.1 (Release R2021a) % Generated by MATLAB, 23-Feb-2021 19:10:54 if nargin < 1 dt = 'Fixed';END%SET定点数学设置FM = FIMATH('roundingMethod','floor',...'overflowation','wrap',...'productmode','fullprecision',...'maxproductwordlength',128,...'summode','fourprecision',...'maxsumwordlength',128);%预估数据T.XDataType = fi([],true,16,11,fm,'DataType',dt); % Data type for output score T.ScoreDataType = fi([],true,16,14,fm,'DataType',dt); % Internal variables % Data type of the squared distance dist = (x-sv)^2 for the Gaussian kernel G(x,sv) = exp(-dist), % where x is the predictor data for an observation and sv is a support vector T.InnerProductDataType = fi([],true,16,6,fm,'DataType',dt); end
笔记:如果您单击位于这个例子中的右上部分的按钮,并在打开的MATLAB®例如,然后打开MATLAB的例子文件夹。此文件夹包含入口点函数文件。
的myMdl_datatype函数使用默认字长度(16)并提出最大分数长度,以避免每个变量的默认字长度(16)和安全距(10%)避免溢出。
创建一个结构T通过使用定义固定点数据类型myMdl_datatype.
T = myMdl_datatype ('固定的')
t =结构与字段:XDatatype:[0x0 Embedded.fi] scoringatatype:[0x0嵌入式.fi] InnerProductDattype:[0x0嵌入式.FI]
结构T包括运行所需的名称和内部变量的字段预测函数。每个字段包含一个定点对象,由fi(定点设计师).例如,显示预测器数据的固定点数据类型属性。
t.xdatatype.
ANS = [] DataTypeMode:定点:二进制点缩放符号性:签字字长:16 FractionLength:11 RoundingMethod:地板OverflowAction:裹ProductMode:FullPrecision MaxProductWordLength:128 SumMode:FullPrecision MaxSumWordLength:128
有关生成的函数和结构的更多细节,请参见数据类型功能.
定义入口点函数
定义命名的入口点函数myFixedPointPredict这有以下内容:
接受预测数据
X和定点数据类型结构T.使用两者加载训练的SVM分类模型的定点版本
loadLearnerForCoder和结构T.使用加载模型预测标签和分数。
功能(标签,分数)= myFixedPointPredict (X, T)%#codegen.Mdl = loadLearnerForCoder (“myMdl”,'数据类型'T);(标签,分数)=预测(Mdl X);结束
(可选)优化固定点数据类型
通过使用优化固定点数据类型buildInstrumentedMex和showInstrumentationResults.通过使用记录所有命名和内部变量的最小值和最大值buildInstrumentedMex.使用仪器使用showInstrumentationResults;然后,根据结果,调整变量的定点数据类型属性。
指定入口点函数的输入参数类型
的输入参数类型myFixedPointPredict使用2×1个单元格阵列。
ARGS =细胞(2,1);
第一个输入参数是预测器数据。的XDataType结构领域T指定所述预测数据的定点数据类型。转变X中指定的类型t.xdatatype.通过使用投掷(定点设计师)函数。
x_fx =施法(标准化x,'喜欢',T.XDataType);
测试数据集不具有与训练数据集相同的大小。指定ARGS {1}通过使用Coder.typeof.(MATLAB编码器)因此MEX功能可以采用可变大小的输入。
ARGS {1} = coder.typeof (X_fx、大小(standardizedX) [1,0]);
第二个输入参数是结构T,它必须是一个编译时间常数。用编码器.Constant.(MATLAB编码器)指定T作为代码生成期间的常量。
args {2} =编码器.Constant(t);
创建仪表MEX功能
通过创建仪表MEX功能buildInstrumentedMex(定点设计师).
使用该输入点函数的输入参数类型
arg游戏选择。通过使用使用的MEX函数名称
-O选择。通过使用来计算直方图
柱状图选择。允许使用完整的代码生成支持金宝app
-coder选择。
buildInstrumentedMexmyFixedPointPredictarg游戏arg游戏-OmyFixedPointPredict_instrumented柱状图-coder
代码生成成功。
测试仪器型MEX功能
运行仪器化的MEX功能以记录仪器结果。
[labels_fx1,scors_fx1] = myfixedpointpredict_instrumented(x_fx,t);
您可以多次运行录音MEX功能以从各种测试数据集记录结果。使用仪器化的MEX功能使用标准化的东西.
Xtest_fx =铸造(standardizedXTest,'喜欢',T.XDataType);[labels_fx1_test,scores_fx1_test] = myFixedPointPredict_instrumented(Xtest_fx,T);
查看仪表型MEX功能的结果
称呼showInstrumentationResults(定点设计师)打开包含仪器结果的报告。查看模拟最小值和最大值,提出分数长度,电流范围的百分比,和整数的状态。
showInstrumentationResults ('myfixedpointpredict_instrumented')
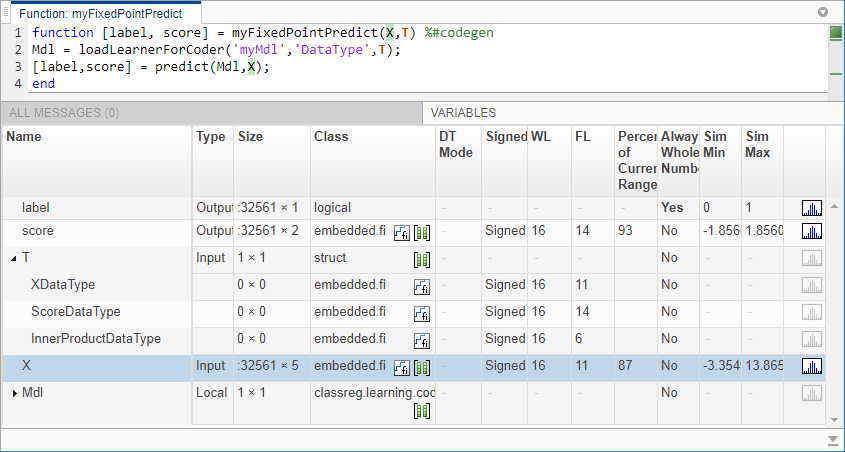
中建议的单词长度和分数长度X与那些相同XDataType结构T.
通过单击查看变量的直方图 在这一点变量标签。
在这一点变量标签。
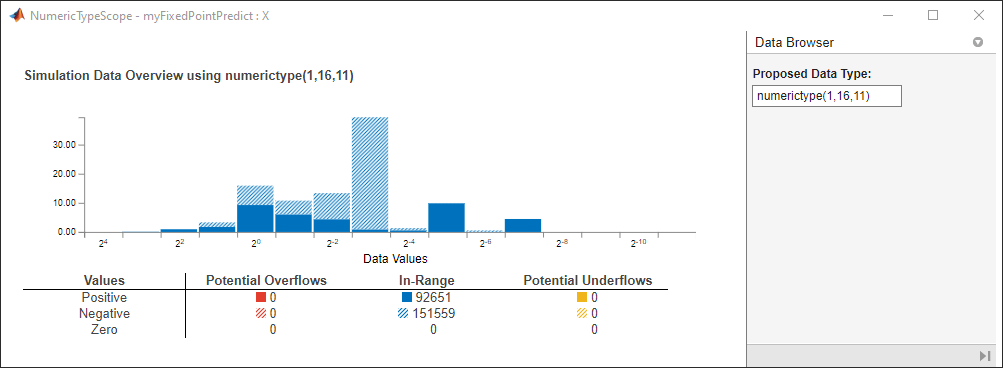
窗口包含具有有关变量信息的直方图和对话面板。有关此窗口的信息,请参阅numerictyPescope.(定点设计师)参考页面。
通过使用清除结果clearInstrumentationResults.(定点设计师).
clearInstrumentationResults('myfixedpointpredict_instrumented')
验证仪器函数
从比较的输出预测和myFixedPointPredict_instrumented.
(标签、分数)=预测(Mdl standardizedX);labels_fx1 verify_labels1 = isequal(标签)
verify_labels1 =逻辑0
isequal返回逻辑1(真),如果标签和labels_fx1是相等的。如果标签不相等,可按如下方法计算标签分类错误的百分比。
diff_labels1 = sum(strcmp(strcmp(labels_fx1),string(标签))== 0)/长度(标签_fx1)* 100
diff_labels1 = 0.1228
寻找最大的得分输出之间的相对差异。
diff_scores1 = max(abs((scors_fx1.double(:,1)-scores(:,1))./ scores(:1))))
diff_scores1 = 83.0713.
调优定点数据类型
如果录制的结果显示溢出或下溢,或者您想提高生成的代码的精度,则可以调整固定点数据类型。通过更新来修改固定点数据类型myMdl_datatype工作,并创建一个新的结构,然后生成使用新的结构的代码。要更新myMdl_datatype功能,可以手动修改在功能文件定点数据类型(mymdl_datatype.m.)。或者,您可以生成使用功能generatelearnerdatatypefcn.并指定较长的单词长度,如本例所示。有关详细信息,请参见提示.
生成一个新的数据类型函数。指定单词长度为32和名称myMdl_datatype2为生成的函数。
generateLearnerDataTypeFcn(“myMdl”, (standardizedX;standardizedXTest),“字”,32,'OutputFunctionName',“myMdl_datatype2”)
显示的内容myMdl_datatype2.m.
类型myMdl_datatype2.m
函数t = mymdl_datatype2(dt)%mymdl_datatype2定义了固定点代码生成的数据类型,生成%%t = mymdl_datatype2(dt)返回数据类型结构t,它为生成固定点C / C ++所需的变量定义%数据类型代码%以预测机器学习模型。T的每个字段都包含一个fi返回的%定点对象。输入参数dt指定定点对象的% DataType属性。指定dt为'Fixed'(默认)%用于定点代码生成,或指定dt为'Double'以模拟定点代码的%浮点行为。使用输出结构T作为入口点%函数的输入参数和%入口点函数中loadLearnerForCoder的第二个输入参数。有关更多信息,请参见loadLearnerForCoder。%文件:mymdl_datatype2.m%统计和机器学习工具箱版本12.1(发布r2021a)%由matlab生成,23-feb-2021 19:12:22如果nargin <1 dt ='固定';END%SET定点数学设置FM = FIMATH('roundingMethod','floor',...'overflowation','wrap',...'productmode','fullprecision',...'maxproductwordlength',128,...'summode','fourprecision',...'maxsumwordlength',128);预测器数据的%数据类型t.xdatatype = fi([],true,32,27,fm,'datatype',dt); % Data type for output score T.ScoreDataType = fi([],true,32,30,fm,'DataType',dt); % Internal variables % Data type of the squared distance dist = (x-sv)^2 for the Gaussian kernel G(x,sv) = exp(-dist), % where x is the predictor data for an observation and sv is a support vector T.InnerProductDataType = fi([],true,32,22,fm,'DataType',dt); end
的myMdl_datatype2函数指定单词长度32,并提出最大的分数长度以避免溢出。
创建一个结构T2.通过使用定义固定点数据类型myMdl_datatype2.
t2 = mymdl_datatype2('固定的')
T2 =结构与字段:XDatatype:[0x0 Embedded.fi] scoringatatype:[0x0嵌入式.fi] InnerProductDattype:[0x0嵌入式.FI]
创建一个新的仪表函数,记录结果,并通过使用查看结果buildInstrumentedMex和showInstrumentationResults.
X_fx2 =投(standardizedX,'喜欢', T2.XDataType);buildInstrumentedMexmyFixedPointPredictarg游戏{x_fx2,coder.constant(t2)}-OmyFixedPointPredict_instrumented2柱状图-coder
代码生成成功。
[labels_fx2,scores_fx2] = myFixedPointPredict_instrumented2(X_fx2,T2);showInstrumentationResults (“myFixedPointPredict_instrumented2”)
检查仪表报告,然后清除结果。
clearInstrumentationResults(“myFixedPointPredict_instrumented2”)
验证myFixedPointPredict_instrumented2.
labels_fx2 verify_labels2 = isequal(标签)
verify_labels2 =逻辑0
diff_labels2 = sum(strcmp(string(labels_fx2),string(标签))== 0)/ length(labels_fx2)* 100
diff_labels2 = 0.0031
diff_scores2 = max(abs((scores_fx2.double(:,1)-scores(:,1))./ scores(:1)))
diff_scores2 = 2.0602
错误分类标签的百分比diff_labels2.和得分值的相对差diff_scores2.小于使用默认字长度生成的先前MEX函数(16)的那些。
关于通过测试MATLAB®代码优化定点数据类型的更多细节,请参阅参考页面buildInstrumentedMex(定点设计师),showInstrumentationResults(定点设计师), 和clearInstrumentationResults.(定点设计师),以及例子一组数据类型使用最小/最大仪器仪表(定点设计师).
生成代码
生成用于入口点函数的代码代码生成.而不是指定用于预测器数据集的可变大小输入,请通过使用指定固定大小的输入Coder.typeof..如果知道预测数据集传递给生成的代码,然后生成用于固定大小的输入码的大小优选的是,代码的简单性。
代码生成myFixedPointPredictarg游戏{coder.typeof (X_fx2 [1,5], [0]), coder.Constant (T2)}
代码生成成功。
代码生成生成MEX函数myFixedPointPredict_mex与平台相关的扩展。
验证生成的代码
您可以验证myFixedPointPredict_mex以与您验证所录制的MEX功能的方式相同。看看验证仪器函数部分详情。
[labels_sampled, scores_sampled] =预测(Mdl standardizedX_sampled);n =大小(standardizedX_sampled, 1);labels_fx = true (n, 1);scores_fx = 0 (n, 2);为i = 1: n [labels_fx(我),scores_fx(我,:)]= myFixedPointPredict_mex (X_fx2 (idx(我):),T2);结束verify_labels = isequal (labels_sampled labels_fx)
验证_labels =.逻辑1
diff_labels = sum(strcmp(string(labels_fx),string(labels_sampled))== 0)/ length(labels_fx)* 100
diff_labels = 0
diff_scores = MAX(ABS((scores_fx(:,1)-scores_sampled(:,1))./ scores_sampled(:,1)))
diff_scores = 0.0638.
记忆使用
良好做法是在培训模型之前手动标准化预测器数据。如果你使用'标准化'名称 - 值对的参数,而不是,然后将所生成的定点代码包括标准化的操作,这会导致精度的损失和增加的内存使用。
如果您生成一个静态库,您可以通过使用代码生成报告来查找生成代码的内存使用情况。指定-config:lib生成静态库,并使用-报告选项生成代码生成报告。
代码生成myFixedPointPredictarg游戏{coder.typeof (X_fx2 [1,5], [0]), coder.Constant (T2)}-Omyfixedpointpredict_lib.-config:lib-报告
在这一点总结选项卡的代码生成报告,单击代码指标.函数信息部分显示累积的堆栈大小。
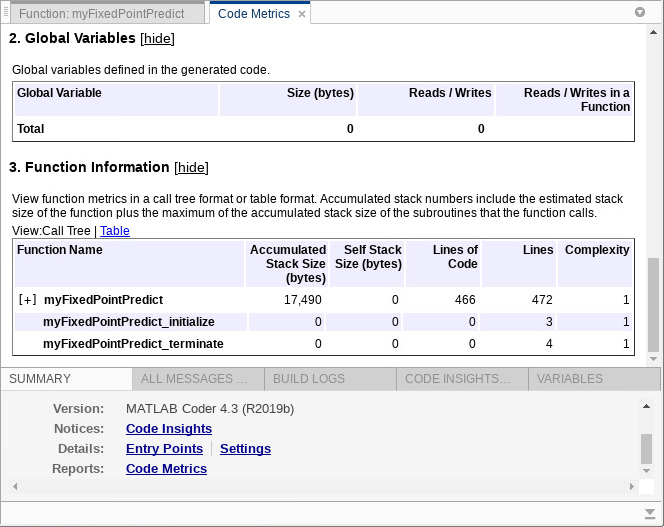
要查找内存使用与培养了模型“标准化”,“真”,您可以运行以下代码。
MDL = fitcsvm(X_sampled,Y_sampled,'重量'w_sampled,'骨箱','高斯','标准化',真正的);saveLearnerForCoder (Mdl“myMdl”);generateLearnerDataTypeFcn(“myMdl”,[X;xtest],“字”,32,'OutputFunctionName','mymdl_standardize_datatype') T3 = mymdl_standarze_datatype ('固定的');X_fx3 =投(X_sampled,'喜欢', T3.XDataType);代码生成myFixedPointPredictarg游戏{coder.typeof (X_fx3 [1,5], [0]), coder.Constant (T3)}-Omyfixedpointpredict_standardize_lib.-config:lib-报告
另请参阅
generatelearnerdatatypefcn.|loadLearnerForCoder|Savelarnerforcoder.|buildInstrumentedMex(定点设计师)|投掷(定点设计师)|clearInstrumentationResults.(定点设计师)|fi(定点设计师)|showInstrumentationResults(定点设计师)|代码生成(MATLAB编码器)
相关话题
- 定点数据类型(定点设计师)
- 在MATLAB中创建定点数据(定点设计师)
- 一组数据类型使用最小/最大仪器仪表(定点设计师)
您还可以从以下列表中选择一个网站:
