 Cleve’s Corner: Cleve Moler on Mathematics and Computing
Cleve’s Corner: Cleve Moler on Mathematics and Computing The MATLAB Blog
The MATLAB Blog Steve on Image Processing with MATLAB
Steve on Image Processing with MATLAB 家伙在simu金宝applink上
家伙在simu金宝applink上 深度学习
深度学习 开发人员区
开发人员区 Stuart’s MATLAB Videos
Stuart’s MATLAB Videos Behind the Headlines
Behind the Headlines File Exchange Pick of the Week
File Exchange Pick of the Week 汉斯在物联网上
汉斯在物联网上 学生休息室
学生休息室 MATLAB Community
MATLAB Community matlabユーザーコミュニティー
matlabユーザーコミュニティーClassifying old Japanese characters using CNN
吉罗‘s pick this week isCNN用于旧日本角色分类by one of my colleaguesAkira Agata.
如今,我大概走了很多天,没有看到手写的文件。从计算机和智能手机到电视和书籍,我看到的几乎每个角色都是印刷字符。因此,不时看到手写文档令人耳目一新。
Akira的演示使用深度学习(卷积神经网络)来对各种手写的日语角色进行分类。在古老的著作中,由于草书性质,这些日本角色很难破译。例如,这里有100个此类字符的样本。

乍一看,他们看起来像涂鸦。也许如果他们是句子,您也许可以通过上下文识别角色。但是,我们可以训练一个网络以纯粹识别角色吗?Akira展示了如何。
He uses a large Japanese Classics Character Dataset from Center for Open Data in Humanities. Just to show you how difficult it is even for a human, here are some of the samples from the dataset.
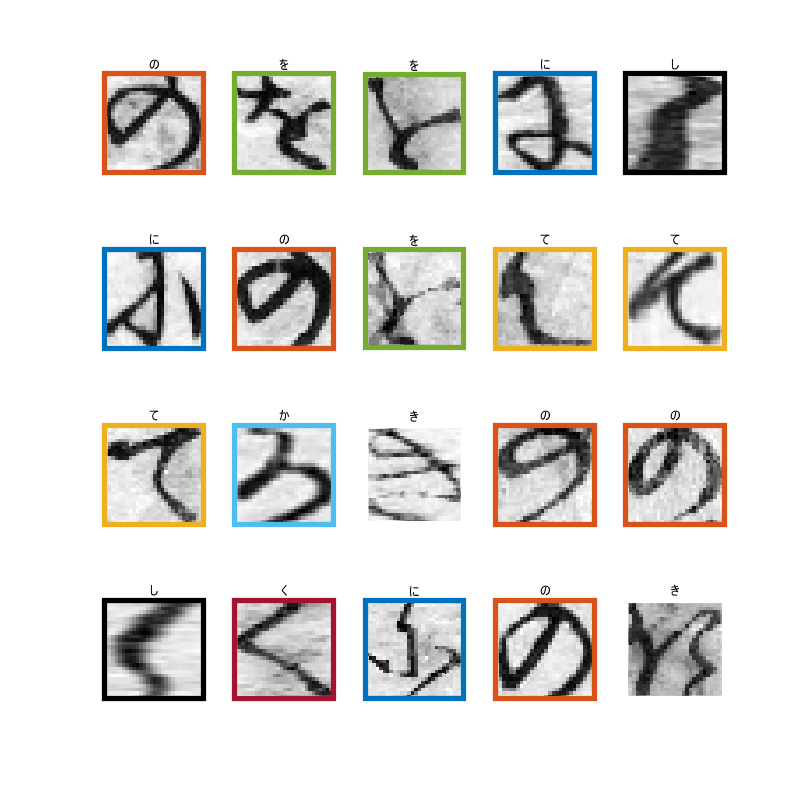
I’ve color-coded it so that the same characters are highlighted with the same color. Some look similar, but others look quite different even for the same character.
Akira uses convolutional neural network (from the深度学习Toolbox) to train a network using the character dataset. Typically, when training a network from scratch you needa lotof labeled images. No worries there. The dataset he’s using has over 20,000 images, with over 1000 images for each character he would like to classify. Training such network is very computationally expensive, so you typically want to do this withGPU或多个GPU如果有他们。但是,从R2017A开始,您可以在CPU上培训卷积神经网络。我花了10分钟多了10分钟,但是我能够使用仅CPU消费者笔记本电脑来训练网络。
Once trained, Akira tested the network against a test character set (different from the training set). His network achieved over 90% accuracy. Here are a few samples of the correctly classified characters.

Here are some of the incorrectly classifed characters.

To learn more about the process, take a look through Akira’s demo.
评论
- Category:
- Picks







评论
To leave a comment, please click这里to sign in to your MathWorks Account or create a new one.