 克利夫角:克利夫莫勒的数学和计算
克利夫角:克利夫莫勒的数学和计算 MATLAB博客
MATLAB博客 用MATLAB进行图像处理
用MATLAB进行图像处理 Simulin金宝appk上的Guy
Simulin金宝appk上的Guy 人工智能
人工智能 开发区域
开发区域 Stuart的MATLAB视频
Stuart的MATLAB视频 头条新闻背后
头条新闻背后 本周文件交换选择
本周文件交换选择 汉斯谈物联网
汉斯谈物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 Matlabユザコミュニティ
Matlabユザコミュニティ 创业公司、加速器和企业家
创业公司、加速器和企业家 自治系统
自治系统神经网络特征可视化
网络学习的数据和语义内容的可视化
这篇文章来自Maria Duarte Rosa,她将讨论将网络学习的特征可视化的不同方法。 今天,我们来看看用两种方法来洞察网络的两种方法:再邻居而且t-SNE,我们将在下面详细描述。
使用t-SNE的训练网络的可视化
数据集和模型
在这两个练习中,我们都会用到ResNet-18,以及我们最喜欢的食物数据集,你可以在这里下载.(请注意,这是一个非常大的下载。我们只是举个例子,因为食物和每个人都有关系!这段代码应该适用于任何其他数据集)。网络已经重新训练从数据中识别出5类对象:| 沙拉 | 披萨 | 薯条 | 汉堡 | 寿司 |
 |
 |
 |
 |
 |
k近邻搜索
最近邻搜索是一种优化问题,其目标是找到空间中与给定点最接近(或最相似)的点。k近邻搜索识别特征空间中与点最近的k个近邻。度量空间中的接近度通常使用距离度量来定义,例如欧几里得距离或闵可夫斯基距离。点越相似,这段距离就越小。这种技术通常被用作机器学习分类方法,但也可以用于神经网络的数据可视化和高级特征,这就是我们要做的事情。让我们从食物数据集中的5张测试图像开始:idxTest = [394 97 996 460 737];im = imtile(string({imdsTest.Files{idxTest}}),'ThumbnailSize',[100 100], 'GridSize', [5 1]);

dataTrainFS =激活(netFood, imdsTrainAu, 'data', 'OutputAs', 'rows');imgFeatSpaceTest =激活(netFood, imdsTestAu,'data', 'OutputAs', 'rows');dataTestFS = imgFeatSpaceTest(idxTest,:);创建KNN模型并搜索最近的邻居
Mdl = createns(dataTrainFS,'Distance','euclidean');idxKnn = knnsearch(Mdl,dataTestFS, 'k', 10);
 在像素空间中搜索相似性通常不会返回关于图像语义内容的任何有意义的信息,而只能返回像素强度和颜色分布的相似性。数据(像素)空间中10个最近的邻居不一定与测试图像对应同一类。没有“学习”发生。看看第四行:
在像素空间中搜索相似性通常不会返回关于图像语义内容的任何有意义的信息,而只能返回像素强度和颜色分布的相似性。数据(像素)空间中10个最近的邻居不一定与测试图像对应同一类。没有“学习”发生。看看第四行:
dataTrainFS =激活(netFood, imdsTrainAu, 'pool5', 'OutputAs', 'rows');imgFeatSpaceTest =激活(netFood, imdsTestAu,'pool5', 'OutputAs', 'rows');dataTestFS = imgFeatSpaceTest(idxTest,:);创建KNN模型并搜索最近的邻居
Mdl = createns(dataTrainFS,'Distance','euclidean');idxKnn(:,:) = knnsearch(Mdl,dataTestFS, 'k', 10);

第一列(突出显示)是测试图像,其余列是10个最近的邻居
K-NN:我们能从中学到什么?
这可以证实我们期望从网络中看到什么,或者只是以一种新的方式对网络进行另一种可视化。如果网络的训练精度很高,但特征空间中最近的邻居(假设特征是网络最后一层的输出)不是来自同一类的对象,这可能表明网络没有捕获任何与类相关的语义知识,但可能已经学会了基于训练数据的一些工件进行分类。基于t-SNE的语义聚类
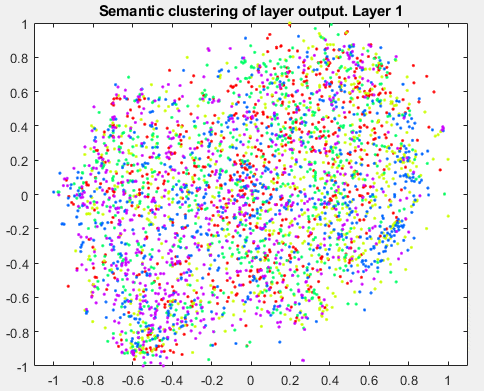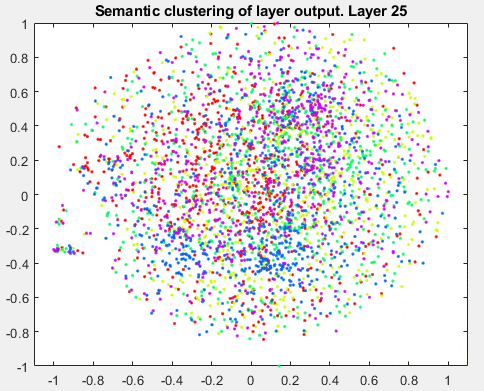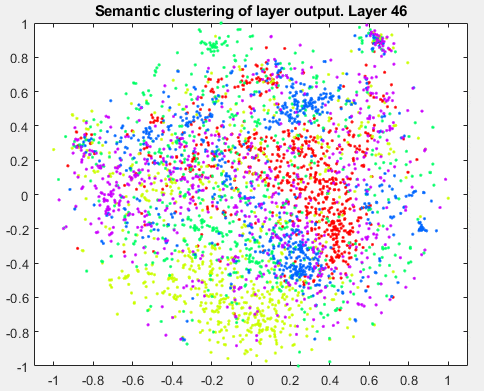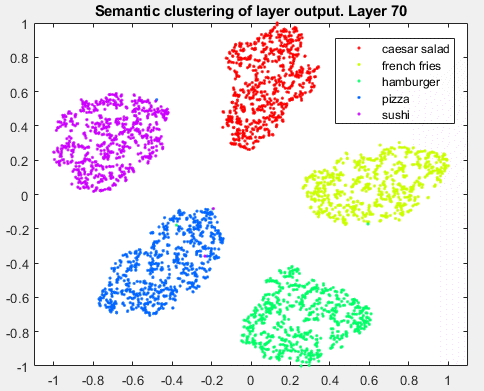
t-分布式随机邻居嵌入(t-SNE)是一种非线性降维技术,允许将高维数据嵌入到低维空间中。(通常我们选择低维空间为二维或三维,因为这便于绘图和可视化)。低维空间的估计方法是保持与高维空间的相似性。换句话说,两个相似的物体在低维空间中有很大的概率是附近的,而两个不同的物体应该用遥远的点来表示。该技术可用于深度神经网络特征的可视化。让我们将这种技术应用于数据集的训练图像,并获得数据的二维和三维嵌入。与k-nn示例类似,我们将从可视化原始数据(像素空间)和最终平均池化层的输出开始。Layers = {'data', 'pool5'};for k = 1:length(layers) dataTrainFS =激活(netFood, imdsTrainAu, layers{k}, 'OutputAs', 'rows');AlltSNE2dim(:,:,k) = tsne(dataTrainFS);AlltSNE3dim(:,:,k) = tsne(dataTrainFS), 'NumDimensions', 3);图;gscatter(AlltSNE2dim(:,1,1), AlltSNE2dim(:,2,1), labels);title(sprintf('语义聚类- %s层',层{1}));gscatter(AlltSNE2dim(:,1,end), AlltSNE2dim(:,2,end), labels);title(sprintf('语义聚类- %s层',layers{end}));图; subplot(1,2,1);scatter3(AlltSNE3dim(:,1,1),AlltSNE3dim(:,2,1),AlltSNE3dim(:,3,1), 20*ones(3500,1), labels) title(sprintf('Semantic clustering - %s layer', layers{1})); subplot(1,2,2);scatter3(AlltSNE3dim(:,1,end),AlltSNE3dim(:,2,end),AlltSNE3dim(:,3,end), 20*ones(3500,1), labels) title(sprintf('Semantic clustering - %s layer', layers{end}));
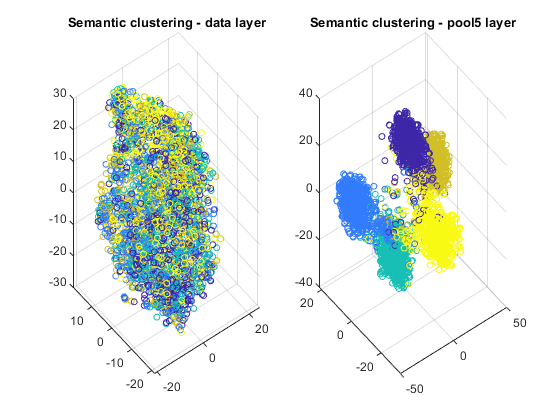
错误语义聚类中的图像示例
让我们仔细看看pool5层的2D图像,并放大一些错误分类的图像。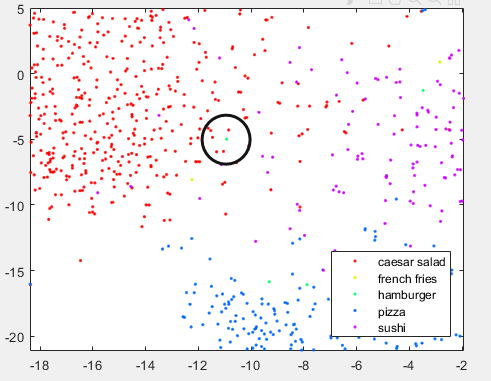 |
 |
im = imread(imdsTrain.Files{1619});标题(“看起来像沙拉的汉堡”);
 沙拉堆里的汉堡。与其他汉堡图片不同的是,照片中有大量的沙拉,没有面包或小圆面包。
沙拉堆里的汉堡。与其他汉堡图片不同的是,照片中有大量的沙拉,没有面包或小圆面包。
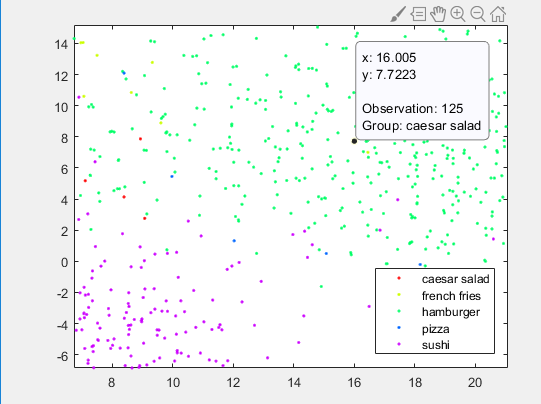
im = imread(imdsTrain.Files{125});标题(“看起来像汉堡包的凯撒沙拉”);. 汉堡堆里的沙拉。这可能是因为图像背景中包含一个面包或面包。
汉堡堆里的沙拉。这可能是因为图像背景中包含一个面包或面包。
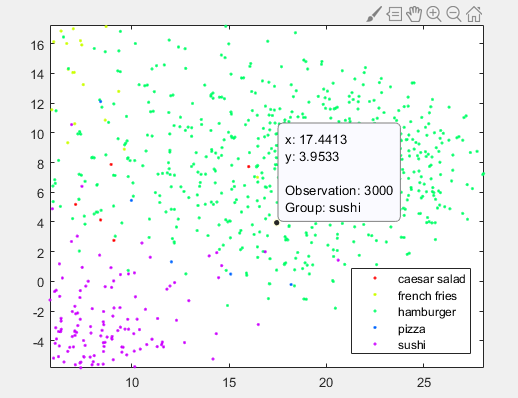
im = imread(imdsTrain.Files{3000});imshow(im);title('看起来像汉堡包的寿司');

版权所有2018 The MathWorks, Inc.
获取MATLAB代码
- 类别:
- 深度学习







评论
要发表评论,请点击此处登录到您的MathWorks帐户或创建一个新帐户。