主要内容
使用并行计算实现引导
串行和并行中的引导
下面是一个在并行和串行中为引导程序计时的示例。该示例从两种高斯混合生成数据,构建结果数据的非参数估计,并使用bootstrap来获得采样变异性的感觉。
生成数据:
从两个高斯分布的混合中生成一个大小为1000的随机样本x = [randn(700,1);4 + 2 * randn (300 1)];
从数据构建密度的非参数估计:
奈= 4:0.01:12;myfun = @(X) ksdensity(X,latt);pdfestimate = myfun (x);
引导估计以获得其抽样变异性的感觉。串行运行引导程序进行时间比较。
B = bootstrp(200,myfun,x);
并行运行引导程序进行时间比较:
mypool = parpool()使用'local'配置文件启动parpool…连接2个工人。mypool =具有属性的Pool: attachdfiles: {0x1 cell} NumWorkers: 2 IdleTimeout: 30 Cluster: [1x1 parallel.cluster. NumWorkers: 2 IdleTimeout: 30 Cluster: [1x1 parallel.cluster. NumWorkers]RequestQueue: [1x1 parallel.]RequestQueue] SpmdEnabled: 1选择= statset(“UseParallel”,真正的);B = bootstrp(200,myfun,x,'Options',opt);toc运行时间为6.304077秒。
在本例中,并行计算的速度几乎是串行计算的两倍。
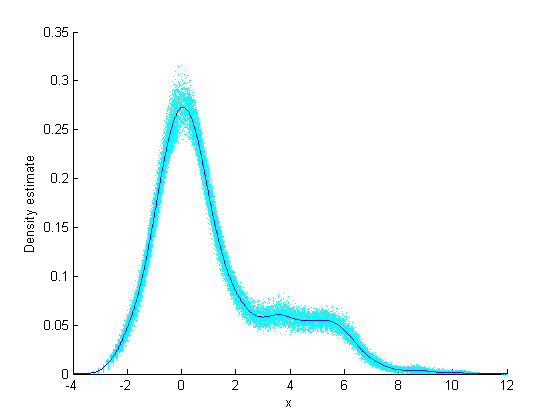
覆盖的ksdensity密度估计与200 bootstrapped估计在平行bootstrap中获得。你可以从这张图中了解到如何评估密度估算的准确性。
hold on for i=1:size(B,1), plot(latt,B(i,:),'c:') end plot(latt,pdfestimate);包含(“x”);ylabel(密度估计的)
可再生的并行自举
要以可复制的方式并行运行示例,请适当设置选项(参见运行可重复的并行计算).首先设置问题和并行环境如串行和并行中的引导.然后设置选项,在支持子流的流中使用子流。金宝app
s = RandStream(“mlfg6331_64”);% has substreams options = statset('UseParallel',true,…“流”,年代,“UseSubstreams”,真正的);myfun B2 = bootstrp(200年,x,“选项”,选择);
要重新运行引导程序并得到相同的结果:
reset(s) %设置流的初始状态B3 = bootstrp(200,myfun,x,'Options',opts);isequal(B2,B3) %检查是否相同的结果ans = 1
你也可以从以下列表中选择一个网站:
