强化学习必须解决许多应用,包括工业自动化,自动驾驶,视频游戏,计算机和机器人艰难决策问题的潜力。
强化学习是一种机器学习,在这种机器学习中,计算机通过与动态环境的重复交互来学习执行任务。这种反复试验的学习方法使计算机能够在没有人工干预的情况下做出一系列决策,而且不需要明确地编写执行任务的程序。一个著名的强化学习实例是AlphaGo,它是第一个在围棋比赛中击败世界冠军的计算机程序。
强化学习与数据的作品从一个动态的环境,换句话说,与变化基于外部条件,如天气或交通流数据。加强学习算法的目标是找到一种策略,将产生最佳结果。该办法强化学习实现这一目标是通过让一个软件叫做代理探索环境,与环境互动,向环境学习。
自动驾驶的例子
自动驾驶的一个重要方面是自动停车。目标是车辆计算机(代理)以正确的方向及位置泊车于正确的泊车位。在这个例子中,环境是代理,如车辆的动态,附近的车辆,天气状况等外界的一切。在训练期间,代理使用读数从相机,GPS,激光雷达,以及其他传感器,以产生转向,制动,和加速度命令(行动)。要了解如何从观测正确的动作(政策调整)时,代理使用试错法多次尝试停车。正确的动作会得到数值信号的奖励(增强)(图1)。
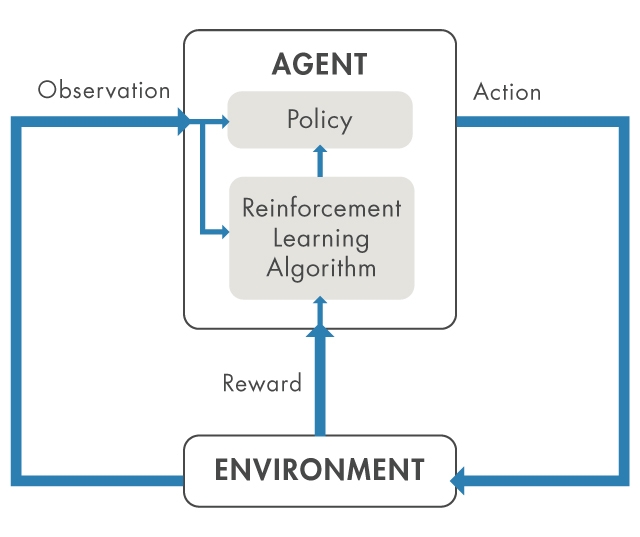
图1所示。强化学习概述图。
在这个例子中,培训是由一个受监管训练算法。训练算法负责调整基于收集到的传感器读数,行动和奖励代理商的政策。训练结束后,车辆的电脑应该能够仅使用调整政策和传感器读数停车。
算法强化学习
到目前为止,已经开发了许多增强学习训练算法。一些最流行的算法依赖于深度神经网络。神经网络最大的优点是可以对复杂的行为进行编码,使得在传统算法难以处理的应用中使用强化学习成为可能。
例如,在自动驾驶中,神经网络可以代替驾驶员,通过同时观察来自多个传感器的输入来决定如何转动方向盘,比如摄像头和激光雷达的测量数据(图2)。如果没有神经网络,问题会被分解成更小的部分:一个模块分析摄像头的输入以识别有用的特征,另一个模块过滤激光雷达的测量数据,可能是一个组件,通过融合传感器输出来描绘车辆周围环境的全貌,一个“驾驶员”模块,等等。
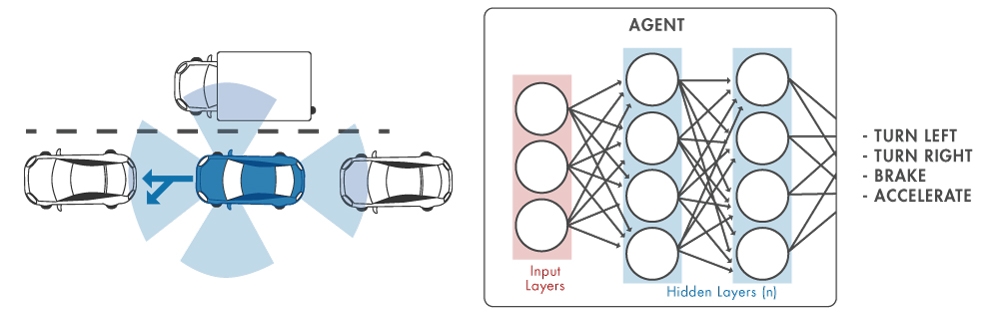
图2.神经网络的自动驾驶。
强化学习工作流程
培训采用增强学习的代理包括五个步骤:
- 创建环境。限定在其内剂可以学习,包括试剂和环境之间的界面处的环境。环境可以是模拟模型或真实的物理系统。模拟环境通常是一个良好的开端,因为它们是安全的,并允许实验。
- 定义了奖励。指定代理用于根据任务目标度量其性能的奖励信号,以及如何从环境中计算该信号。奖励塑造可能需要一些迭代才能得到正确的结果。
- 创建代理。agent由policy和training algorithm组成,需要:
- 选择一种表示策略的方法(例如,使用神经网络或查找表)。考虑如何构造构成代理决策部分的参数和逻辑。
- 选择适当的训练算法。大多数现代的强化学习算法依赖于神经网络,因为它们是大型国有/动作的空间和复杂问题的很好的候选人。
- 对代理商进行培训和验证。设置培训选项(例如停止条件)并培训代理来调整策略。验证经过训练的策略的最简单方法是通过仿真。
- 部署策略。使用生成的C/ c++或CUDA代码部署经过训练的策略表示。此时不需要担心代理和训练算法——策略是一个独立的决策系统。
迭代过程
培训采用强化学习的代理人涉及试错的相当数量。决定和结果在后期可能需要你回到更早的阶段在学习工作流程。例如,如果在训练过程中不收敛到一个合理的时间量内的最优策略,你可能有再培训代理之前更新任何以下内容:
- 培训设置
- 学习算法配置
- 政策表示
- 奖励的信号定义
- 操作和观察信号
- 环境动态
当是强化学习的正确方法?
虽然强化学习是机器学习的一大进步,但它并不总是最好的方法。如果你想尝试一下,你需要记住以下三个问题:
- 它的采样效率不高。这意味着需要大量的训练才能达到可接受的表现。即使是相对简单的应用程序,培训时间也可能从几分钟到几小时甚至几天不等。AlphaGo通过几天不间断地玩数百万个游戏,积累了数千年的人类知识。
- 建立正确的问题可能会非常棘手;许多设计决策需要做出,这可能需要重复多次才能得到正确的。这些决策包括选择适当的体系结构的神经网络,调谐超参数,塑造回报信号。
- 一个训练有素的深度神经网络策略是一个“黑匣子”,这意味着网络的内部结构是如此复杂(通常包含数百万个参数),以至于几乎不可能理解、解释和评估所做的决策。这使得使用神经网络策略建立正式的性能保证变得困难。
如果你在一个时间或安全关键项目时,你可能会想尝试一些替代方法。例如,对于控制设计,采用了传统的控制方法是一个良好的开端。
现实世界的例子:机器人会自己走路
来自南加州的瓦莱罗实验室大学的研究人员建立了教自己如何在短短几分钟内移动使用MATLAB写一个强化学习算法简单的机器人腿®(图3)。

图3。瓦莱罗实验室的新机械手。图片来源:南加州大学。
三肌腱双关节肢体是自主学习的,首先通过建模自身的动态特性,然后利用强化学习。
对于物理设计,这种机器人腿使用的腱结构,就像肌肉和肌腱的结构,权力动物的运动。强化学习,然后用动态的理解来完成在跑步机上行走的目标。
强化学习和“电机胡说”
通过电机与咿咿呀呀强化学习相结合,系统将尝试随机运动,通过这些运动的结果,其动力学特性获悉。对于这项研究,该团队开始通过随机让系统播放,或电动机牙牙学语。研究人员会给系统奖励在这种情况下,正确地执行既定任务的时间移动的跑步机,每前行。
将得到的算法,称为G2P,(一般到特定的),复制了生物神经系统通过从当腱移动肢体发生的运动(图4)学习控制肢体时所面临的普遍问题。其次是强化(奖励)是特别的任务的行为。在这种情况下,任务顺利移动跑步机。该系统通过电动机咿呀学语,然后由主人从每一次经历,或G2P学习所需的“特殊”任务创建及其动态的一个大致的了解。

图4. G2P算法。图片来源:Marjaninejad等。
神经网络,以MATLAB和深度学习工具箱内置™,使用来自电动机潺潺结果来创建输入(运动运动学)和输出(马达激活)之间的逆映射。网络更新基于在增强学习阶段,家中所期望的结果做出每次尝试的模式。它每次都记得最好的结果,如果一个新的输入创建一个更好的结果,它会以新的设置模式。
该G2P算法本身仅有5分钟的非结构化比赛后学到新的行走任务。然后,它可以适应其他任务无需额外编程。