 克里夫的角落:克里夫硅藻土在数学和计算
克里夫的角落:克里夫硅藻土在数学和计算 MATLAB的博客
MATLAB的博客 史蒂夫与MATLAB图像处理
史蒂夫与MATLAB图像处理 人在仿真软件金宝app
人在仿真软件金宝app 人工智能
人工智能 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 文件交换的选择
文件交换的选择 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー 创业、加速器,和企业家
创业、加速器,和企业家 自治系统
自治系统 定量金融学
定量金融学
速配实验
情人节快到了,那些关系可能会开始考虑计划。对于那些不那么幸运,请继续阅读!今天的嘉宾博客今天的嘉宾博客古原竹内,探讨了如何通过数据可以在速配成功的事件。

内容
速配数据集
我最近遇到了一个有趣的Kaggle数据集速配实验——选择恋爱对象的属性影响什么?。我从未经历过闪电约会,所以我好奇。
数据来自于一系列的异性恋速配试验从2002 - 2004年在哥伦比亚大学。在这些实验中,你每见到你们所有的人异性参与者四分钟。初次约会的数目不同的事件——平均有15个,但也可能是只有5或多达22。然后你问如果你想再次见到他们中的任何一个。你也提供评级六个属性对你的日期:
- 吸引力
- 真诚
- 情报
- 有趣的
- 雄心壮志
- 共同利益
数据集还包括参与者的偏好那些属性在不同的点在这个过程中,以及其他人口统计信息。
选择= detectImportOptions (“速配Data.csv”);%设置导入选项opts.VariableTypes([9, 38岁,50:结束])= {“双”};%对待双opts.VariableTypes([35岁,49])= {“分类”};%对待分类csv = readtable (“速配Data.csv”、选择);%导入数据csv。学费= str2double (csv.tuition);%转换为双csv。zipcode = str2double (csv.zipcode);%转换为双csv。收入= str2double (csv.income);%转换为双
参与者所期望的异性
参与者注册时填写了调查问卷,包括他们在寻找异性,他们认为别人自己的性别了。如果你把平均评级,然后减去同伴评定的自我评估,你看到参与者认为其他人更成看起来虽然他们也真诚和智慧。听起来有点偏见。我们将看到他们如何做出决策。
var = csv.Properties.VariableNames;%获得var名称(G, res) = findgroups (csv (:, {“iid”,“性别”}));%组的id和性别[idx, ~ ~] =独特(G);%获得独特的指标参照= table2array (csv (idx,包含(var,“1 _1”)));%”作为数组子集参照(isnan(参照))= 0;%南替换为0pref1_1 =词头/笔(参照2)* 100;%转换为100 - pt alloc参照= table2array (csv (idx,包含(var,“4 _1”)));%”作为数组子集参照(isnan(参照))= 0;%南替换为0pref4_1 =词头/笔(参照2)* 100;%转换为100 - pt alloc标签= {“attr”,“sinc”,“英特尔”,“有趣”,“amb”,“莎尔”};%属性图%的新人物b =酒吧([意味着(pref4_1 (res。性别= = 1:),“omitnan”)- - -…%酒吧情节意思是(pref1_1 (res。性别= = 1:),“omitnan”);…意思是(pref4_1 (res。性别= = 0:),“omitnan”)- - -…意思是(pref1_1 (res。性别= = 0:),“omitnan”)]);(1)。FaceColor = [0。45 .74];(2)。FaceColor = [。85 .33。1);脸的颜色变化百分比(1)。FaceAlpha = 0.6;(2)。FaceAlpha = 0.6;面对变化百分比α标题(“同行比你在寻找更多的异性吗?”)%添加标题xticklabels(标签)%的标签栏ylabel (差异意味着评级——同行对自我的)% y轴标签传奇(“男人”,“女性”)%添加传奇

他们能够找到匹配吗?
我们先找出那些速配活动是成功的。如果你和你的伴侣请求另一个日期后第一个,然后你有一个匹配。初始日期导致匹配的比例是多少?
- 大多数人发现匹配——中值匹配率为13%左右
- 几人非常成功,获得超过80%的匹配率
- 17 - 19%的男人和女人没有发现匹配,不幸的是
- 总之,看起来这些闪电约会事件交付承诺的结果
res.rounds = splitapply (@numel, G, G);% #初始日期res.matched = splitapply (@sum csv。匹配,G);% #匹配res.matched_r = res.matched。/ res.rounds;%匹配率边缘= [0 0.4 1:9)。/ 10;%本边缘图%的新人物直方图(res.matched_r (res。性别= = 1),边缘,…%的柱状图“归一化”,“概率”)男性匹配率%持有在%覆盖另一个阴谋直方图(res.matched_r (res。性别= = 0),边缘,…%的柱状图“归一化”,“概率”)%的女性匹配率持有从%停止覆盖标题(“第一次约会导致匹配的比例是多少?”)%添加标题包含(sprintf (“(中位数-男性% % %匹配。1 f % %,女人% .1f % %)”,…%轴标签中位数(res.matched_r (res。性别= = 1))* 100,…%值的男人中位数(res.matched_r (res。性别= = 0))* 100))%值女性xticklabels (string (0:10:90))%使用百分比xlim ([-0.05 - 0.95])%轴范围ylabel (' %参与者的)%轴标签yticklabels (string (0:5:30))%使用百分比传奇(“男人”,“女性”)%添加传奇文本(-0.04,0.21,“0比赛”)%注释

你得到更多的比赛如果你让更多的请求吗?
为了使比赛,需要请求另一个日期和得到请求接受。这意味着有些人有很高的匹配率必须要求第二次约会与几乎所有他们返回他们得到欢迎。这是否意味着少了比赛的人更挑剔,没有请求另一个日期作为经常是那些更成功吗?让我们画出请求率和匹配率——如果他们关联,那么我们应该看到一个对角线!
- 你可以看到一些相关请求率低于50%——尤其是女性。请求他们做得越多,他们似乎越匹配,一个点
- 在请求速率有明显的性别差异,女性倾向于减少请求——中值为男性44%和女性为37%
- 如果你要求每个人,里程变化——你可能仍然没有得到匹配。最后,你只会匹配,如果您的请求被接受
res.requests = splitapply (@sum, csv.dec, G);% #请求res.request_r = res.requests。/ res.rounds;%请求速率图%的新人物次要情节(2,1,1)%添加次要情节散射(res.request_r (res。性别= = 1),…男性%散点图res.matched_r (res。性别= = 1),“填充”,“MarkerFaceAlpha”,0.6)在%覆盖另一个阴谋散射(res.request_r (res。性别= = 0),…%散点图女res.matched_r (res。性别= = 0),“填充”,“MarkerFaceAlpha”,0.6)r = refline (1,0);r。颜色=“r”;r。线型=“:”;%参考线持有从%停止覆盖标题(“你得到更多的比赛如果你问更多?”)%添加标题包含(“%第二次约会请求”)%轴标签xticklabels (string (0:10:100))%使用百分比ylabel (“%匹配”)%轴标签yticklabels (string (0:50:100))%使用百分比传奇(“男人”,“女性”,“位置”,“西北”)%添加传奇次要情节(2,1,2)%添加次要情节直方图(res.request_r (res。性别= = 1),…%的柱状图“归一化”,“概率”)男性匹配率%持有在%覆盖另一个阴谋直方图(res.request_r (res。性别= = 0),…%的柱状图“归一化”,“概率”)%的女性匹配率持有从%停止覆盖标题(“女人比男人少犯的请求吗?”)%添加标题包含(sprintf (' % %(中位数-男人第二次约会请求%。1 f % %,女人% .1f % %)”,…中位数(res.request_r (res。性别= = 1))* 100,…%值的男人中位数(res.request_r (res。性别= = 0))* 100))%值女性xticklabels (string (0:10:100))%使用百分比ylabel (' %参与者的)%轴标签yticklabels (string (0:5:20))%使用百分比传奇(“男人”,“女性”)%添加传奇

决定说是第二次约会
大多数人对他们更有选择性和第二次约会。这样的决定的两个最明显的因素是他们有多喜欢他们了,他们怎么可能认为他们会得到一个“是”。是没有意义的问第二次约会的人无论你多么喜欢他或她当你觉得没有机会得到一个是的。你可以看到一个相当不错的是的,没有使用这两个因素之间的相关性。
请注意,我的评级为“喜欢”和“概率”(的是),因为实际的评定量表与人不同。你减去均值数据中心数据在零附近,然后除以标准差标准化值范围。
func = @ (x) {(x -意味着(x))。/性病(x)};% func正常化f = csv.like;%得到喜欢f (isnan (f)) = 0;%南替换为0f = splitapply(函数f, G);%正常化的组像= vertcat (f {:});%添加规范化f = csv.prob;%得到概率f (isnan (f)) = 0;%南替换为0f = splitapply(函数f, G);%正常化的组概率= vertcat (f {:});%添加规范化问题图%的新人物次要情节(1、2、1)%添加次要情节gscatter(如(csv。性别= = 1),…男性%散点图概率(csv。性别= =1),csv。dec(csv.gender == 1),rb的,“o”)标题(第二次约会的决定——男人的)%添加标题包含(“喜欢,归一化”)%轴标签ylabel (的概率得到“是”,归一化的)%轴标签ylim (5 [5])%轴范围传奇(“不”,“是的”)%添加传奇次要情节(1、2、2)%添加次要情节gscatter(如(csv。性别= = 0),…%散点图女概率(csv。性别= =0),csv。dec(csv.gender == 0),rb的,“o”)标题(“第二次约会的决定——女人”)%添加标题包含(“喜欢,归一化”)%轴标签ylabel (的概率得到“是”,归一化的)%轴标签ylim (5 [5])%轴范围传奇(“不”,“是的”)%添加传奇

影响决策的因素
如果你能猜出的概率是的,这有助于很多。我们可以做出这样的预测只使用可观察到的和发现的因素?
功能使用规范化和其他技术生成——看到的feature_eng.m为更多的细节。确定哪些特性更重要,得到的特性集被分为训练和坚持集和训练集用于生成一个随机森林模型bt_all.mat使用分类学习者应用。有什么好了随机森林它可以告诉你吗预测重要性估计基于误差增加如果你随机改变特定的预测的价值。如果他们不重要,那不应该增加出错率,对吧?
基于这些成绩,最重要的特点是:
- attrgap伙伴的吸引力——区别被参与者和他们自己的自我评价
- attr -评级的参与者给伴侣的吸引力
- 莎尔-评级的共同利益参与者给他们的伴侣
- 乐趣-评级的乐趣参与者给他们的伴侣
- field_cd——参与者的研究领域
最重要的特点是:
- agegap——参与者的年龄和他们的伴侣之间的区别
- 秩序——在这个事件的一部分,他们第一次见面,早或晚
- samerace——参与者和他们的伴侣是否相同的种族
- 阅读——阅读兴趣的参与者的评级
- race_o -合作伙伴的种族
feature_eng%工程师特性负载bt_all%负荷训练模型小鬼= oobPermutedPredictorImportance (bt_all.ClassificationEnsemble);%得到预测的重要性var = bt_all.ClassificationEnsemble.PredictorNames;%预测的名字图%的新人物次要情节(2,1,1)%添加次要情节[~,排名]=排序(imp,“下”);%获得排名酒吧(imp(等级(1:10)));%的阴谋前十名标题(“Out-of-Bag排列预测估计的重要性);%添加标题ylabel (“估计”);%轴标签包含(“十大预测”);%轴标签xticks (1:20);%设置轴蜱虫xticklabels (var(等级(1:10)))%的标签栏xtickangle (45)%旋转标签甘氨胆酸ax =;%得到当前轴斧子。TickLabelInterpreter =“没有”;%关掉乳胶次要情节(2,1,2)%添加次要情节[~,排名]= (imp)进行排序;%获得排名酒吧(imp(等级(1:10)));%的阴谋下10标题(“Out-of-Bag排列预测估计的重要性);%添加标题ylabel (“估计”);%轴标签包含(“底10预测”);%轴标签xticks (1:10);%设置轴蜱虫xticklabels (var(等级(1:10)))%的标签栏xtickangle (45)%旋转标签甘氨胆酸ax =;%得到当前轴斧子。TickLabelInterpreter =“没有”;%关掉乳胶

Validatng模型设置了抵抗
自信的预测价值,让我们检查它的预测绩效。该模型没有底部2预测-看到留存bt_45.mat以及由此产生的模型可以预测参与者的决定79.6%的准确率。比人类参与者这看起来好多了。
负载bt_45%负荷训练模型Y = holdout.dec;%地面实况X =抵抗(:1:end-1);%预测Ypred = bt_45.predictFcn (X);%的预测c = confusionmat (Y, Ypred);%得到混淆矩阵disp (array2table (c,…%显示矩阵如表“VariableNames”,{“Predicted_No”,“Predicted_Yes”},…“RowNames”,{“Actual_No”,“Actual_Yes”}));精度=总和(c(逻辑(眼(2))))/总和(和(c))%的分类精度
Predicted_No Predicted_Yes _______ _________________ Actual_No 420 66 Actual_Yes 105 246 = 0.7957精度
相对吸引力
我们发现相对吸引力的主要因素是决定说,是的。attrgap分数显示多少伙伴是相对于参与者更有吸引力。正如你所看到的,人们倾向于同意当伴侣比自己更有吸引力,不管性别。
- 这是一个两难困境,因为如果你答应的人比你更有吸引力,他们更有可能说不因为你的吸引力。
- 但如果你有可取之处的质量,如有更多共同利益或有趣,然后你可以得到是的更有吸引力的合作伙伴
- 这适用于男女双方。是我,还是像男人可能更愿意说是不那么有吸引力的合作伙伴而女性往往更容易接受有趣的伙伴吗?罗兰不确定,她认为这只是我。
图%的新人物次要情节(1、2、1)%添加次要情节gscatter (train.fun(火车。性别= =' 1 '),…%散射男性train.attrgap(火车。性别= =' 1 '),train.dec (train.gender = =' 1 '),rb的,“o”)标题(第二次约会的决定——男人的)%添加标题包含(“伙伴”年代有趣评级”)%轴标签ylabel (伙伴”年代相对Attractivenss)%轴标签ylim (4 [4])%轴范围传奇(“不”,“是的”)%添加传奇次要情节(1、2、2)%添加次要情节gscatter (train.fun(火车。性别= =' 0 '),…%散射女train.attrgap(火车。性别= =' 0 '),train.dec (train.gender = =' 0 '),rb的,“o”)标题(“第二次约会的决定——女人”)%添加标题包含(“伙伴”年代有趣评级”)%轴标签ylabel (伙伴”年代相对Attractivenss)%轴标签ylim (4 [4])%轴范围传奇(“不”,“是的”)%添加传奇

我们擅长评估自己的魅力吗?
如果相对吸引力的关键因素之一在我们的决定说“是的”,我们在评估自己的吸引力有多好?让我们来比较一下attractivess平均评级参与者的自我评估。如果减去平均评级收到自我评级,你可以看到有多少人高估自己的魅力。
- 我们通常高估自己的魅力——中值几乎是1点1 - 10的比例更高
- 男人比女人更倾向于高估
- 如果你高估了,那么你更有可能过于自信的概率你会得到“是”的答案
res.attr_mu = splitapply (@ (x)的意思是(x,“omitnan”),csv。attr_o G);%的意思是attr评级[idx, ~ ~] =独特(G);%获得独特的指标res.attr3_1 = csv.attr3_1 (idx);%删除重复的res.atgap = res.attr3_1 - res.attr_mu;%添加等级差距图%的新人物直方图(res.atgap (res。性别= = 1),“归一化”,“概率”)% histpgram男性持有在%覆盖另一个阴谋直方图(res.atgap (res。性别= = 0),“归一化”,“概率”)% histpgram女持有从%停止覆盖标题(“有多少人高估自己的魅力”)%添加标题包含([“评级差异”…%轴标签sprintf ((中位数-男性%。2 f,女人% .2f)”,…中位数(res.atgap (res。性别= = 1),“omitnan”),…中位数(res.atgap (res。性别= = 0),“omitnan”)))ylabel (' %参与者的)%轴标签传奇(“男人”,“女性”)%添加传奇

在观察者的眼中的吸引力
一个可能的原因我们不是很擅长判断自己的吸引力是,对于大多数人来说,它在旁观者的眼睛。如果你阴谋标准差评级人接受,传播很广,尤其是男性。
图res.attr_sigma = splitapply (@ (x)性病(x,“omitnan”),csv。attr_o G);%的σattr评级直方图(res.attr_sigma (res。性别= = 1),…% histpgram男性“归一化”,“概率”)举行在%覆盖另一个阴谋直方图(res.attr_sigma (res。性别= = 0),…% histpgram女“归一化”,“概率”)举行从%停止覆盖标题(吸引力评价得到的分布)%添加标题包含(吸引力评价中收到的标准差)%轴标签ylabel (' %参与者的)%轴标签yticklabels (string (0:5:30))%使用百分比传奇(“男人”,“女性”)%添加传奇

谦虚是成功的关键
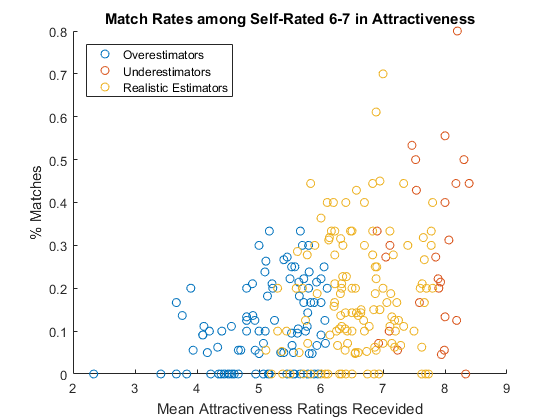
鉴于人们并不总是善于评估自己的吸引力,它是如何影响最终目标——让比赛?让我们关注平均的人(那些认为自己6或7)只有公平竞争,看看自我评价影响的结果。
- 估计吸引力的人现实,差距离均值收到评级低于0.9,相当不错
- 人们高估了表现最糟糕的
- 人们低估了最好的表现
is_realistic = abs (res.atgap) < 0.9;% lealitics估计is_over = res.atgap > = 0.9;%高估is_under = res.atgap < = -0.9;%低估is_avg = ismember (res.attr3_1者;% avg看群图%的新人物散射(res。attr_mu (is_avg & is_over),…%绘制高估res.matched_r (is_avg & is_over))在%覆盖另一个阴谋散射(res。attr_mu (is_avg & is_under),…%绘制低估res.matched_r (is_avg & is_under)散射(res。attr_mu (is_avg & is_realistic),…%绘制lealiticsres.matched_r (is_avg & is_realistic))从%停止覆盖标题(“魅力自我报告的匹配率6 - 7”)%添加标题包含(“意味着评级Recevided吸引力”)%轴标签ylabel (“%匹配”)%轴标签传奇(“Overestimators”,“Underestimators”,…。%添加传奇“现实的估计”,“位置”,“西北”)
总结
看起来你可以匹配在速配只要你适当地设置你的期望。下面是我的一些建议。
- 比人承认相对吸引力更重要,因为你不会学到很多对你的合作伙伴在四分钟。
- 但是谁有吸引力的差别很大。
- 你仍然可以做得很好如果你有更多的共同利益或更多的乐趣,所以明智地使用你的4分钟。
- 对自己的外表和适度的寻找那些对他们的相貌也谦虚,你会更有可能得到一个比赛。
我们还应该记住,数据来自那些当时去哥伦比亚——正如等变量所表明的研究领域,因此研究结果不能推广到其他的情况。
当然我也完全缺乏实践经验闪电约会,如果你这样做,请让我们知道你认为这下面的分析相比,自己的经验。






评论
留下你的评论,请点击在这里MathWorks账户登录或创建一个新的。