情节
绘制福芙价值
描述
阴谋(的Shapley值的水平条形图解释者)沙普利对象解释者.这些值存储在对象的值中ShapleyValues财产。每个竖条显示黑箱模型中每个特性的Shapley值(讲解员。)对于查询点(BlackBoxModel.讲解员。)。QueryPoint
b =情节(___)返回条形图对象b使用前面语法中的任何输入参数组合。使用b查询或修改酒吧属性在创建后的条形图。
例子
绘制所有类别的Shapley值
训练分类模型并创建沙普利对象。然后利用目标函数绘制Shapley值情节.
加载Creditrating_Historical.数据集。该数据集包含客户id及其财务比率、行业标签和信用评级。
TBL = READTABLE(“CreditRating_Historical.dat”);
显示表的前三行。
头(资源描述,3)
ANS =.3×8表ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA工业评分_____ _____ _____ _______ ________ _____ ________ ______ 62394 0.013 0.104 0.036 0.447 0.142 3 { 'BB'} 48608 0.232 0.335 0.062 1.969 0.281 8 { 'A'} 42444 0.311 0.367 0.074 1.935 0.366 1 {'A'}
通过使用培训Blackbox模型的信用评级模型fitcecoc函数。使用从第二列到第七列的变量资源描述作为预测变量。推荐的实践是指定类名以设置类的顺序。
黑箱= fitcecoc(资源描述,'评分',...'predictornames',tbl.properties.variablenames(2:7),...“CategoricalPredictors”,“行业”,...“类名”, {“AAA”“AA”“一个”'bbb'“BB”“B”'CCC'});
创建一个沙普利对象,它解释了最后一次观测的预测。为了更快的计算,将25%的观测数据从资源描述分层并使用样品来计算福利值。
queryPoint =(资源(最终,:)
querypoint =表1×8ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA工业评分_____ _____ _____ _______ ________ ____ ________ ______ 73104 0.239 0.463 0.065 2.924 0.34 2 { 'AA'}
rng (“默认”)再现性的百分比c = cvpartition(tbl.rating,“坚持”,0.25);tbl_s = tbl(测试(c),:);解释者=福利(Blackbox,Tbl_s,“QueryPoint”,querypoint);
对于分类模型,沙普利使用每个类的预测类得分计算Shapley值。中的值显示ShapleyValues财产。
讲解员。ShapleyValues
ANS =.6×8表预测AAA AA BBB BB B CCC __________ __________ __________ ___________ __________ ___________ ___________ ___________ " WC_TA“0.014583 0.0064698 0.0027468 0.00045582 -0.0079591 -0.011811 -0.011279”RE_TA“0.047796 0.027083 0.015166 -0.0031936 -0.025054 -0.059564 -0.083439”EBIT_TA“0.00034326 0.0001524 0.00012384 3.5202 -0.00019141 e-05-0.00038252 -0.00033693 "MVE_BVTD" 0.38221 0.38229 0.19383 -0.0079011 -0.15755 -0.21522 -0.17022 "S_TA" -0.0035663 -0.0025991 -0.00021177 -0.0010166 -2.0989e-05 0.00041415 -0.00058882 "Industry" -0.028315 -0.013392 0.00089644 0.022877 0.025636 0.028485 0.044835
的ShapleyValues属性包含每个类的所有特性的Shapley值。
通过使用使用来绘制预测类的福利值情节函数。
情节(解释器)
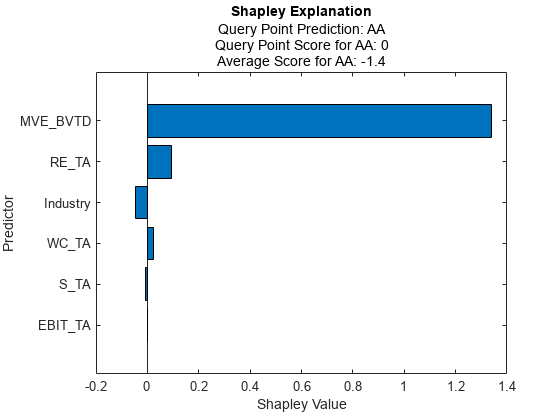
水平条形图显示所有变量的福音值,按其绝对值排序。由于相应的变量,每个福芙值解释了从预测类的平均分数的查询点的分数的偏差。
中指定所有类名,绘制所有类的Shapley值讲解员。BlackBoxModel..
情节(解释者,“类名”explainer.BlackboxModel.ClassNames)
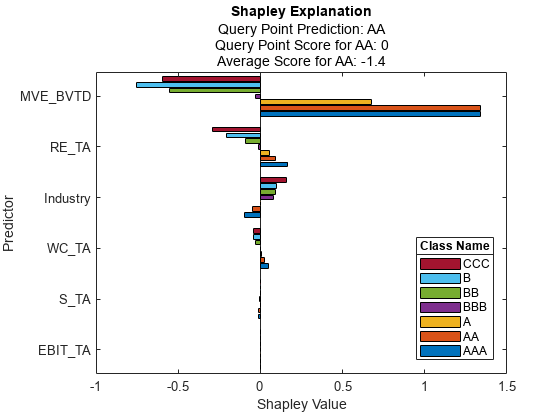
指定要绘制的重要预测数
训练一个回归模型并创建一个沙普利对象。使用对象功能适合来计算指定查询点的Shapley值。然后利用目标函数绘制预测器的Shapley值情节.调用时指定要绘制的重要预测器的数量情节函数。
加载carbig数据集,其中包含在20世纪70年代和20世纪80年代初进行的汽车测量。
负载carbig
创建包含预测器变量的表加速,气缸等等,以及响应变量MPG..
台=表(加速度、汽缸、排量、马力、Model_Year重量,MPG);
在培训集中删除缺失值可以帮助降低内存消耗并加速培训fitrkernel函数。删除缺失的值资源描述.
台= rmmissing(台);
训练一个黑盒模型MPG.通过使用fitrkernel功能
rng (“默认”)再现性的百分比mdl = fitrkernel(资源描述,“英里”,“CategoricalPredictors”[2 - 5]);
创建一个沙普利对象。指定数据集资源描述,因为mdl不包含培训数据。
讲解员=沙普利(mdl(资源)
explainer = shapley with properties: BlackboxModel: [1x1 RegressionKernel] QueryPoint: [] BlackboxFitted: [] ShapleyValues: [] NumSubsets: 64 X: [392x7 table] CategoricalPredictors: [2 5] Method: ' interonal -kernel' Intercept: 22.6202
解释者存储训练数据资源描述在X财产。
计算所有预测变量的福利值,以获得第一次观察资源描述.
: queryPoint =(资源(1)
querypoint =表1×7加速气缸位移马力Model_Year体重MPG ____________ _________ ____________ __________ __________ ______ ___ 12 8 307 130 70 3504
解释者=适合(解释者,Querypoint);
对于回归模型,沙普利使用预测的响应计算Shapley值,并将它们存储在ShapleyValues财产。中的值显示ShapleyValues财产。
讲解员。ShapleyValues
ANS =.6×2表Predictor ShapleyValue ______________ ____________“加速”-0.1561“圆柱”-0.18306“位移”-0.34203“马力”-0.27291“Model_year”-0.2926“重量”-0.32402
通过使用使用的查询点的福利值绘制情节函数。指定'numimportantpredictors',5只绘制预测反应的五个最重要的预测因子。
情节(解释者,'numimportantpredictors'5)
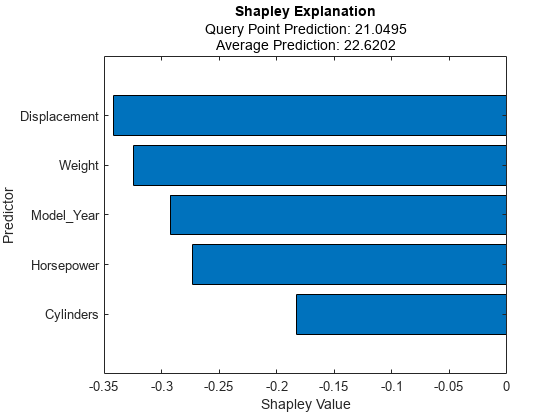
水平条形图显示了五个最重要的预测因子的福音值,由其绝对值排序。由于相应的变量,每个福族物值解释了对来自平均值的查询点的预测的偏差。
输入参数
更多关于
参考文献
您还可以从以下列表中选择一个网站:
