ClassificationTree class
Superclasses:CompactClassificationTree
Binary decision tree for multiclass classification
Description
AClassificationTreeobject represents a decision tree with binary splits for classification. An object of this class can predict responses for new data using thepredictmethod. The object contains the data used for training, so it can also compute resubstitution predictions.
Construction
Create aClassificationTreeobject by usingfitctree.
Properties
|
Bin edges for numeric predictors, specified as a cell array ofpnumeric vectors, wherep是the number of predictors. Each vector includes the bin edges for a numeric predictor. The element in the cell array for a categorical predictor is empty because the software does not bin categorical predictors. The software bins numeric predictors only if you specify the You can reproduce the binned predictor data X = mdl.X; % Predictor data Xbinned = zeros(size(X)); edges = mdl.BinEdges; % Find indices of binned predictors. idxNumeric = find(~cellfun(@isempty,edges)); if iscolumn(idxNumeric) idxNumeric = idxNumeric'; end for j = idxNumeric x = X(:,j); % Convert x to array if x is a table. if istable(x) x = table2array(x); end % Group x into bins by using the
Xbinned包含本指数,从1到怒江mber of bins, for numeric predictors.Xbinnedvalues are 0 for categorical predictors. IfXcontainsNaNs, then the correspondingXbinnedvalues areNaNs. |
|
Categorical predictor indices, specified as a vector of positive integers. |
|
Ann-by-2 cell array, where |
|
Ann-by-2 array containing the numbers of the child nodes for each node in |
|
Ann-by-karray of class counts for the nodes in |
|
List of the elements in |
|
Ann-by-karray of class probabilities for the nodes in |
|
Square matrix, where |
|
Ann-by-2 cell array of the categories used at branches in
|
|
Ann-element vector of the values used as cut points in
|
|
Ann-element cell array indicating the type of cut at each node in
|
|
Ann-element cell array of the names of the variables used for branching in each node in
|
|
Ann-element array of numeric indices for the variables used for branching in each node in |
|
Expanded predictor names, stored as a cell array of character vectors. If the model uses encoding for categorical variables, then |
|
Description of the cross-validation optimization of hyperparameters, stored as a
|
|
Ann-element logical vector that is |
|
Parameters used in training |
|
Number of observations in the training data, a numeric scalar. |
|
Ann-element cell array with the names of the most probable classes in each node of |
|
Ann-element vector of the errors of the nodes in |
|
Ann-element vector of the probabilities of the nodes in |
|
Ann-element vector of the risk of the nodes in the tree, wheren是the number of nodes. The risk for each node is the measure of impurity (Gini index or deviance) for this node weighted by the node probability. If the tree is grown by twoing, the risk for each node is zero. |
|
Ann-element vector of the sizes of the nodes in |
|
The number of nodes in |
|
Ann-element vector containing the number of the parent node for each node in |
|
Cell array of character vectors containing the predictor names, in the order which they appear in |
|
Numeric vector of prior probabilities for each class. The order of the elements of |
|
Numeric vector with one element per pruning level. If the pruning level ranges from 0 toM, then |
|
Ann-element numeric vector with the pruning levels in each node of |
|
A character vector that specifies the name of the response variable ( |
|
Ann-element logical vector indicating which rows of the original predictor data ( |
|
Function handle for transforming predicted classification scores, or character vector representing a built-in transformation function.
改变分数转换函数,佛r example,
|
|
Ann-element cell array of the categories used for surrogate splits in |
|
Ann-element cell array of the numeric cut assignments used for surrogate splits in |
|
Ann-element cell array of the numeric values used for surrogate splits in |
|
Ann-element cell array indicating types of surrogate splits at each node in |
|
Ann-element cell array of the names of the variables used for surrogate splits in each node in |
|
Ann-element cell array of the predictive measures of association for surrogate splits in |
|
The scaled |
|
A matrix or table of predictor values. Each column of |
|
A categorical array, cell array of character vectors, character array, logical vector, or a numeric vector. Each row of |
Object Functions
compact |
Compact tree |
compareHoldout |
Compare accuracies of two classification models using new data |
crossval |
Cross-validated decision tree |
cvloss |
Classification error by cross validation |
edge |
Classification edge |
gather |
Gather properties ofStatistics and Machine Learning Toolboxobject from GPU |
lime |
Local interpretable model-agnostic explanations (LIME) |
loss |
Classification error |
margin |
Classification margins |
nodeVariableRange |
Retrieve variable range of decision tree node |
partialDependence |
Compute partial dependence |
plotPartialDependence |
Create partial dependence plot (PDP) and individual conditional expectation (ICE) plots |
predict |
预测使用分类树标签 |
predictorImportance |
Estimates of predictor importance for classification tree |
prune |
Produce sequence of classification subtrees by pruning |
resubEdge |
Classification edge by resubstitution |
resubLoss |
Classification error by resubstitution |
resubMargin |
Classification margins by resubstitution |
resubPredict |
Predict resubstitution labels of classification tree |
shapley |
Shapley values |
surrogateAssociation |
Mean predictive measure of association for surrogate splits in classification tree |
testckfold |
Compare accuracies of two classification models by repeated cross-validation |
view |
View classification tree |
Copy Semantics
Value. To learn how value classes affect copy operations, seeCopying Objects.
Examples
Grow a Classification Tree
Grow a classification tree using theionospheredata set.
loadionospheretc = fitctree(X,Y)
tc = ClassificationTree ResponseName: 'Y' CategoricalPredictors: [] ClassNames: {'b' 'g'} ScoreTransform: 'none' NumObservations: 351 Properties, Methods
Control Tree Depth
You can control the depth of the trees using theMaxNumSplits,MinLeafSize, orMinParentSizename-value pair parameters.fitctreegrows deep decision trees by default. You can grow shallower trees to reduce model complexity or computation time.
Load theionospheredata set.
loadionosphere
The default values of the tree depth controllers for growing classification trees are:
n - 1forMaxNumSplits.n是the training sample size.1forMinLeafSize.10forMinParentSize.
These default values tend to grow deep trees for large training sample sizes.
Train a classification tree using the default values for tree depth control. Cross-validate the model by using 10-fold cross-validation.
rng(1);% For reproducibilityMdlDefault = fitctree(X,Y,'CrossVal','on');
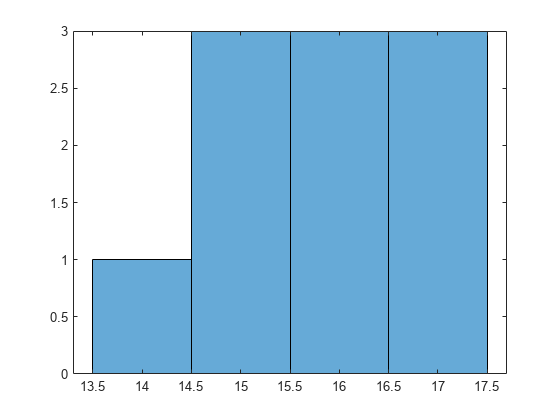
Draw a histogram of the number of imposed splits on the trees. Also, view one of the trees.
numBranches = @(x)sum(x.IsBranch); mdlDefaultNumSplits = cellfun(numBranches, MdlDefault.Trained); figure; histogram(mdlDefaultNumSplits)
view(MdlDefault.Trained{1},“模式”,'graph')
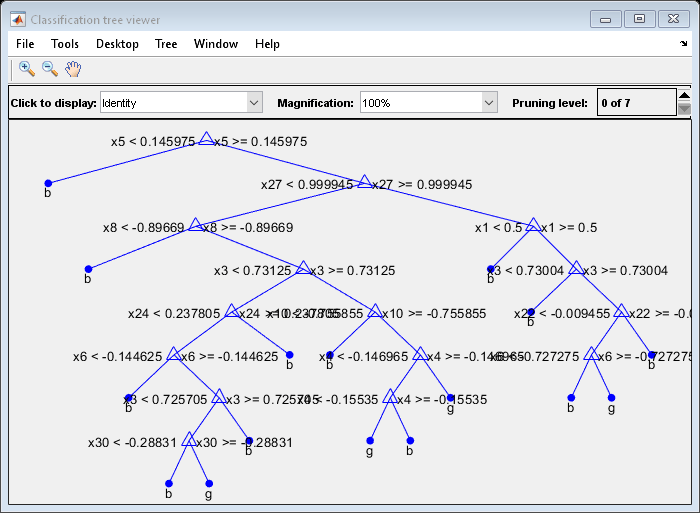
The average number of splits is around 15.
Suppose that you want a classification tree that is not as complex (deep) as the ones trained using the default number of splits. Train another classification tree, but set the maximum number of splits at 7, which is about half the mean number of splits from the default classification tree. Cross-validate the model by using 10-fold cross-validation.
Mdl7 = fitctree(X,Y,'MaxNumSplits'7'CrossVal','on'); view(Mdl7.Trained{1},“模式”,'graph')
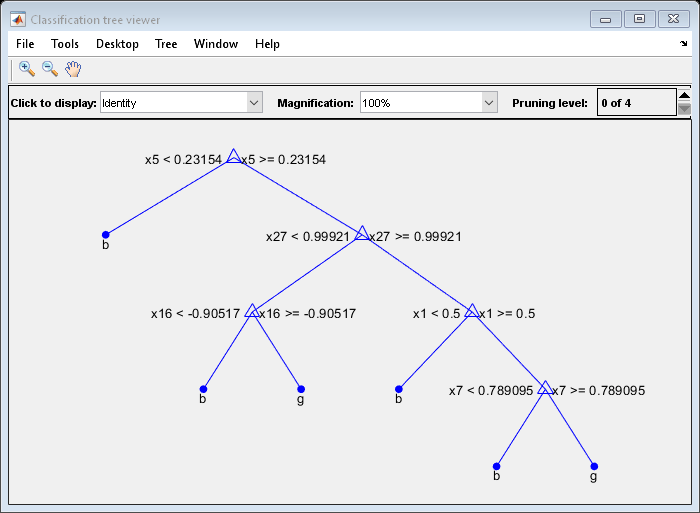
Compare the cross-validation classification errors of the models.
classErrorDefault = kfoldLoss(MdlDefault)
classErrorDefault = 0.1168
classError7 = kfoldLoss(Mdl7)
classError7 = 0.1311
Mdl7is much less complex and performs only slightly worse thanMdlDefault.
More About
References
[1] Breiman, L., J. Friedman, R. Olshen, and C. Stone.Classification and Regression Trees. Boca Raton, FL: CRC Press, 1984.
Extended Capabilities
Version History
Introduced in R2011a
You can also select a web site from the following list:
Americas
- América Latina(Español)
- Canada(English)
- United States(English)
Europe
- Belgium(English)
- Denmark(English)
- Deutschland(Deutsch)
- España(Español)
- Finland(English)
- France(Français)
- Ireland(English)
- Italia(Italiano)
- Luxembourg(English)
- Netherlands(English)
- Norway(English)
- Österreich(Deutsch)
- Portugal(English)
- Sweden(English)
- Switzerland
- United Kingdom(English)