使用多词短语分析文本数据
这个例子展示了如何使用n-gram频率计数来分析文本。
n元组是的元组 连续词。例如,一个双字符(当 )是一对连续的单词,如“heavy rainfall”。unigram(当的情况 )是一个单词。n-g包模型记录不同n-g出现在文档集合中的次数。
使用bag-of-n-grams模型,您可以在原始文本数据中保留有关单词顺序的更多信息。例如,bag-of-n-grams模型更适合捕获文本中出现的短短语,如“暴雨”和“雷雨风”。
要创建包-n-grams模型,请使用bagOfNgrams.你可以输入bagOfNgrams对象转换为其他文本分析工具箱函数,例如wordcloud和fitlda.
加载和提取文本数据
加载示例数据。该文件factoryReports.csv包含工厂报告,包括每个事件的文本描述和分类标签。删除带有空报告的行。
文件名=“factoryReports.csv”;data = readtable(文件名,“TextType”,“字符串”);
从表中提取文本数据并查看前几个报告。
textData = data.Description;textData (1:5)
ans =5×1的字符串“物品偶尔会卡在扫描仪的线轴上。”“组装器的活塞发出响亮的咔嗒咔嗒和砰砰的声音。”“启动核电站时,电力会被切断。”“组装器里的电容器被炸了。”“搅拌机把保险丝弄坏了。”
准备文本数据进行分析
创建一个函数,用于标记和预处理文本数据,以便用于分析。功能preprocessText列在示例的最后,执行以下步骤:
使用。将文本数据转换为小写
较低的.使用标记文本
标记化文档.使用删除标点符号
删除标点符号.删除使用停止词的列表(如“and”,“of”和“the”)
removeStopWords.删除使用2个或更少字符的单词
除去短文.删除超过15个字符的单词
removeLongWords.用英语把单词语法化
normalizeWords.
使用示例预处理函数预测试准备文本数据。
文件= preprocessText (textData);文档(1:5)
ans = 5×1 tokenizedDocument: 6代币:物品偶尔被卡住扫描仪卷轴7代币:响亮的叮当声巨响来组装器活塞4代币:切断电源启动工厂3代币:炸电容器组装器3代币:搅拌器trip fuse
创建单词云
创建一个双字词云,首先创建一个包-n-grams模型使用bagOfNgrams,然后将模型输入到wordcloud.
要计算长度为2(bigrams)的n克数,请使用bagOfNgrams使用默认选项。
袋= bagOfNgrams(文档)
bag=BagofGrams,属性:计数:[480×941 double]词汇:[1×351字符串]Ngrams[941×2字符串]ngram长度:2个numgrams:941个NumDocuments:480
使用单词云可视化包-n-grams模型。
图wordcloud(包);标题(“文本数据:预处理的bigram”)

将主题模型与N-Grams中的Bag-of-N-Grams相匹配
潜在Dirichlet分配(LDA)模型是一种主题模型,它发现文档集合中的潜在主题并推断主题中的单词概率。
使用创建包含10个主题的LDA主题模型fitlda.该函数通过将n-gram视为单个单词来符合LDA模型。
mdl = fitlda(包10“详细”,0);
将前四个主题想象成词云。
数字为i=1:4子地块(2,2,i)wordcloud(mdl,i);标题(“LDA主题”+ i)结束

单词clouds突出显示了LDA主题中通常同时出现的bigram。该函数根据指定LDA主题的概率以大小绘制bigram。
用较长的短语分析文章
要使用较长的短语分析文本,请指定“NGramLengths”选择权bagOfNgrams是一个更大的值。
当使用较长的短语时,在模型中保留停止词是很有用的。例如,要检测短语“is not happy”,在模型中保留停止词“is”和“not”。
预处理文本。用删除标点符号,并标记使用标记化文档.
cleanTextData = erasePunctuation (textData);文件= tokenizedDocument (cleanTextData);
要计算长度为3的n-g(三元组),请使用bagOfNgrams并具体说明“NGramLengths”三岁。
袋= bagOfNgrams(文档,“NGramLengths”3);
使用单词云可视化包-n-grams模型。三元组的词云更好地显示了单个词的上下文。
图wordcloud(包);标题(“文本数据:三角图”)
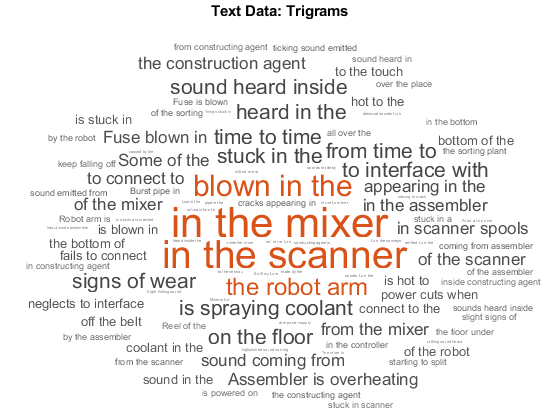
查看前10个三元组和他们的频率计数使用顶面图.
tbl=顶置图(袋,10)
台=10×3表在“混混”中的“14 3”中的“3”中的“扫描仪”中的“13 3”中的“扫描仪”中的“13 3”中的“13 3”中的“3”中的“扫描仪”中的“13 3”中的“13”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3“3”中的“3”中的“3”中的“3”中的“3”中的“3“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的“3”中的在"楼层"6 3
示例预处理函数
功能preprocessText依次执行以下步骤:
使用。将文本数据转换为小写
较低的.使用标记文本
标记化文档.使用删除标点符号
删除标点符号.删除使用停止词的列表(如“and”,“of”和“the”)
removeStopWords.删除使用2个或更少字符的单词
除去短文.删除超过15个字符的单词
removeLongWords.用英语把单词语法化
normalizeWords.
作用文档=预处理文本(文本数据)%将文本数据转换为小写。cleanTextData=较低(textData);%标记文本。文件= tokenizedDocument (cleanTextData);%删除标点符号。文件=标点符号(文件);删除一个停止词列表。= removeStopWords文件(文档);%删除包含2个或更少字符的单词,以及包含15个或更多字符的单词%人物。documents=removeShortWords(documents,2);documents=removeLongWords(documents,15);将单词义化。documents=addPartOfSpeechDetails(documents);文档=规范化日志(文档、,“风格”,“引理”);结束
另请参阅
标记化文档|bagOfWords|removeStopWords|删除标点符号|removeLongWords|除去短文|bagOfNgrams|normalizeWords|顶面图|fitlda|ldaModel|wordcloud|添加部分speechdetails
相关话题
您还可以从以下列表中选择网站:
