主要内容
曲调RobustBoost
的RobustBoost该算法即使在训练数据有噪声的情况下也能进行良好的分类预测。然而,默认RobustBoost参数可以产生不能很好预测的集合。这个例子展示了一种优化参数以获得更好的预测精度的方法。
生成带有标签噪声的数据。这个例子中,每个观测值有20个均匀的随机数字,并将观测值分类为1如果前5个数字的总和超过2.5(所以大于平均值),并且0否则:
rng (0,“旋风”)%的再现性Xtrain =兰德(2000年,20);Ytrain = sum(Xtrain(:,1:5),2) > 2.5;
为了添加噪声,随机切换10%的分类:
idx = randsample(2000、200);Ytrain (idx) = ~ Ytrain (idx);
创建一个集合AdaBoostM1比较的目的:
ada = fitcensemble (Xtrain Ytrain,“方法”,“AdaBoostM1”,...“NumLearningCycles”, 300,“学习者”,“树”,“LearnRate”, 0.1);
创建一个集合RobustBoost.因为数据有10%的错误分类,也许15%的错误目标是合理的。
rb1 = fitcensemble (Xtrain Ytrain,“方法”,“RobustBoost”,...“NumLearningCycles”, 300,“学习者”,“树”,“RobustErrorGoal”, 0.15,...“RobustMaxMargin”1);
注意,如果您将错误目标设置为足够高的值,那么软件将返回一个错误。
创建一个具有非常乐观的错误目标的集合,0.01:
而已= fitcensemble (Xtrain Ytrain,“方法”,“RobustBoost”,...“NumLearningCycles”, 300,“学习者”,“树”,“RobustErrorGoal”, 0.01);
比较三组组合的再替换误差:
图绘制(resubLoss (rb1“模式”,“累积”));持有在情节(resubLoss而已,“模式”,“累积”),“r——”);情节(resubLoss (ada,“模式”,“累积”),“g”。);持有从;包含(树木的数量);ylabel (“Resubstitution错误”);传奇(“ErrorGoal = 0.15”,“ErrorGoal = 0.01”,...“AdaBoostM1”,“位置”,“不”);
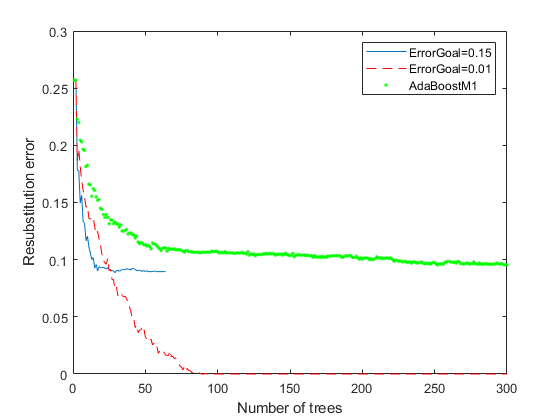
所有的RobustBoost曲线显示出较低的再替代误差AdaBoostM1曲线。误差目标0.01曲线显示了在大多数范围内最低的再替代误差。
Xtest =兰德(2000年,20);Ytest = sum(Xtest(:,1:5),2) > 2.5;idx = randsample(2000、200);欧美(idx) = ~欧美(idx);图;情节(损失(rb1 Xtest,欧美,“模式”,“累积”));持有在情节(损失(Xtest而已,欧美,“模式”,“累积”),“r——”);情节(损失(ada Xtest,欧美,“模式”,“累积”),“g”。);持有从;包含(树木的数量);ylabel (测试错误的);传奇(“ErrorGoal = 0.15”,“ErrorGoal = 0.01”,...“AdaBoostM1”,“位置”,“不”);
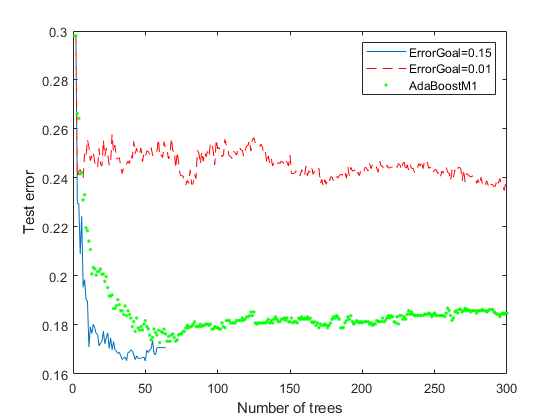
误差目标0.15的误差曲线是绘制范围内最小(最好)的。AdaBoostM1具有比曲线更高的误差目标为0.15。对于大多数绘制范围来说,过于乐观的误差目标0.01的曲线仍然比其他算法高得多(更差)。
另请参阅
相关的话题
你也可以从以下列表中选择一个网站:
