 克利夫角:克利夫莫勒的数学和计算
克利夫角:克利夫莫勒的数学和计算 MATLAB博客
MATLAB博客 用MATLAB进行图像处理
用MATLAB进行图像处理 Simulin金宝appk上的Guy
Simulin金宝appk上的Guy 人工智能
人工智能 开发区域
开发区域 Stuart的MATLAB视频
Stuart的MATLAB视频 头条新闻背后
头条新闻背后 本周文件交换选择
本周文件交换选择 汉斯谈物联网
汉斯谈物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 Matlabユザコミュニティ
Matlabユザコミュニティ 创业公司、加速器和企业家
创业公司、加速器和企业家 自治系统
自治系统
Kaggle数据科学竞赛入门
你是否对数据科学竞赛感兴趣,但不确定从哪里开始?今天的客座博主Toshi Takeuchi将提供一个关于如何使用MATLAB开始使用Kaggle的快速教程。

内容
Kaggle上的泰坦尼克号比赛
MATLAB对于竞争并不陌生MATLAB编程大赛持续了十多年。说到数据科学竞赛,Kaggle是目前最受欢迎的目的地之一,它提供了许多“入门101”项目,你可以在参加真正的项目之前尝试一下。其中之一就是《泰坦尼克号:灾难中的机器学习.
比赛的目标是预测泰坦尼克号上不幸乘客的生存结果。你使用训练数据来建立你的预测模型,并提交测试数据的预测生存结果。你的分数由预测的准确性决定。
如果你在这方面排名不佳,也不要担心。有带a的元素1.00000分在排行榜上,但他们要么认真overfit他们对测试数据的模型,甚至可能是欺骗,因为完整的数据集可以从其他来源获得。这不仅毫无意义,而且还提出了严重的问题——数据科学家必须达到什么样的行为标准才能产生值得信赖的结果?
所以,就把这看作是在接受真正的挑战之前在Kaggle上进行练习的一种方式吧。
如果你还没有这样做,注册Kaggle-是免费的。然后导航到《泰坦尼克号》数据网页下载以下文件:
- train.csv-培训数据
- test.csv-测试数据
数据导入和预览
我们首先将数据导入MATLAB中的表中。让我们检查导入的数据。我假设您已经将CSV文件下载到当前文件夹中。
火车=可读的(“train.csv”,“格式”,' % % f % f % q % C % % f % f % q % f % q % C ');测试=可读(“test.csv”,“格式”,' % f % f % q % C % % f % f % q % f % q % C ');disp(火车(1:5,[2:3 5:8 10:11]))
幸存Pclass性别年龄SibSp Parch票价客舱________ ______ ______ ________ _____ ______ ______ 0 3男22 1 0 7.25 " 1 1女38 1 0 71.283 'C85' 1 3女26 0 0 7.925 " 1 1女35 1 0 53.1 'C123' 0 3男35 0 0 8.05 "
火车包含列活了下来,为响应变量,表示乘客的生存结果:
1 -幸存0 -死亡
建立基线
当您从Kaggle下载数据时,您可能注意到还有其他文件可用gendermodel,genderclassmodel等。这些是简单的预测模型,根据性别或性别和阶级来决定结果。当你按性别将存活结果制成表格时,你会看到74.2%的女性存活了下来。
disp (grpstats(火车(:,{“幸存”,“性”}),“性”))
性别组计数mean_survive ______ __________ _____________女女314 0.74204男男577 0.18891
如果我们预测所有女性都能活下来,而所有男性都不能,那么我们的总体准确率将是78.68%,因为我们对女性和男性的预测都是正确的。这是基本的性别模型。我们的预测模型需要比训练数据做得更好。Kaggle的排行榜显示,该模型在测试数据上的得分为0.76555。
gendermdl = grpstats(火车(:,{“幸存”,“性”}, {“幸存”,“性”}) all_female =(性别mdl。GroupCount (“0 _male”) +性别mdl。GroupCount (“1 _female”)).../笔(gendermdl.GroupCount)
性别组计数________ ______ __________ 0_female 0 female 81 0_male 0 male 468 1_female 1 female 233 1_male 1 male 109 all_female = 0.78676
回到检查数据
当我们看火车,您可能注意到变量中缺少一些值小屋.让我们看看是否有其他变量缺少数据。我们还想检查是否有任何奇怪的值。例如,在里面看到0会很奇怪票价.当我们对火车,我们还必须应用相同的更改测试.
Train.Fare(火车。票价== 0)= NaN;%将0票价视为NaNTest.Fare(测试。票价== 0) = NaN;%将0票价视为NaNvars = Train.Properties.VariableNames;%提取列名图imagesc(ismissing(Train)) ax = gca;斧子。XTick = 1:12;斧子。XTickLabel = vars;斧子。XTickLabelRotation = 90;标题(缺失值的)

我们有177名乘客,年龄不详。有几种方法可以处理缺失值.有时您可以简单地删除它们,但是为了简单起见,在这种情况下让我们使用平均值29.6991。
avgAge = nanmean(列车年龄)平均年龄Train.Age(isnan(Train.Age)) = avgAge;将NaN替换为平均值Test.Age(isnan(Test.Age)) = avgAge;将NaN替换为平均值
avgAge = 29.699
我们有15名乘客与未知票价有关。我们知道他们的舱位,可以合理地假设票价因乘客舱位而异。
票价= grpstats(火车(:,{“Pclass”,“费用”}),“Pclass”);班级平均得分百分比disp(票价)为I = 1:身高(票价)%为每个|Pclass|%将类平均值应用于缺失值Train.Fare(火车。Pclass == i & isnan(Train.Fare)) = fare.mean_Fare(i);Test.Fare(测试。Pclass == i & isnan(Test.Fare)) = fare.mean (i);结束
Pclass GroupCount mean_Fare ______ __________ _________ 1 1 216 86.149 2 2 184 21.359 3 3 491 13.788
关于小屋你注意到有些乘客有好几个舱位,而且他们都在头等舱。我们将缺失的值视为0。一些三等舱的舱号不正常,我们需要处理这些例外情况。
%用空格标记文本字符串train_cabin = cellfun(@strsplit,火车。木屋,“UniformOutput”、假);test_cabin = cellfun(@strsplit,测试。木屋,“UniformOutput”、假);计算代币的数量火车。ncabin = cellfun(@length, train_cabin);测试。ncabin = cellfun(@length, test_cabin);处理例外情况-只有头等舱的人有多个舱位Train.nCabins(火车。Pclass ~= 1 & Train。ncabin > 1,:) = 1;Test.nCabins(测试。Pclass ~= 1 & Test。ncabin > 1,:) = 1;如果|小屋|是空的,那么| n小屋|应该是0火车。ncabin (cellfun(@isempty, Train.Cabin)) = 0;测试。ncabin (cellfun(@isempty, Test.Cabin)) = 0;
对于两名乘客,我们不知道他们的登船港。我们将使用最常见的值,年代(Southampton),从该变量中填写缺失值。我们还希望将其转换为数值变量以供以后使用。
得到最频繁的值freqVal = mode(train .);%适用于导弹值train . (isundefined(train .)) = freqVal;test . (isundefined(test .)) = freqVal;将数据类型从分类转换为双类火车。= double(train .);测试。= double(test .);
让我们把性转换为数值变量以供以后使用。
火车。性= double(Train.Sex); Test.Sex = double(Test.Sex);
让我们删除不打算使用的变量,因为它们包含太多缺失值或唯一值。
火车(:{“名字”,“票”,“小屋”}) = [];测试(:,{“名字”,“票”,“小屋”}) = [];
探索性数据分析与可视化
在这一点上,我们可以进一步开始数据探索通过可视化变量的分布。这是一个耗时但非常重要的步骤。为了简单起见,我只举一个例子年龄.直方图显示5岁以下的存活率较高,65岁以上的存活率很低。
图直方图(Train.Age(火车。幸存== 0))非幸存者的%年龄直方图持有在直方图(Train.Age(火车。幸存== 1))幸存者的%年龄直方图持有从传奇(没有生存的,“幸存”)标题(“泰坦尼克号乘客年龄分布”)

工程特性
如何利用这种可视化呢?我们可以创建一个新变量的伙伴使用离散化()将值分组到单独的箱中,如孩子,青少年等。
%组值放入单独的箱中火车。年龄Group = double(discretize(Train.Age, [0:10:20 65 80],...“分类”, {“孩子”,“青少年”,“成人”,“高级”}));测试。年龄Group = double(discretize(Test.Age, [0:10:20 65 80],...“分类”, {“孩子”,“青少年”,“成人”,“高级”}));
通过处理现有变量来创建这样一个新变量被称为工程特性这是在竞争中表现出色的关键一步,这是你的创造力真正发挥出来的地方。我们已经创建了一个新变量nCabins来处理丢失的数据,但通常您将此作为探索性数据分析的一部分。我们再来看看票价.
图直方图(Train.Fare(火车。幸存== 0));非幸存者的%票价直方图持有在直方图(Train.Fare(火车。幸存== 1),0:10:52)幸存者的%票价直方图持有从传奇(没有生存的,“幸存”)标题(“泰坦尼克号乘客票价分布”)%组值放入单独的箱中火车。票价Range = double(discretize(Train.Fare, [0:10:30, 100, 520],...“分类”, {' < 10 ',“10 - 20”,20 - 30的,“30 - 100”,“100年>”}));测试。票价Range = double(discretize(Test.Fare, [0:10:30, 100, 520],...“分类”, {' < 10 ',“10 - 20”,20 - 30的,“30 - 100”,“100年>”}));

你的秘密武器-分类学习器
的分类学习者app是一个新的基于gui的MATLAB应用程序,在R2015a统计和机器学习工具箱中引入。这将是您快速尝试不同算法的秘密武器。让我们启动它!
classificationLearner
- 点击导入数据
- 选择火车在步骤1在设置分类对话框
- 在步骤2,将“Import as”的值更改为PassengerId改为“不进口”,以及活了下来“响应”。所有其他变量都应该已经标记为预测.
- 在步骤3就顺其自然吧交叉验证.

随机森林和增强树
在这一点上,我们准备在数据集上应用一些机器学习算法。Kaggle上流行的一种算法是集成方法随机森林,可作为袋装的树木在应用程序中,让我们尝试从分类器菜单并单击火车按钮。

完成后,您可以打开混淆矩阵选项卡。你可以看到这个模型达到了83.7%的总体准确率,这比性别模型的基线要好。

提高了树是另一个在Kaggle参与者中流行的集成方法家族。你可以很容易地尝试各种选项,并在应用程序中比较结果。似乎随机森林在这里是明显的赢家。

您可以通过单击将训练过的模型保存到工作区中出口模式如果你保存模型为trainedClassifier,然后你就可以用它了测试如下。
yfit = predict(trainedClassifier, Test{:,trainedClassifier. predictornames})
您还可以通过编程方式使用TreeBagger.让我们调整数据的格式以满足其要求,并将训练数据分割为子集以进行抵抗交叉验证。
Y_train = train .幸存;%切片响应变量X_train = Train(:,3:end);%选择预测变量vars = X_train.Properties.VariableNames;%获取变量名X_train = table2array(X_train);%转换为数值矩阵X_test = table2array(Test(:,2:end));%转换为数值矩阵categoricalPredictors = {“Pclass”,“性”,“开始”,“伙伴”,“FareRange”};rng (1);再现率%c = cvpartition(Y_train,“坚持”, 0.30);% 30%-挤出量交叉验证
现在我们可以训练随机森林模型,并获得袋外采样精度度量,这类似于k倍交叉验证的误差度量。您可以从cvpartition对象生成随机索引c对训练数据集进行分区。
%从分区数据生成随机森林模型RF = TreeBagger(200, X_train(training(c),:), Y_train(training(c)),...“PredictorNames”var,“方法”,“分类”,...“CategoricalPredictors”categoricalPredictors,“oobvarimp”,“上”);计算出袋外精度oobAccuracy = 1 - oobError(RF,“模式”,“合奏”)
oobAccuracy = 0.82212
随机森林的好处之一是它的特征重要性度量,它表示在袋外采样过程中有或没有给定变量时预测误差的变化。
[~,order] = sort(RF.OOBPermutedVarDeltaError);对度量进行排序图barh (RF.OOBPermutedVarDeltaError(顺序))%横柱图标题(“功能重要性指标”) ax = gca;斧子。YTickLabel = vars(order);%变量名作为标签

正如预期的性有最强大的预测能力,但是nCabins我们提出的一个工程特性也做出了重大贡献。这就是为什么功能工程对于在竞争中取得好成绩很重要!我们还使用了相当简单的方法来填充缺失的值;在那里你也可以更有创造力。
模型评价
为了了解这个模型的实际表现如何,我们希望将其与抵抗数据进行检查。与未见过的数据相比,准确性显著下降,这就是我们向Kaggle提交预测时所期望看到的结果。
[Yfit, Yscore] = predict(RF, X_train(test(c),:));%使用保留数据cfm = confusimat (Y_train(test(c)), str2double(Yfit));混淆度矩阵cvAccuracy = sum(cfm(logical(2))))/length(Yfit))计算精度%
cvAccuracy = 0.79401
在调整特性和修改参数时,使用perfcurve情节(性能曲线或接收机工作特征图)来比较性能。这里有一个例子。
posClass = strcmp(RF。一会,' 1 ');得到正类的指数曲线= 0 (2,1);标签= cell(2,1);%预分配变量[rocX, rocY, ~, auc] = perfcurve(Y_train(test(c)),Yscore(:,posClass),' 1 ');图曲线(1)= plot(rocX, rocY);%使用perfcurve输出来绘图标签{1}= sprintf('随机森林- AUC: %.1f%%', auc * 100);曲线(结束)=反射(1,0);集(曲线(结束),“颜色”,“r”);结束标签{}=参考线-随机分类器;包含(“假阳性率”) ylabel (“真阳性率”)标题(“中华民国情节”图例(曲线,标签,“位置”,“东南”)
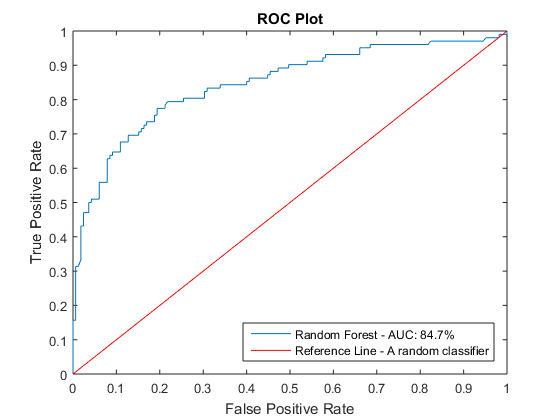
创建提交文件
要参加Kaggle比赛,你所要做的就是上传CSV文件.你只需要PassengerId而且活了下来列进行提交,然后填充活了下来有1和0。我们将使用我们建立的随机森林模型来填充这个变量。
passenger erid = test . passenger erid;%提取乘客id幸存=预测(RF, X_test);%生成响应变量幸存= str2double(幸存);%转换为doublesubmission = table(passenger erid, survive);将它们组合成一个表disp(提交(1:5)):%预览表格writetable(提交,“submission.csv”)%写入CSV文件
passenger erid幸存___________ ________ 892 0 893 0 894 0 895 0 896 0
结论-让我们试一试
当您上传提交的CSV文件时,您应该立即看到您的分数,这将在0.7940的范围内,使您进入前800名。我很肯定你看到了很大的改进空间。例如,我只是使用平均值来填充缺失的值票价但是考虑到该特性的重要性,也许您可以做得更好。也许你可以从我忽略的变量中得到更好的设计特性。
如果您想了解更多关于如何使用MATLAB开始使用Kaggle的信息,请访问我们的Kaggle页面并查看更多教程和资源。祝你好运,并告诉我们你的结果在这里!








评论
如欲留言,请点击在这里登录您的MathWorks帐户或创建一个新帐户。