训练情感分类器
这个例子展示了如何使用带注释的正面和负面情感词列表和预先训练的词嵌入来训练情感分析分类器。
预先训练的词嵌入在这个工作流中起着几个作用。它将单词转换成数字向量并形成分类器的基础。然后,您可以使用分类器来预测其他单词的情绪,使用它们的向量表示,并使用这些分类来计算一段文本的情绪。情感分类器的训练和使用有四个步骤:
加载一个预先训练过的词嵌入。
加载意见词典,列出积极和消极的词。
利用正负词的词向量训练情感分类器。
计算一段文字中单词的平均情感分数。
加载预训练词嵌入
单词嵌入将词汇表中的单词映射为数字向量。这些嵌入可以捕获单词的语义细节,这样相似的单词就有相似的向量。它们还通过向量运算建立单词之间的关系模型。例如,关系罗马之于巴黎,正如意大利之于法国由方程描述 .
使用fastTextWordEmbedding函数。此函数需要文本分析工具箱™ 模型对于fastText English,160亿标记词嵌入金宝app支持包。如果未安装此支持包,则该功能将提供下载链接。
emb = fastTextWordEmbedding;
加载意见词典
从“观点词典”(也称为“情感词典”)中载入积极和消极的词汇https://www.cs.uic.edu/~liub/FBS/touction-analysis.html. [1] 首先,从数据库中提取文件. rar将文件放入名为英语意见词汇,然后导入文本。
使用函数加载数据阅读词典列在本例的最后。输出数据是一个带有变量的表吗词包含词语,以及标签包含一个绝对的情感标签,积极乐观的或消极的.
数据= readLexicon;
把开头的几句话看作是肯定的。
idx =数据。标签= =“积极的”;标题(数据(idx,:)
ans =8×2表单词标签____________ ________“a+”“Positive”比比皆是“Positive”“Positive”“abundant”“Positive”“abundant”“Positive”“abundant”“Positive”“accessible”“Positive”“accessible”“Positive
查看标记为否定的前几个单词。
idx =数据。标签= =“负面”;标题(数据(idx,:)
ans =8×2表单词标签“双面”否定“双面”否定“双面”否定“双面”反常的“负面”废除“负面”可恶的“负面”可恶的“负面”可恶的“负面”可恶的“负面”可恶的“负面”可恶的“负面”
准备培训数据
为了训练情感分类器,使用预训练单词嵌入将单词转换为单词向量教统局.首先删除没有出现在单词embedding中的单词教统局.
data.Word idx = ~ isVocabularyWord (emb);:数据(idx) = [];
随机留出10%的单词进行测试。
numWords =大小(数据,1);本量利= cvpartition (numWords,“坚持”, 0.1);dataTrain =数据(训练(cvp):);人数(=数据(测试(cvp):);
使用将训练数据中的单词转换为单词向量word2vec.
wordsTrain=dataTrain.Word;XTrain=word2vec(emb,wordsTrain);YTrain=dataTrain.Label;
情绪训练分类器
训练一个支持向量金宝app机(SVM)分类器,将单词向量分为正负两类。
mdl=fitcsvm(XTrain,YTrain);
测试分类器
使用将测试数据中的字转换为字向量word2vec.
wordsTest=dataTest.Word;XTest=word2vec(emb,wordsTest);YTest=dataTest.Label;
预测测试词向量的情感标签。
[YPred,得分]=预测(mdl,XTest);
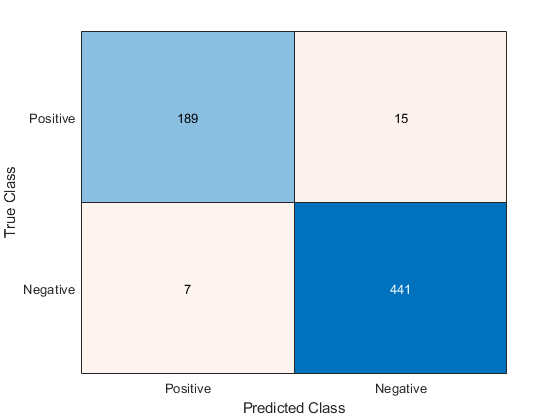
在混淆矩阵中可视化分类精度。
figure confusionchart(YTest,YPred);
在词云中可视化分类。将具有积极情绪和消极情绪的单词绘制在词云中,词大小对应预测分数。
图subplot(1,2,1) idx = YPred ==“积极的”;wordcloud (wordsTest (idx),分数(idx 1));标题(“预测积极情绪”次要情节(1、2、2)wordcloud (wordsTest (~ idx),分数(~ idx, 2));标题(“预计负面情绪”)

计算文本集合的情感
要计算一段文本的情绪,例如在社交媒体上的更新,预测文本中每个单词的情绪得分,并取平均情绪得分。
文件名=“weekendUpdates.xlsx”;台= readtable(文件名,“文本类型”,“字符串”);textData = tbl.TextData;textData (1:10)
ans =10×1字符串数组“结婚周年快乐!下一站:巴黎!✈#度假”“哈哈,在海滩上烧烤,加入自鸣得意的模式!和我一起说——我需要一个#假期!!“这么多年来第一次在家里冷静下来……这就是生活!”“周末”“我考试前的最后一个周末”“真不敢相信我的假期就这么结束了,太不公平了”“等不及这个周末打网球了”“我玩得很开心!”最好的旅行!“天气炎热,车里的空调坏了#大汗淋漓#公路旅行#度假”
创建一个函数,用于标记和预处理文本数据,以便用于分析。这个函数preprocessText,按顺序执行以下步骤:
使用标记文本
tokenizedDocument.删除标点符号使用
erasePunctuation.去掉“and”、“of”和“the”等停止词
removeStopWords.使用
较低的.
使用预处理函数preprocessText准备文本数据。运行此步骤可能需要几分钟。
文档=预处理文本(textData);
从文档中删除不出现在单词嵌入中的单词教统局.
idx=~isVocabularyWord(emb,documents.Vocabulary);文档=删除字(文档,idx);
要可视化情感分类器对新文本的概括程度,请根据文本中出现的词(而不是训练数据中出现的词)对情感进行分类,并将其可视化到词云中。使用词云手动检查分类器的行为是否符合预期。
话说= documents.Vocabulary;单词(ismember(话说,wordsTrain)) = [];vec = word2vec (emb,单词);[YPred,分数]=预测(mdl vec);图subplot(1,2,1) idx = YPred ==“积极的”; wordcloud(单词(idx),分数(idx,1));头衔(“预测积极情绪”)子图(1,2,2)wordcloud(单词(~idx),分数(~idx,2));头衔(“预计负面情绪”)

要计算给定文本的情感,请计算文本中每个单词的情感分数并计算平均情感分数。
计算更新的平均情绪得分。对于每个文档,将单词转换为单词向量,预测单词向量上的情感分数,使用后验积分变换函数对分数进行转换,然后计算平均情感分数。
对于I = 1:numel(documents) words = string(documents(I));vec = word2vec (emb,单词);[~,分数]=预测(mdl vec);sentimentScore (i) =意味着(分数(:1));终止
使用文本数据查看预测的情绪分数。分数大于0表示积极情绪,分数小于0表示消极情绪,分数接近0表示中性情绪。
表(sentimentScore’,textData)
ans =50×2表Var1 textData __________ ___________________________________________________________________________________________________________________________ 1.8382”结婚纪念日快乐!下一站:巴黎!✈#vacation" 1.294 "哈哈,在海滩上烧烤,进入自鸣得意模式!和我一起说-我需要一个#假期!!这么多年来第一次在家里放松一下,这就是生活!#周末" -0.8356 "我考试前的最后一个周末" -1.3556 "真不敢相信我的假期结束了,太不公平了" 1.4312 "等不及这个周末打网球了" 3.0458 "我玩得很开心!最好的旅行!#假期#周末" -0.39243 "炎热的天气和空调在车里坏了#出汗#公路旅行#假期" 0.8028 "检查不在办公室的工作人员,我们正式在度假!!“我没想到这个周末会完全被淘汰!!”3.03“很高兴我的闺蜜这个周末来看我!” ❤ " 2.3849 "Who needs a #vacation when the weather is this good ☀ " -0.0006176 "I love meetings in summer that run into the weekend! Wait that was sarcasm. Bring on the aircon apocalypse! ☹ #weekend" 0.52992 "You know we all worked hard for this! We totes deserve this #vacation Ibiza ain’t gonna know what hit em " ⋮
情感词典阅读功能
此函数从情感词典中读取积极和消极单词,并返回一个表。该表包含变量词和标签,在那里标签包含分类值积极乐观的和消极的对应着每一个字的感情。
函数data = readLexicon阅读积极的词汇fidPositive = fopen (fullfile (“意见词汇英语”,'positive words.txt'));C = textscan (fidPositive' % s ',“CommentStyle”,“;”); wordsPositive=字符串(C{1});%读否定词fidNegative = fopen (fullfile (“意见词汇英语”,“negative-words.txt”)); C=文本扫描(FID阴性,' % s ',“CommentStyle”,“;”);wordsNegative =字符串(C {1});文件关闭所有;%创建标签单词表单词=[单词正;单词负];标签=分类(nan(numel(单词),1));标签(1:numel(wordsPositive))=“积极的”;标签(元素个数(wordsPositive) + 1:结束)=“负面”; 数据=表格(文字、标签、,“变化无常”,{“词”,“标签”});终止
预处理功能
这个函数preprocessText执行以下步骤:
使用标记文本
tokenizedDocument.删除标点符号使用
erasePunctuation.去掉“and”、“of”和“the”等停止词
removeStopWords.使用
较低的.
函数文件= preprocessText (textData)标记文本。文件= tokenizedDocument (textData);%擦掉标点符号。= erasePunctuation文件(文档);删除一个停止词列表。文件=删除文字(文件);%转换成小写。文件=低(文件);终止
参考文献
胡民清,刘冰。“挖掘并总结客户评论。”在第十届美国计算机学会SIGKDD知识发现和数据挖掘国际会议论文集, 168 - 177页。ACM, 2004年。
另见
tokenizedDocument|巴格沃兹|erasePunctuation|移除词|removeStopWords|wordcloud|word2vec|fastTextWordEmbedding
相关的话题
你也可以从以下列表中选择一个网站:
