过度转向是一种不安全的情况,车辆的后轮在转弯时失去抓地力(图1)。它可能是由磨损的轮胎、滑的路面、转弯太快、转弯时突然刹车或这些因素的组合造成的。

图1.在测试轨道过度转向宝马M4。
现代稳定性控制系统被设计当检测到过度转向来自动采取纠正措施。从理论上讲,这样的系统可以通过使用基于第一原理数学模型识别过度转向的条件。例如,当从车载传感器测量值超过为模型中的参数建立的阈值,则系统确定汽车过度转向。然而在实践中,这种方法由于涉及的诸多因素相互作用的证明是难以实现。与充气不足的轮胎在冰路面上的一辆汽车可能需要比正常充气不足的轮胎同车的操作在干燥的表面完全不同的阈值。
在宝马,我们正在探索一种机器学习方法来检测过度转向。在MATLAB工作®我们开发了一个监督的机器学习模型作为一个概念证明。尽管有与机器学习一点以往的经验,在短短三周内我们就完成了能够检测超过98%的准确度转向过度工作ECU原型。
收集数据并提取特征
我们开始收集真实世界的数据从车辆之前,期间,和之后的过度转向。在一名专业司机的帮助下,我们在法国米拉马斯的宝马试验场对一辆宝马M4进行了现场驾驶测试(图2)。

图2. BMW证明在米拉马,法国的理由。
在测试过程中,我们在捕获转向过度检测算法通常使用信号:车辆的向前加速度,横向加速度,转向角和偏航率。此外,我们记录的转向过度的驾驶感受:当驾驶员显示汽车被转向过度,我的同事,骑在车上的乘客,压在她的笔记本电脑的按钮。她放开按钮时,驾驶员指示该车已经回到正常处理。这些按钮按下创建我们需要训练监督学习模型的地面实况标签。总之,我们捕获约43分钟记录一次数据的259,000个数据点。
回到我们的慕尼黑办公室,我们装,我们已经收集到MATLAB和使用各种分类的使用统计和机器学习工具箱™分类学习应用列车机器学习模型中的数据。由受过训练的有关此原始数据模型所产生的结果是不突出-准确度为75%和80%之间。为了实现更精确的结果,我们清理和减少了原始数据。首先,我们应用的过滤器,以减少噪声的信号的数据(图3)。
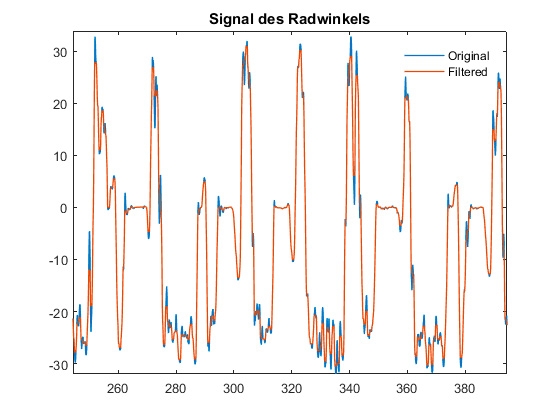
图3。原始的转向角信号(蓝色)和过滤后的相同信号(橙色)。
接下来,我们使用峰值分析来识别经过筛选的输入信号的峰值(局部最大值)(图4)。
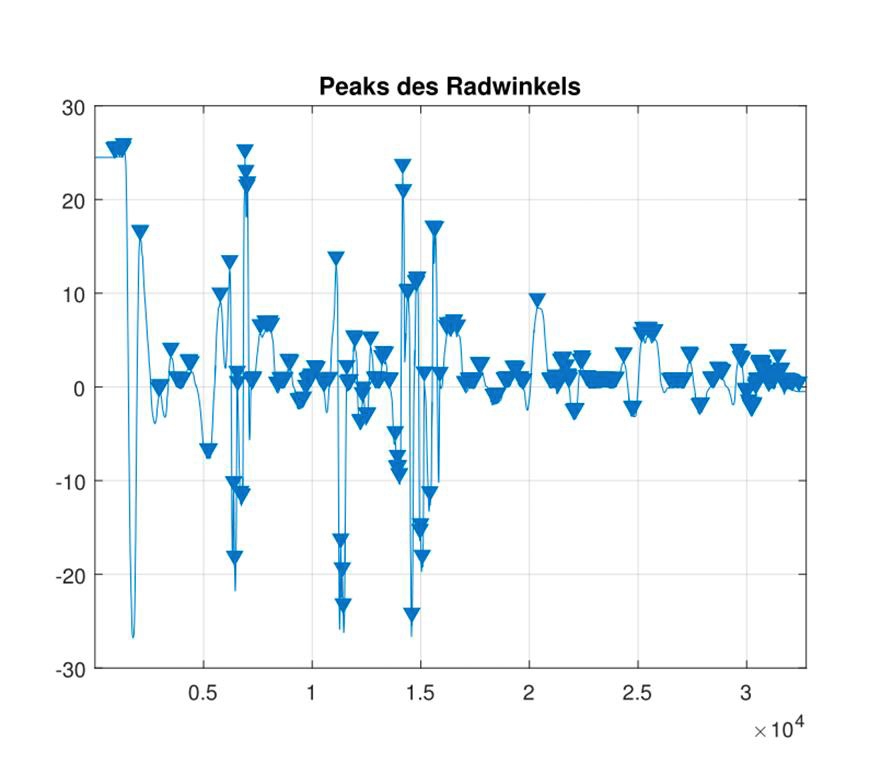
图4.与鉴定的峰的转向角信号。
评估机器学习方法
在过滤和减少收集的数据后,我们可以更好地评估监督机器学习方法。使用分类学习应用,我们尝试了k近邻(KNN)分类器、支持向量机(SVMs)、二次判别分析和决策树。金宝app我们还使用了应用程序,通过主成分分析(PCA)来观察特征转换的效果,这有助于防止过度拟合。
我们评估的分类器产生的结果汇总在表1中。所有的分类器在识别过度转向方面表现良好,其中有3个产生了98%以上的真实阳性率。决定因素是真实的负利率:分类器能够多准确地确定什么时候车辆不转向过度。在这里,决策树跑赢其它分类,有近96%是真阴性率。
| 真阳性(%) | 真阴性(%) | 假阳性(%) | 假阴性(%) | |
| 使用PCA的k近邻 |
94.74 | 90.35 | 5.26 | 9.65 |
| 金宝app支持向量机 | 98.92 | 73.07 | 1.08 | 26.93 |
| 二次判别分析 | 98.83 | 82.73 | 1.17 | 17.27 |
| 决策树 | 98.16 | 95.86 | 1.84 | 4.14 |
为车内测试生成代码
由决策树产生的结果是有希望的,但真正的考验将是一个真正的汽车分类上的ECU如何执行。我们生成的代码从MATLAB编码器™模型,并编制了我们的目标ECU代码,安装在BMW 5系轿车。这一次,我们进行了在宝马工厂附近阿舍姆测试自己,贴近我们的办公室。我开车,我的同事收集的数据,记录了精确的时间,当我表示,这辆车是转向过度。
该分类器在ECU上实时运行,其性能出奇地好,准确率约为95%。进入测试时,我们不知道会发生什么,因为我们使用的是不同的车辆(宝马5系列,而不是M4)、不同的驾驶员和不同的赛道。仔细观察数据就会发现,模型和驾驶员感知的过度转向之间的大部分不匹配都发生在过度转向状态的开始和结束附近。这种不匹配是可以理解的;即使是司机也很难准确地判断过度转向是何时开始和停止的。
在成功开发了转向过度检测机器学习模型,并将其部署在原型ECU,我们现在设想在BMW机器学习许多其他潜在的应用。提供给我们,今天收集了几十年的数据海量,单个车辆可以生成测量数据在一天一万亿字节。机器学习提供了开发使用现有数据来了解驾驶员的行为,提高了驾驶体验软件的机会。