使用文本散点图可视化单词嵌入
这个例子展示了如何使用2-D和3-D t-SNE和文本散点图来可视化单词嵌入。
单词嵌入将词汇表中的单词映射到实向量。这些向量试图捕捉单词的语义,以便相似的单词有相似的向量。一些嵌入语也捕捉到了单词之间的关系,比如“意大利之于法国,正如罗马之于巴黎”。在向量形式中,这个关系是 .
加载预先训练的词嵌入
加载一个预先训练的词嵌入使用fastTextWordEmbedding.此功能需要文本分析工具箱™模型用于快速文本英语160亿令牌词嵌入金宝app支持包。如果没有安装此支金宝app持包,则该函数将提供下载链接。
emb = fastTextWordEmbedding
emb = wordem寝具属性:Dimension: 300 Vocabulary: [1×999994 string]
探索单词嵌入使用word2vec和vec2word.把单词意大利,罗马,巴黎向量使用word2vec.
意大利= word2vec (emb,“意大利”);罗马= word2vec (emb,“罗马”);巴黎= word2vec (emb,“巴黎”);
计算给出的向量意大利-罗马+巴黎.这个向量封装了单词的语义意大利,没有这个词的语义罗马,也包括该词的语义巴黎.
Vec =意大利-罗马+巴黎
vec =1×300单行向量0.1606 -0.0690 0.1183 -0.0349 0.0672 0.0907 -0.1820 -0.0080 0.0320 -0.0936 -0.0329 -0.1548 0.1737 -0.0937 - 0.01619 0.0777 -0.0843 0.0066 0.0600 -0.2059 -0.0268 0.1350 -0.0900 0.0314 0.0686 -0.0338 0.1841 0.1708 0.0276 0.0719 -0.1667 0.0231 0.01773 -0.1135 0.1018 -0.2339 0.1008 0.1057 -0.1118 0.2891 -0.0358 0.0911 -0.0958 -0.0184 0.0740-0.1081 0.0826 0.0463 0.0043
找出最接近的嵌入词vec使用vec2word.
词= vec2word (emb vec)
词=“法国”
创建2d文本散点图
通过使用创建一个二维文本散点图来可视化单词嵌入tsne和textscatter.
将前5000个单词转换为向量word2vec.V是一个长度为300的字向量矩阵。
话说= emb.Vocabulary (1:5000);V = word2vec (emb,单词);大小(V)
ans =1×25000 300
将单词向量嵌入到二维空间中tsne.运行此函数可能需要几分钟。如果要显示收敛信息,请设置“详细”名称-值对为1。
XY = tsne (V);
在指定的坐标处绘制单词XY在二维文本散点图中。为了可读性,textscatter,默认情况下不显示所有输入单词,而是显示标记。
图textscatter (XY,话说)标题(单词嵌入t-SNE图)

放大情节的一部分。
ylim([-18 -5]) [11 21]

创建3d文本散点图
通过使用创建一个3-D文本散点图来可视化单词嵌入tsne和textscatter.
将前5000个单词转换为向量word2vec.V是一个长度为300的字向量矩阵。
话说= emb.Vocabulary (1:5000);V = word2vec (emb,单词);大小(V)
ans =1×25000 300
将单词向量嵌入到三维空间中tsne通过指定维数为3。运行此函数可能需要几分钟。如果要显示收敛信息,可以设置“详细”名称-值对为1。
XYZ = tsne (V,“NumDimensions”3);
在3d文本散点图中,在XYZ指定的坐标处绘制单词。
figure ts = textscatter3(XYZ,words);标题(三维词嵌入t-SNE图)

放大情节的一部分。
xlim ([12.04 - 19.48]) ylim ([-2.66 - 3.40]) zlim ([10.03 - 14.53])

进行聚类分析
将前5000个单词转换为向量word2vec.V是一个长度为300的字向量矩阵。
话说= emb.Vocabulary (1:5000);V = word2vec (emb,单词);大小(V)
ans =1×25000 300
发现25个集群kmeans.
cidx = kmeans (V, 25岁,“距离”,“sqeuclidean”);
使用前面计算的二维t-SNE数据坐标在文本散点图中可视化集群。
图textscatter (XY,话说,“ColorData”分类(cidx));标题(单词嵌入t-SNE图)
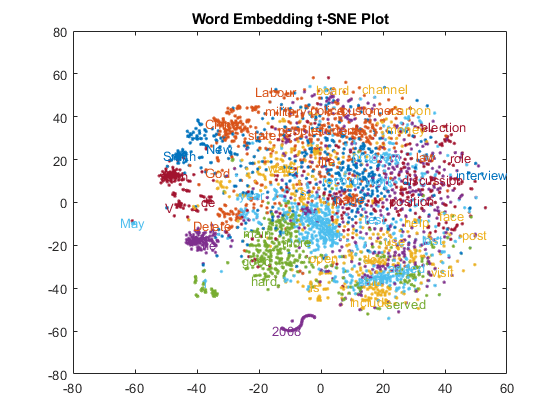
放大情节的一部分。
ylim([-47 -35])

另请参阅
readWordEmbedding|textscatter|textscatter3|tokenizedDocument|vec2word|word2vec|wordEmbedding
相关的话题
你也可以从以下列表中选择一个网站:
