最小二乘拟合
介绍
曲线拟合工具箱™软件使用在拟合数据时最小二乘法的方法。拟合需要一个参数模型,该参数模型与一个或多个系数相关的响应数据与预测数据相关联。拟合过程的结果是模型系数的估计。
为了获得系数估计,最小二乘法最小化残差的总和。残余物
残差的总结广场由
在哪里
线性最小二乘
加权线性最小二乘
强大的最小二乘法
非线性最小二乘
错误分布
当拟合包含随机变体的数据时,通常会有两个重要的假设通常会对错误进行:
错误仅存在于响应数据中,而不是在预测数据中存在。
错误是随机的,遵循具有零平均值和恒定方差的正常(高斯)分布,
第二个假设通常被表述为
误差被假定为正态分布,因为正态分布通常提供了对许多测量量的分布的适当的近似。尽管最小二乘拟合方法在计算参数估计时不假定正态分布误差,但该方法最适用于不包含大量具有极端值的随机误差的数据。正态分布是极端随机误差不常见的概率分布之一。然而,统计结果如置信度和预测界限确实需要正态分布误差来保证其有效性。
如果错误的平均值为零,则误差纯粹是随机的。如果平均值不是零,那么模型可能不是您的数据的正确选择,或者错误不是纯粹随机的并且包含系统错误。
数据的恒定方差意味着错误的“扩散”是恒定的。具有相同方差的数据有时被称为<一个class="indexterm" name="d123e6957">同等的质量.
假设随机误差具有恒定方差不是隐含到加权最小二乘回归的回归。相反,假设拟合过程中提供的权重正确地指示数据中存在的质量的不同水平。然后使用权重来调整每个数据点对拟合系数的估计到适当的水平的影响。
线性最小二乘
曲线拟合工具箱软件使用线性最小二乘法将线性模型适合数据。一种<年代p一个nclass="emphasis">线性模型被定义为系数线性的等式。例如,多项式是线性的,但高斯不是。为了说明线性最小二乘拟合过程,假设您有
解决该等式的未知系数
因为最小二乘拟合过程最小化残差的总和,所以通过区分确定系数
真参数的估计通常用
求和在哪里运行
解
解
正如您所看到的,估计系数
以矩阵形式,线性模型由公式给出
y=
在哪里
对于一度多项式,
这个问题的最小二乘解是一个向量
(
在哪里
b= (
使用matlab.<年代up>®反斜杠运算符(<一个href="https://de.mathworks.com/help/matlab/ref/mldivide.html">莫德利维)求解未知系数的同时线性方程系统。因为反转
你可以插上
ŷ=
H=
字母上的帽子(环形)表示来自模型的参数或预测的估计。投影矩阵
残留物是由
r=
加权最小二乘
通常假设响应数据质量相等,因此方差恒定。如果这个假设被违背了,你的匹配可能会被低质量的数据不适当地影响。为了改进拟合,可以使用加权最小二乘回归,其中在拟合过程中包含一个额外的比例因子(权重)。加权最小二乘回归使估计误差最小化
在哪里
权重修改参数估计的表达式
在哪里
通常可以通过拟合数据并绘制残差来确定方差是否为常数。在下图中,数据包含各种质量的重复数据,并且假设拟合是正确的。差质量的数据显示在残差图中,它有一个“漏斗”形状,小的预测值在响应值中产生比大的预测值更大的散度。

您提供的权重应该将响应方差转换为一个常量值。如果你知道数据中测量误差的方差,那么权重是
或者,如果你只有对每个数据点的误差变量的估计,通常用这些估计来代替真实方差就足够了。如果你不知道方差,在一个相对的尺度上指定权重就足够了。注意,即使指定了权重,总体方差项也会被估计。在本例中,权值定义了拟合中每个点的相对权值,但不用于指定每个点的确切方差。
例如,如果每个数据点是若干独立测量的均值,则使用那些数量的测量值可能是有意义的。
鲁棒最小二乘
通常假设响应误差遵循正常分布,并且极端值是罕见的。仍然是极端的值<年代p一个nclass="emphasis">离群值确实发生了。
最小二乘拟合的主要缺点是对异常值的敏感性。异常值对适合具有很大影响,因为平方余量放大了这些极端数据点的影响。为了最大限度地减少异常值的影响,您可以使用鲁棒最小二乘因素来符合您的数据。该工具箱提供了这两个强大的回归方法:
权值均方稳健拟合采用迭代重加权最小二乘算法,其过程如下:
采用加权最小二乘法拟合模型。
计算<年代p一个nclass="emphasis">调整后的残差和规范。经调整的残差为
r<年代ub>我是通常的最小二乘性残差和
K调优常数是否等于4.685,和
根据功能计算强大的权重
请注意,如果您提供自己的回归重量向量,则最终的重量是强大的重量和回归重量的乘积。
如果拟合融合,那么你就完成了。否则,通过返回第一步执行拟合过程的下一次迭代。
下面所示的曲线比较了使用Bisquare重量的稳健拟合的常规线性配合。请注意,强大的拟合遵循大部分数据,并且不会受到异常值的强烈影响。

通过使用强大的回归来最小化异常值的影响,而不是最小化异常值的影响,可以将要排除的数据点标记为拟合。参考<一个href="https://de.mathworks.com/help/curvefit/removing-outliers.html" class="a">删除异常值想要查询更多的信息。
非线性最小二乘法
曲线拟合工具箱软件使用非线性最小二乘配方将非线性模型适合数据。非线性模型被定义为在系数中是非线性的等式,或系数中的线性和非线性的组合。例如,高斯,多项式的比率和功率功能都是非线性的。
以基质形式,非线性模型由公式给出
y=
在哪里
y是一个
f是β和的函数吗
β是A.
X是个
ε是一个
非线性模型比线性模型更难以适应,因为不能使用简单的矩阵技术估计系数。相反,需要一种迭代方法,如下步骤:
您可以使用重量和适用于非线性模型的重量,并且相应地修改拟合过程。
由于近似过程的性质,所有非线性模型,数据集和起点都没有算法。因此,如果您没有使用默认起始点,算法和收敛条件达到合理的拟合,则应尝试不同的选项。参考<一个href="https://de.mathworks.com/help/curvefit/parametric-fitting.html" class="a">指定适合选项和优化的起点有关如何修改默认选项的说明。因为非线性模型对起始点特别敏感,所以这应该是您修改的第一个拟合选项。
健壮的拟合
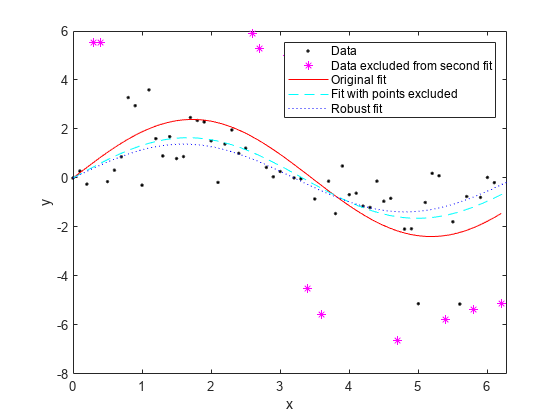
此示例显示如何比较不包括异常值和强大的拟合的影响。该示例显示了如何从模型的任意距离处排除异常值。然后,步骤比较删除异常值,指定强大的拟合,它为异常值提供了更低的重量。
创建一个基线正弦信号:
xdata =(0:0.1:2 *π)';y0 =罪(xdata);
对具有非常数方差的信号添加噪声。
响应相关的高斯噪声gnoise = y0。* randn(大小(y0));<年代p一个n年代tyle="color:#228B22">%满头花白的噪音spnoise = zeros(尺寸(y0));p = randperm(长度(y0));Sppoints = P(1:圆形(长度(p)/ 5));spnoise(sppoints)= 5 * sign(y0(sppoints));ydata = y0 + gnoise + spnoise;
使用基线正弦模型拟合嘈杂的数据,并指定3个输出参数以获得包括残差在内的拟合信息。
f = fittype (<年代p一个n年代tyle="color:#A020F0">“* sin (b * x)”);[fit1,gof,fitinfo] = fit(xdata,ydata,f,<年代p一个n年代tyle="color:#A020F0">'起点'[1]);
检查fitinfo结构中的信息。
fitinfo
fitinfo =<年代p一个nclass="emphasis">结构体字段:numobs:63 numparam:2残差:[63x1 double] jacobian:[63x2 double] extflag:3 firstorderopt:0.0883迭代:5 funccount:18 cgiteration:0算法:'信任区域 - 反光'步骤:4.1539E-04消息:'成功,但拟合停止,因为残留物的变化小于容忍度(Tolfun)。
从fitinfo结构中获得残差。
残差= fitinfo.residuals;
确定离基线模型任意距离大于1.5个标准差的点为“离群点”,并排除离群点对数据进行重新拟合。
I = abs(residuals) > 1.5 * std(residuals);离群值= excludedata (xdata ydata,<年代p一个n年代tyle="color:#A020F0">“指标”,一世);fit2 = fit(xdata,ydata,f,<年代p一个n年代tyle="color:#A020F0">'起点'[1],<年代p一个n年代tyle="color:#0000FF">......“排除”、异常值);
比较排除异常值的效果和在稳健拟合中给予它们较低的平方权重的效果。
fit3 = fit(xdata,ydata,f,<年代p一个n年代tyle="color:#A020F0">'起点'[1],<年代p一个n年代tyle="color:#A020F0">'强壮的',<年代p一个n年代tyle="color:#A020F0">“上”);
绘制数据、异常值和拟合结果。指定一个有用的图例。
情节(fit1<年代p一个n年代tyle="color:#A020F0">的r -,xdata,ydata,<年代p一个n年代tyle="color:#A020F0">'k。',异常值,<年代p一个n年代tyle="color:#A020F0">“m *”) 抓住<年代p一个n年代tyle="color:#A020F0">在情节(fit2<年代p一个n年代tyle="color:#A020F0">'C - ')图(Fit3,<年代p一个n年代tyle="color:#A020F0">'B:') xlim([0 2*pi])<年代p一个n年代tyle="color:#A020F0">“数据”,<年代p一个n年代tyle="color:#A020F0">'数据排除在第二次合适之外',<年代p一个n年代tyle="color:#A020F0">'原创',<年代p一个n年代tyle="color:#0000FF">......'适合点被排除在外,<年代p一个n年代tyle="color:#A020F0">健壮的适合的) 抓住<年代p一个n年代tyle="color:#A020F0">离开
绘制考虑离群值的两个拟合的残差:
图绘图(fit2,xdata,ydata,<年代p一个n年代tyle="color:#A020F0">“有限公司”,<年代p一个n年代tyle="color:#A020F0">“残差”) 抓住<年代p一个n年代tyle="color:#A020F0">在绘图(Fit3,Xdata,Ydata,<年代p一个n年代tyle="color:#A020F0">“软”,<年代p一个n年代tyle="color:#A020F0">“残差”) 抓住<年代p一个n年代tyle="color:#A020F0">离开

选择一个网站
选择一个网站,以便在可用的地方进行翻译的内容,并查看本地活动和优惠。根据您的位置,我们建议您选择:<年代trong class="recommended-country">.
选择<年代p一个nclass="recommended-country">网站您还可以从以下列表中选择一个网站:
