 克利夫角:克利夫莫勒的数学和计算
克利夫角:克利夫莫勒的数学和计算 MATLAB博客
MATLAB博客 用MATLAB进行图像处理
用MATLAB进行图像处理 Simulin金宝appk上的Guy
Simulin金宝appk上的Guy 人工智能
人工智能 开发区域
开发区域 Stuart的MATLAB视频
Stuart的MATLAB视频 头条新闻背后
头条新闻背后 本周文件交换选择
本周文件交换选择 汉斯谈物联网
汉斯谈物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 Matlabユザコミュニティ
Matlabユザコミュニティ 创业公司、加速器和企业家
创业公司、加速器和企业家 自治系统
自治系统 定量金融学
定量金融学将您的深度学习研究从桌面扩展到云
实现头颈部肿瘤分割的多个AI实验
以下文章来自MathWorks的应用工程师Arnie Berlin概述
随着深度学习在越来越多的科学和工程学科中的推广,需要在这一领域支持实验性和可扩展的工作流。金宝app它们本质上是联系在一起的。与弗赖堡大学医学研究团队合作,研究mri用于自动化头颈部肿瘤分割[1],我协助他们开发了深度学习工作流。这项研究的目的是帮助放射科医生进行比目前更快、更准确的诊断。研究小组收集了一个患者数据集,其中包括每个患者扫描的7个相应的MRI数据。每组扫描可以非常大,大约为33.6 MBytes。研究人员想问的问题是,这些模式中哪一种影响最大,哪一种影响最小?答案将允许他们减少数据大小,从而减少训练的时间和成本。
这篇博客将讨论实现工作流的细节,以及从桌面计算机扩展到AWS云计算机的注意事项。研究人员问题的性质需要在大型数据集上进行多次深度学习训练的试验。他们需要能够在廉价的单GPU计算机和详尽的实验上运行小型实验,即在强大的多GPU计算机配置上进行多次试验。
分析分析
模式是不同的MRI操作模式,将与深度学习空间中的通道一致。研究人员确定影响最小和最大的模式的过程是留一分析(LOO)。这个概念是训练和测试一个深度学习模型,包括所有的模态数据,每个模态轮流被忽略。这个分析总共需要8次训练和测试运行。
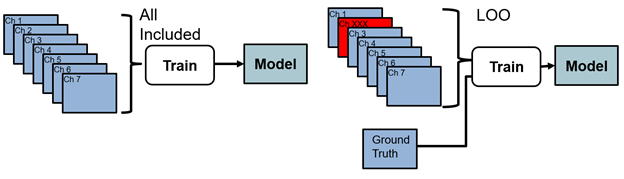
图1。左一出通道的描述
每组患者数据也需要同样的分析。每个文件都需要轮流被忽略,并成为交叉引用的测试数据。共有36个患者数据集。现在,对于每个遗漏的文件,8次训练运行中的每一次都乘以36次,因此总共有288次训练和测试运行或实验试验。
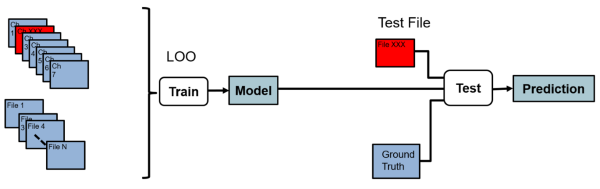
图2。通道和文件的左出描述。用于测试的空白文件
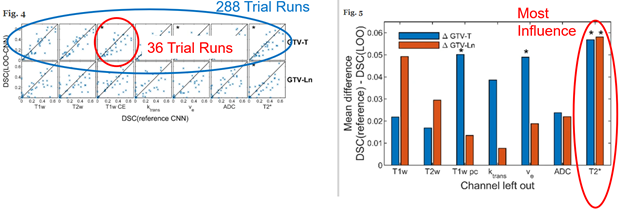
图3。最终研究结果:左图显示每个通道36次试验的分组。右边的图表显示了汇总结果,其中值越高结果越好。
最终详尽的实验设置和成本
为了完成这一详尽的训练,分析被分散在AWS上并行运行的6个计算实例上。在AWS平台上,实例是单个计算机配置。弗莱堡团队首先在许多训练运行中试验了更昂贵的P3实例类型,然后才了解到g4dn可能是一个成本更低的替代方案。该团队选择使用g4dn类型。g4dn配备了单个Nvidia Tesla T4 GPU。每次试验耗时约4小时,完成288次试验耗时8天。每个实例节点每小时0.56美分,成本为1400美元。这可能不是太不合理,但它花费了大量的时间和失败的实验来构建工作流,确定最佳配置,数据存储选项,并确定最佳的深度学习参数。每个训练实验1000美元,更不用说等待完成的几天时间,很快就会成为预算克星。
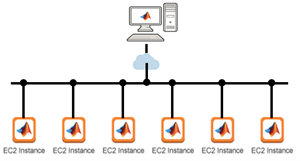
图4。描述弗莱堡大学的AWS配置为最终的实验运行
它需要多次调优才能达到最终的训练。了解云上的不同选项以及如何实现可伸缩的系统和工作流,可以最大限度地减少彻底培训的成本。大量的培训工作需要尽量减少昂贵设备上的时间,并尽量减少等待完成的工程时间。有关于数据存储选项的实验,最小化大型数据集的读取时间,网络模型,数据预处理和增强,计算机配置可以处理多大的小批量,图像和图像补丁大小,以及学习超参数。弗莱堡的团队在更昂贵的P3和g4dn之间的实验就是这样一个例子。
工作流
利用Deep network Designer构建原型模型
另一个实验阶段是选择网络模型。该团队已经注意到一个名为DeepMedic[2]的最新模型,该模型在脑组织上取得了一些成功。他们与UNet模型进行了初步的实验比较,发现DeepMedic需要的资源更少,这有望缩短训练时间。该团队选择使用DeepMedic模型的两个输入版本,其中两个输入都是从相同的接受野中提取的,但其中一个被处理为次采样,分辨率较低。因此,低层和高层细节都可以在更紧凑的模型中对预测做出贡献。在重新组合路径之前,对下采样路径进行上采样。最终输出类似于仅编码的语义分割模型。为了在原始数据上提供输出类的覆盖,输出必须按比例缩放到原始数据大小。请看下图的描述。

图5。两个输入DeepMedic网络模型的描述
我们发现我们可以用一个输入实现架构,并使用自定义裁剪层将其分成两个路径。
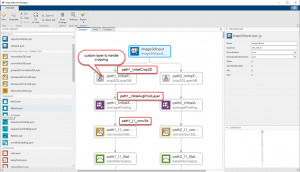
图6。深度网络设计器屏幕截图(点击放大)
由于模型很大,并且有许多重复的部分,因此可以在构建过程的早期阶段导出它,然后可以直接编辑脚本,使得复制、粘贴和名称替换工作更加容易。当重复的部分完成时,可以运行脚本在工作空间中生成一个模型,以便导入回设计器完成。
开发用于管理训练和测试数据的数据存储和转换函数
管理和操作用于深度学习的数据集是非常具有挑战性和耗时的。MATLAB使用数据存储对象来促进深度学习。对象和相关构造支持预处理和后处理、增强、后台处理和分发到并行节点和gp金宝appu。看到从数据存储开始.创建了每个患者的文件夹层次结构及其每次扫描事件的成像文件。每个MRI扫描事件包含7种不同对比的形态加上真实数据。每次扫描都包含不同数量的切片和不同的分辨率。金宝搏官方网站如前所述,该团队能够实现他们自己的注册和规范化方法,但这超出了本文的范围。imageDatastore用于访问数据。由于文件夹重载了多个数据表示,并且只需要规范化的文件,因此将数据存储列表过滤为包含'规范化'字符串的文件,并从结果列表重建数据存储。

使用数据存储子集方法将较大的数据存储进一步细分为训练、验证和测试数据集。

训练所需的图像大小约为165x165x9体素x 7个通道,这比每个文件中的数据要小得多。分辨率需要保留,否则会丢失太多信息。对于语义分割问题,通常是从匹配训练输入大小的输入文件中随机提取补丁。有时也需要平衡背景体素计数与前景体素,这有减少训练时间的额外好处。有一个内置的randamPatchExtractionDatastore要做类似的事情,但是需要对提取的位置、每个文件的读取数量和扩充进行更多的控制。幸运的是,数据存储变换函数允许这样做。
使用BlockedImageDatastore
研究小组发现,即使每次读取只需要一小部分,但读取整个文件会影响性能。通过从随机选择的补丁中创建新的数据集,创建了一种变通方法。在R2021a,blockedImage而且blockedImageDatastore对象的添加提高了这些操作的性能。当实例化,blockedImage将生成一个基于指定块大小的片段文件文件夹。然后只读取指定区域所需的片段。它还将为每个块片段生成掩码和像素标签统计信息,因此可以选择匹配统计元素的区域,这有助于促进训练数据的平衡。
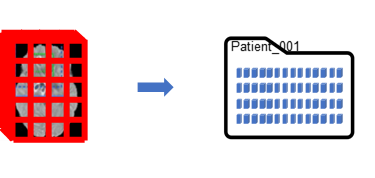
生成可视化
在执行深度学习时,可视化数据可能具有挑战性。MATLAB提供了交互式工具来支持体和叠加图形的可视化。金宝app下面是一个使用的例子蒙太奇以显示每个模态的对应切片,以及基本真相。labeloverlay用于在相应的图像上叠加分类数据。基本真相和预测分割标签通常表示为分类类型。

图7。所有7通道/模式和地面真相的中间切片蒙太奇。(点击放大图片)
Volume Viewer应用程序提供了选择和查看卷切片的功能,并提供了多种查看覆盖标签的模式。

图8。VolumeViewer App在T1通道和ground truth的Slice Planes模式和Labels模式下
使用实验管理器调整模型
在2021a之前,研究团队使用嵌套循环促进了实验,这可能是迭代训练模型的一种乏味的方式。21日之后,experimentManagerapp取代了团队最初实现的脚本,以支持围绕网络训练的贝叶斯优化和LOO工作流。金宝app该应用程序的目的是用多个变量运行实验,其中每个变量都指定了一个范围。在LOO分析所需的“扫描”模式下,它将为每个变量的排列运行训练试验。在“贝叶斯”模式下,它将根据贝叶斯优化算法对变量组合进行训练试验。下面是一个基于的示例的屏幕截图脑肿瘤三维分割与原始研究数据相似的例子。贝叶斯和LOO的应用类似。

图9。贝叶斯优化和扫描模式设置面板(点击增强图像) |
 |
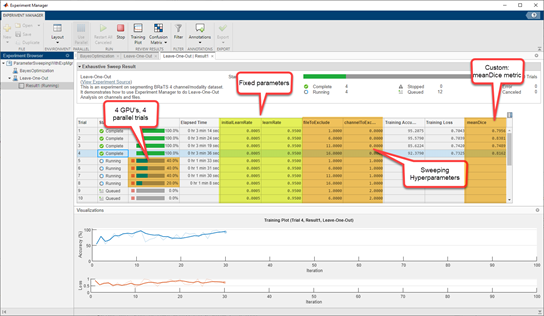
图10。分析培训
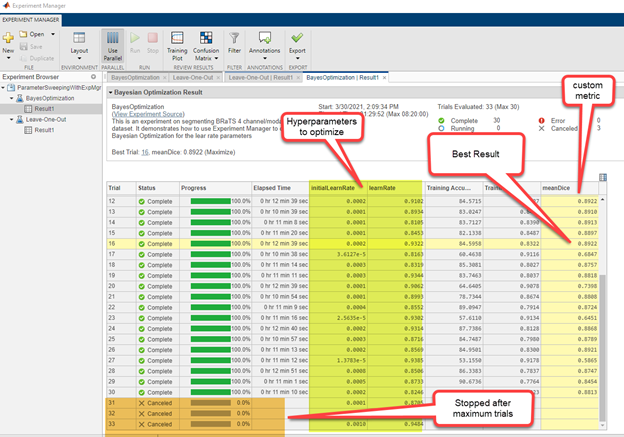
图11。贝叶斯培训。试验16学习率达到最佳效果。
从CPU扩展到gpu和云系统
其中一个挑战是拥有一个可扩展的培训环境。研究团队只能访问更强大的单gpu设备,而通过并行计算工具箱,他们可以访问AWS上的1、2、4或8个gpu设备。因此,对于一般的脚本调试和有限的培训,客户将使用他们的个人计算机;对于更费时的工作流故障排除和改进,他们会安排时间与他们内部的单gpu计算机,对于繁重的训练和贝叶斯优化,他们会瞄准基于AWS的多gpu实例。
团队决定使用RDP选项。这涉及到设置Amazon Web Service (AWS)帐户、定义EC2计算平台实例(按小时收费)以及将数据传输到弹性块存储(EBS)。初始实例是使用MATLAB参考体系结构创建的,然后可以根据用户或应用程序的需求进行修改。它可以挂载EBS,也可以作为网络存储访问S3。
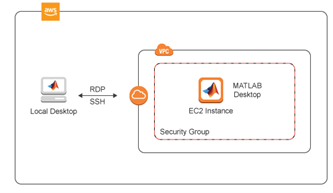
看到并行和云中扩展深度学习在文档中进行深入讨论。
一个很好的特性是计算机实例配置(和成本)在启动时很容易改变。如果训练有限,或者仍处于故障排除或优化模式,可以选择具有单个GPU模式的较小实例,或者当需要进行完整的训练时,可以选择最大的GPU,这样可以更快地完成。学习率依赖于小批大小:如果希望通过增加小批大小来使用gpu的全部资源,那么应该考虑不同的学习率。
结论
随着人工智能解决方案的新时代的到来,有很多关于金宝搏官方网站如何应用它的研究,但需要通过实验来确定最佳参数。为了得到最终的结果,我们进行了大量的实验,即理解哪种模式是重要的(见图2)。弗莱堡团队能够通过扩展到云端、利用gpu和使用各种应用程序来实现这一目标。
参考文献
[1] Bielak, L., Wiedenmann, N., Berlin, A.等人。在7通道多参数MRI上用于头颈部肿瘤分割的卷积神经网络:一种遗漏分析。Radiat Oncol 15,181(2020)。https://doi.org/10.1186/s13014-020-01618-z Kamnitsas K, Ledig C, Newcombe VFJ, Simpson JP, Kane AD, Menon DK, Rueckert D, Glocker B.高效的多尺度3D CNN,全连接CRF,用于精确的脑损伤分割。2017; 36:61-78https://doi.org/10.1016/j.media.2016.10.004 有问题要问阿尼吗?请在下方评论- カテゴリ:
- 深度学习


另请参阅
-
NGC深度学习
博客






コメント
コメントを残すには,ここをクリックしてMathWorksアカウントにサインインするか新しいMathWorksアカウントを作成します。