oobPermutedPredictorImportance
预测对回归树木随机森林的禁止超预测性观测的排列的重要性估计
描述
偶尔= OobperMutedPredictorimportance(Mdl)Mdl.Mdl必须是一个RegressionBaggedEnsemble模型对象。
输入参数
输出参数
例子
估计预测因子的重要性
加载Carsmall.数据集。考虑一个模型,该模型预测汽车的平均燃料经济性,赋予其加速度,气缸数量,发动机位移,马力,制造商,模型年和重量。考虑气瓶,MFG.,model_year.作为分类变量。
负载Carsmall.气缸=分类(缸);及时通知=分类(cellstr (Mfg));Model_Year =分类(Model_Year);X =表(加速、气缸、排量、马力、制造行业,......model_year,重量,mpg);
您可以使用整个数据集培训500个回归树的随机森林。
Mdl = fitrensemble (X,“英里”,'方法','包','numlearnicalnicycle',500);
fitrensemble使用默认模板树对象Templatetree()作为一个弱学习者'方法'是'包'.在此示例中,为了再现,指定'可重复',真实当您创建树模板对象时,然后将对象用作弱的学习者。
RNG('默认')再现性的百分比t = templateTree ('可重复',真的);%用于随机预测器选择的重现性Mdl = fitrensemble (X,“英里”,'方法','包','numlearnicalnicycle'500,“学习者”t);
Mdl是A.RegressionBaggedEnsemble模型。
通过禁用外袋观察来估计预测的重要措施。使用条形图比较估计值。
小鬼= oobPermutedPredictorImportance (Mdl);图;酒吧(imp);标题('不禁止允许的预测值重视估计');ylabel(“估计”);包含('预测者');甘氨胆酸h =;h.XTickLabel = Mdl.PredictorNames;h.XTickLabelRotation = 45;h.TickLabelInterpreter =“没有”;
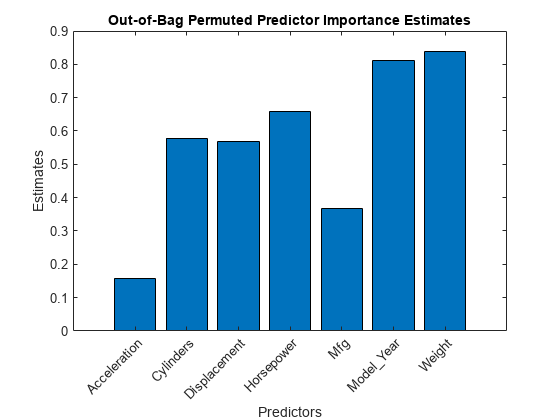
偶尔是一个1×7的预测值重要性估算矢量。较大的值表示预测因子对预测产生更大影响。在这种情况下,重量是最重要的预测因素,其次是model_year..
使用并行计算的预测器重要性的无偏估计
加载Carsmall.数据集。考虑一个模型,该模型预测汽车的平均燃料经济性,赋予其加速度,气缸数量,发动机位移,马力,制造商,模型年和重量。考虑气瓶,MFG.,model_year.作为分类变量。
负载Carsmall.气缸=分类(缸);及时通知=分类(cellstr (Mfg));Model_Year =分类(Model_Year);X =表(加速、气缸、排量、马力、制造行业,......model_year,重量,mpg);
显示类别变量中表示的类别数量。
numCylinders =元素个数(类别(气缸))
numcylinders = 3
numMfg =元素个数(类别(有限公司))
numMfg = 28
nummodelyear = numel(类别(model_year))
numModelYear = 3
因为只有3个类别气瓶和model_year.,标准推车,预测算法更喜欢在这两个变量上分割连续的预测器。
使用整个数据集培训500个回归树的随机森林。为了种植无偏的树木,请指定用于分裂预测器的曲率测试的使用。由于数据中存在缺少值,因此指定代理分割的使用。要重现随机预测器选择,请使用“将随机数发生器的种子设置为”rng并指定'可重复',真实.
RNG('默认');再现性的百分比t = templateTree (“PredictorSelection”,“弯曲”,“代理”,“上”,......'可重复',真的);随机预测器选择的再现性的%Mdl = fitrensemble (X,“英里”,'方法','包','numlearnicalnicycle'500,......“学习者”t);
通过禁用外袋观察来估计预测的重要措施。并行执行计算。
选项= statset(“UseParallel”,真的);Imp = OobperMutedPredictorimportance(MDL,'选项',选项);
使用“local”配置文件启动并行池(parpool)…连接到并行池(工作人员数量:6)。
使用条形图比较估计值。
图;酒吧(imp);标题('不禁止允许的预测值重视估计');ylabel(“估计”);包含('预测者');甘氨胆酸h =;h.XTickLabel = Mdl.PredictorNames;h.XTickLabelRotation = 45;h.TickLabelInterpreter =“没有”;
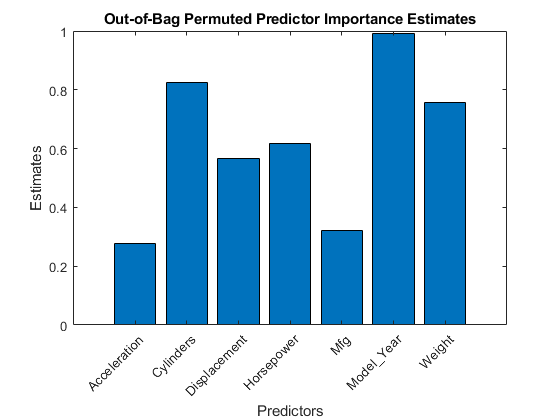
在这种情况下,model_year.是最重要的预测因素,其次是气瓶.将这些结果与结果进行比较估计预测因子的重要性.
更多关于
提示
在使用随机森林时使用fitrensemble:
标准CART倾向于选择包含许多不同值(如连续变量)的分离预测因子,而不是包含很少不同值(如分类变量)的分离预测因子[3].如果预测器数据集是异构的,或者如果存在的预测器具有比其他变量相对较少的不同值相对较少,则考虑指定曲率或交互测试。
使用标准CART生长的树木对预测变量相互作用不敏感。此外,与交互测试的应用相比,在存在许多无关的预测因子时,这种树不太可能识别出重要的变量。因此,为了解释预测变量之间的交互作用,并在存在许多不相关变量的情况下识别重要变量,指定交互作用检验[2].
如果培训数据包括许多预测因子,并且您想要分析预测值重要性,请指定
'numvariablestosample'的Templatetree.功能“所有”对于集合的树学习者。否则,该软件可能无法选择一些预测器,低估了他们的重要性。
有关更多详细信息,请参阅Templatetree.和选择分割预测测量选择技术.
参考
[1] Breiman,L.,J.Friedman,R. Olshen和C. Stone。分类与回归树.佛罗里达州博卡拉顿:CRC出版社,1984。
[2] LOH,W.Y.“回归树木具有无偏的变量选择和相互作用检测。”统计学日志, 2002年第12卷,第361-386页。
Loh w.y y and Y.S. Shih分类树的分裂选择方法统计学日志,卷。7,1997,第815-840页。
扩展能力
你也可以从以下列表中选择一个网站:
