概述
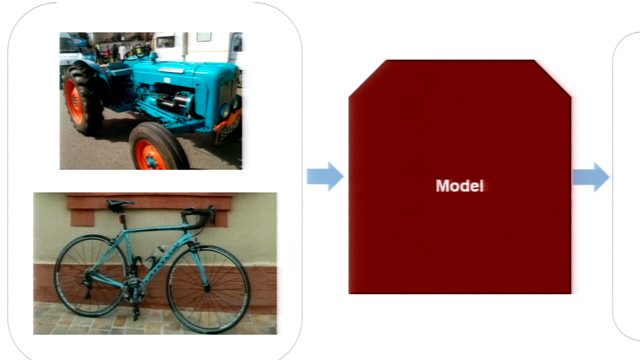
深度学习网络被证明是一种多功能工具。它们最初用于图像分类,现在越来越多地应用于各种其他数据类型。在本次网络研讨会中,我们将探讨深度学习的基础知识,为理解和使用深度神经网络处理信号数据提供基础。通过两个示例,您将看到深度学习的实际应用,提供了对大型数据集执行复杂分析的能力,而无需成为领域专家。
探索MATLAB如何解决使用cnn和LSTMs创建信号和声音系统时遇到的常见挑战,并了解信号数据深度学习的新功能。
突出了
我们将演示深度学习去噪语音信号和生成音乐曲调。您将看到如何使用MATLAB来:
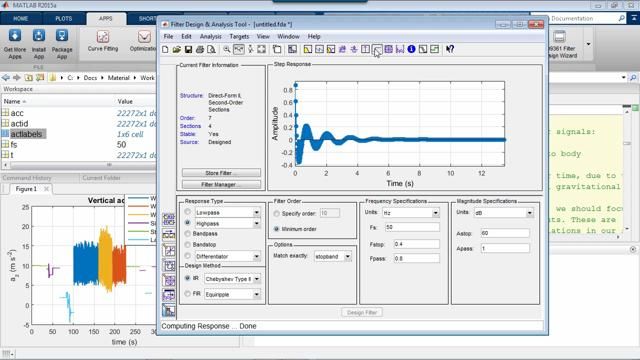
- 使用LSTM和CNN网络架构从头开始训练神经网络
- 使用频谱图和小波来创建信号的三维表示
- 访问、探索和操作大量数据
- 使用gpu可以更快地训练神经网络
关于主讲人
艾米丽·安德森是MathWorks的应用工程师,专注于MATLAB应用,如数据分析、机器学习和深度学习。在她的职位上,她支持客户在整个数金宝app据分析工作流程中适应MATLAB产品。下载188bet金宝搏她在MathWorks工作了2年,拥有隆德大学(Lund University)图像分析和信号处理硕士学位。
Johanna Pingel于2013年加入MathWorks团队,专注于图像处理和MATLAB计算机视觉应用。她拥有伦斯勒理工学院的硕士学位和卡内基梅隆大学的文学学士学位。她在计算机视觉应用领域工作了5年多,专注于目标检测和跟踪。