 克里夫的角落:克里夫硅藻土在数学和计算
克里夫的角落:克里夫硅藻土在数学和计算 罗兰在MATLAB的艺术
罗兰在MATLAB的艺术 史蒂夫与MATLAB图像处理
史蒂夫与MATLAB图像处理 人在仿真软件金宝app
人在仿真软件金宝app 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 文件交换的选择
文件交换的选择 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 创业、加速器,和企业家
创业、加速器,和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー并行计算与仿真软件:运行成千上万的模拟!金宝app
更新:在MATLAB R2017a函数PARSIM介绍了。并行模拟模型更好的体验,我们建议使用PARSIM代替SIM parfor内部。看到最近的博客文章与parsim容易并行模拟模型为更多的细节。
- - - - - - - - - - - - - - - - - - -
如果你有成千上万的模拟运行,你可能会想做它尽可能快。在某些情况下,这意味着寻找更有效的建模技术,或购买一个更强大的电脑,在这篇文章中我想展示如何运行成千上万的并行模拟所有可用MATLAB工人。具体地说,这篇文章是关于如何使用并行计算工具箱,PARFOR仿真软件。金宝app
内容
高度平行的问题
PARFOR在MATLAB并行循环构造。使用并行计算工具箱,您可以启动一个本地的MATLAB的工人,或连接到一个集群运行MATLAB分布式计算服务器。一旦连接,这些PARFOR从串行执行循环自动分割成并行执行。
PARFOR使并行化通常被称为高度平行的问题。每次迭代的循环必须能够独立运行的每一个迭代循环。没有依赖的变量可以在一个循环的结果之前的循环。一些例子的仿真软件的问题,您需要执行一个参数扫描,金宝app或者运行模拟的大量的模型生成数据输出为以后分析。
计算吸引力的盆地
为了说明一个高度平行的问题,我将看看计算盆吸引一个简单的微分方程。(由于我的同事Ned给我这个例子)。

一篇关于的方程盆地Scholarpedia的吸引力。当系统集成, 两种流动状态方法。它吸引子的方法取决于初始条件的和它的导数,
两种流动状态方法。它吸引子的方法取决于初始条件的和它的导数, 。Scholarpedia文章显示如下图的分形盆地吸引这个方程。
。Scholarpedia文章显示如下图的分形盆地吸引这个方程。

(图片由Nusse阁下)
每个情节的成千上万的像素是一个模拟的结果。所以,为了使情节需要运行成千上万的模拟。
迫使阻尼摆模型
这是我的版本的微分方程模型。金宝app
open_system (“ForcedDampedPendulum”)

来看看发展随着时间的推移,这是一块100秒的模拟。(注意,我使用单命令SIM输出。)
simOut = sim卡(“ForcedDampedPendulum”,“StopTime”,“100”);y = simOut.get (“你”);t = simOut.get (“兜售”);情节(t, y)在

嵌套的循环
使用嵌套为循环,我们可以扫描的范围值和。如果我们加上上面的图中,你可以想象在流动 。我可以使用一个灰度colorbar指示的最终价值最后模拟盆地吸引力的形象。
。我可以使用一个灰度colorbar指示的最终价值最后模拟盆地吸引力的形象。
n = 5;thetaRange = linspace(π-π,n);thetadotRange = linspace (5 5 n);抽搐;为i = 1: n为j = 1: n thetaX0 = thetaRange(我);thetadotX0 = thetadotRange (j);simOut = sim卡(“ForcedDampedPendulum”,“StopTime”,“100”);y = simOut.get (“你”);t = simOut.get (“兜售”);情节(t, y)结束结束t1 = toc;colormap灰色的colorbar

我已经添加了抽搐/TOC计时代码运行这些模拟,测量时间,从这一点来看,我们可以找出每个仿真所需的时间。
t1PerSim = t1 / n ^ 2;disp ([每个仿真的时间与嵌套循环= 'num2str (t1PerSim)))
每个仿真时间与嵌套循环= 0.11862
循环期间,我只有一次遍历每个值的组合。这代表了 模拟运行需要。因为模拟都是相互独立的,这是一个完美的候选人分布并行matlab。
模拟运行需要。因为模拟都是相互独立的,这是一个完美的候选人分布并行matlab。
转换成一个PARFOR循环
PARFOR循环不能嵌套,所以迭代的初始条件需要重写为一个循环。这个问题我可以甚至再现输出图像像素网格。如果我创建一个相应的thetaX0和thetadotX0矩阵,我能够遍历元素PARFOR循环。这是一个简单的方法MESHGRID。
循环使用的另一个重要的变化ASSIGNIN函数的初始值设置状态。在PARFOR,“基地”工作区指的是MATLAB工人,模拟运行。
n = 20;[thetaMat, thetadotMat] = meshgrid (linspace(π-π,n), linspace (5 5 n));地图= 0 (n, n);抽搐;parfori = 1: n ^ 2 assignin (“基地”,“thetaX0”thetaMat(我));assignin (“基地”,“thetadotX0”thetadotMat(我));simOut = sim卡(“ForcedDampedPendulum”,“StopTime”,“100”);y = simOut.get (“你”);地图(i) = y(结束);结束t2 = toc;
我可以使用一个按比例缩小的图像来显示吸引力的盆地。(当然,这是维尔低分辨率)。
clf显示亮度图像([-ππ),5个,5个,地图)colormap(灰色),轴xy广场

的PARFOR作为一个正常的循环为循环在没有MATLAB工人。我们可以看到这个时间分析。
t2PerSim = t2 / n ^ 2;disp ([的时间每模拟PARFOR循环= 'num2str (t2PerSim)))
时间/模拟PARFOR循环= 0.13012
当地的MATLAB工人
今天大多数计算机有多个处理器,或多核架构。利用所有的核心在这台电脑上,我可以使用MATLABPOOLMATLAB命令来启动一个本地的工人。
matlabpool开放当地的nWorkers3 = matlabpool (“大小”);
matlabpool开始使用“本地”配置…连接到4实验室。
为了消除第一次从我的时间影响分析,我可以运行命令使用pctRunOnAll加载模型和模拟。
pctRunOnAll (“load_system (“ForcedDampedPendulum”)”)%的热身pctRunOnAll (“sim (“ForcedDampedPendulum”)”)%的热身
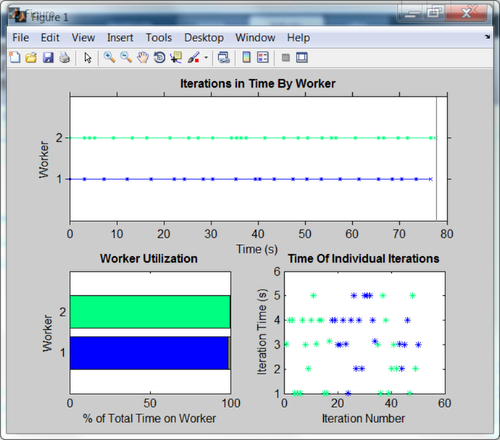
现在,让我们来测量PARFOR再循环,充分利用这台电脑上的所有核心的力量。
n = 20;[thetaMat, thetadotMat] = meshgrid (linspace(π-π,n), linspace (5 5 n));地图= 0 (n, n);抽搐;parfori = 1: n ^ 2 assignin (“基地”,“thetaX0”thetaMat(我));assignin (“基地”,“thetadotX0”thetadotMat(我));simOut = sim卡(“ForcedDampedPendulum”,“StopTime”,“100”);y = simOut.get (“你”);地图(i) = y(结束);结束t3 = toc;t3PerSim = t3 / n ^ 2;disp ([每个模拟PARFOR和时间的num2str (nWorkers3)…“工人= 'num2str (t3PerSim)]) disp ([“加速因子= 'num2str (t1PerSim / t3PerSim)])
时间/模拟PARFOR和4工人= 4.7285 = 0.025087加速因素
现在,我完成了MATLAB与当地工人,我可以发出命令来关闭它。
matlabpool关闭
发送停止信号的所有实验室……停止了。
连接到一个集群
我幸运地获得一个小的分布式计算集群,分布式计算服务器配置了MATLAB。集群由四个,四核电脑6 GB的内存。它被配置为启动一个MATLAB为每个核心员工,给予一个16节点集群。我可以重复时间的实验。
matlabpool开放Cluster16nWorkers4 = matlabpool (“大小”);pctRunOnAll (“load_system (“ForcedDampedPendulum”)”)%的热身pctRunOnAll (“sim (“ForcedDampedPendulum”)”)%的热身
matlabpool开始使用“Cluster16”配置…连接到16个实验室。
n = 20;[thetaMat, thetadotMat] = meshgrid (linspace(π-π,n), linspace (5 5 n));地图= 0 (n, n);抽搐;parfori = 1: n ^ 2 assignin (“基地”,“thetaX0”thetaMat(我));assignin (“基地”,“thetadotX0”thetadotMat(我));simOut = sim卡(“ForcedDampedPendulum”,“StopTime”,“100”);y = simOut.get (“你”);地图(i) = y(结束);结束t4 = toc;t4PerSim = t4 / n ^ 2;disp ([每个模拟PARFOR和时间的num2str (nWorkers4)…“工人= 'num2str (t4PerSim)]) disp ([“加速因子= 'num2str (t1PerSim / t4PerSim)])
时间/模拟PARFOR和16个工人= 18.3521 = 0.0064637加速因素
matlabpool关闭
发送停止信号的所有实验室……停止了。
时间总结
这是一个总结的时间测量:
disp ([每个仿真的时间与嵌套循环= 'num2str (t1PerSim)]) disp ([的时间每模拟PARFOR循环= 'num2str (t2PerSim)]) disp ([每个模拟PARFOR和时间的num2str (nWorkers3)…“工人= 'num2str (t3PerSim)]) disp ([“加速因素”num2str (nWorkers3)…当地工人= 'num2str (t1PerSim / t3PerSim)]) disp ([每个模拟PARFOR和时间的num2str (nWorkers4)…“工人= 'num2str (t4PerSim)]) disp ([“加速因素”num2str (nWorkers4)…在集群上的工人= 'num2str (t1PerSim / t4PerSim)])
时间与嵌套循环= 0.11862次/模拟/仿真与PARFOR PARFOR循环时间= 0.13012 /模拟和4工人= 0.025087加速因子4当地工人= 4.7285次/模拟PARFOR和16个工人= 0.0064637 16个工人在集群上的加速因素= 18.3521
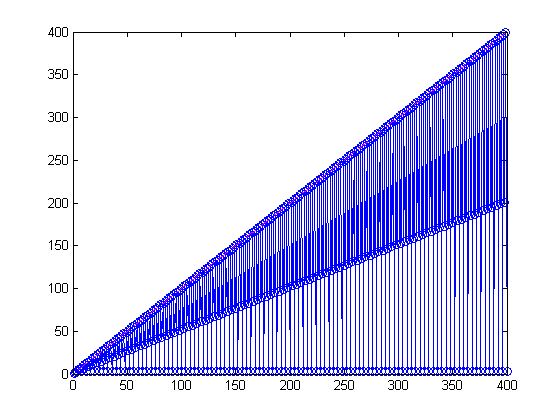
四分之一百万模拟
几个月前,我在处理这个问题,使用高性能的桌面机和4本地工人,并生成以下图。这是250000年模拟。

性能提升
有许多因素导致并行代码执行的性能。打破循环和分发工人代表一定数量的开销。对一些人来说,小问题一个小数量的工人,这个开销可以沼泽的问题。另一个需要考虑的主要因素是数据传输和网络速度;传输大量数据增加了开销,在MATLAB通常并不存在。
现在轮到你了
你有问题,可以受益于一个吗PARFOR循环和MATLAB的工人吗?留下一个这里的评论告诉我们关于这件事的一切。


另请参阅
-
parfor课程
博客
-
-



评论
留下你的评论,请点击在这里MathWorks账户登录或创建一个新的。