在这个视频中,我们将拟合模型对茶碱在之前的视频数据集,我们进口进口数据和执行non-compartmental分析。数据集包含12个主题,每个主题都有一个单一的口服剂量浓度测量和它也有一个co-variate列。
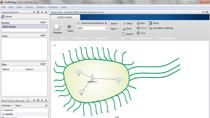
我们想知道的第一件事是什么样的我们应该拟合模型。在这里你可以看到数据绘制在半对数的y轴。你可以看到,有一个吸收阶段,紧随其后的是一个线性消除阶段,线性对数尺度。这意味着一个舱模型可能符合这一数据。
我们可以编辑一室模型通过PK的模型构建器和添加一个模型库。我们想要添加的模型是一个舱模型与一阶剂量和线性。你可以看到这是一个简单的模型,吸收剂量的中央室,随后消除。
我们现在可以估计的参数模型。这就是吸收速率和消除速率,以及中央室的体积。这是三个参数,我们将从数据估算。
在我们开始之前估计这三个参数,它可以有助于了解初步估计可能是这三个参数。为了做到这一点,我们可以模拟模型,看看我们是否可以把仿真结果与观测结果一致。目前,这些参数都是一个,除了吸收速率。我们需要吸收速率,或者至少不是零,这样,如果我们应用剂量,剂量的中央,利率从剂量药物中心中央不为零。因为如果它是零,永远不会出现在中央室剂量。
为了模拟模型,我们需要回到模型分析仪和创建一个项目。和程序被称为模拟模型。然后,我们选择我们的模型,一室模型。我们可以从数据集中选择一个剂量。所以我们可以使用列的数据集,在这种情况下,theophyline.dose_total。
这个剂量需要去剂量集中在我们的模型中,和时间单位是小时。最后一个时间点的观测数据集在25小时。所以我们要模拟该模型还25小时。
所以现在我们只模拟模型,我们可以添加茶碱的数据集的数据比较模拟的观测。如果我们在这里重新配置。这些观察结果,在蓝色的底部,你可以看到模拟。
现在我们可以将滑块添加到仿真,将仿真与观测结果一致。所以我们可以添加一个滑块的中央室,吸收速率和间隙。现在我们可以使用我们的non-compartmental分析的结果,在数据表两个。
初步估计,例如,对于中央室,我们可以使用这些值。在这种情况下,在0.5的顺序。的间隙,我们可以看一看这个专栏,在non-compartmental间隙的计算分析。这是0.04的。我要离开这里的KA,因为我们没有non-compartmental分析参数来指导我们在吸收速率。
但是你可以看到,即使这些值,仿真看起来非常类似于观察。我们可以使用这些值作为初始估计的参数估计。所以,我们估计参数。
再一次,我们可以创建一个新的项目,这个项目被称为健康数据。我们可以穿过这个程序的设置,一段一段的。你需要做的第一件事是您想要使用的数据集的定义。在这种情况下,只有茶碱的数据集。
然后您需要定义模型在你的项目你想使用。这里我们使用我们之前编辑的一室模型。
现在,为了执行这个估计,SimBiology将使用一个目标函数。目标函数是衡量你的仿真和实验数据之间的差异。最简单的例子将平方误差的总和之间的仿真和实验数据。
估计的想法是最小化目标函数的值。一旦我们有最小值,代表了最适合。为了创建目标函数,SimBiology需要一些信息。你需要将实验数据映射到组件在你的模型中,这是下一步我们需要做什么。
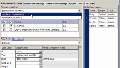
你可以看到这里的列标题,ID,浓度和剂量。他们配合的列标题,ID、时间、浓度、和剂量。这些列标题需要匹配我们的模型,特别是最后两个,所以总浓度和剂量。
你可以看到这里的浓度是映射到组件的核心药物中心。和剂量列映射到总剂量中央。这列数据和组件之间的映射模型中允许SimBiology为您创建目标函数。
剂量,在这里你可以看到,我们有一个丸剂量。这是一个即时管理的药物剂量的中央。我们称之为丸,就说我们管理口服剂量。
如果你愿意,你也可以定义一个速度。这可以列在你的数据集或您可以设置一定数量。率将定义,例如,输液速度。
你也可以有多个响应模型。如果你有多个物种的浓度在你的模型中,您可以添加进一步反应纳入目标函数。
接下来我们需要做的就是我们需要定义我们要估计的参数。这符合程序自动设置的一室模型,因为它知道这三个参数需要估计中央室体积,外观和吸收。当然,你也可以选择自己的参数,你可以拖拽,把他从模型浏览器左边到估计参数表中。
如果你扩大这些,你可以设置初始估计。如果你记得,最初的转换价值将0.4体积,间隙,这将是0.04,吸收速度,这将是一个。我们要离开。好的。
现在我们将选择做一个汇集,从而导致一组估计12个科目。如果我们取消选择这个盒子,我们会得到一组估计为每个主题在我们的数据集。
我们也可以选择一个误差模型。在本例中,我们将尝试多个错误摩尔,我们将开始与常数误差模型。你也可以选择什么样的解决你想使用,您是否想要使用一个全局银或本地解算器,还有,在当地解决,有梯度和基于non-gradient的解决者。
在这里,我建议这是一个小模型,用基于梯度的局部解算器,像LSQ没有名字。
好了,接下来我们需要做的是,我们需要按运行开始估计参数。评估进展,你可以看到日志可能值,和你想要最大化。
请注意,日志可能是目标函数的负对数。所以最小化目标函数最大化日志是一样的可能性。你也可以看到一阶最优性,你想要最小化。v然后你看到的每个参数的进展,因为它被灭亡。
如果你现在回到SimBiology分析器模型,您将看到一系列的阴谋。第一个情节显示校准模型和实验数据之间的配合,在校准模型给了每一个主题对应剂量的剂量中指定列的数据集。您还将看到浓度的预测值与观测值,你想要的数据点所在紧密团结。
同样的你可以做残差与时间。在这里,你要确保残差是均匀分布的。
最后,我们可以看一下qqplot残差。这条线,在这里,代表一个正态分布。如果点这里谎言接近这条线,这意味着残差正态分布,这是一个潜在的假设对于这种优化。
现在,我们已经完成这个评估,有些事情,我们可以改变。的一件事,我们可能想要改变是错误的模型。在我们这么做之前,我想保存这个项目的结果。所以我可以叫这个常数和汇集。我现在要改变这个比例误差模型和运行优化。如果我们现在看看阴谋,你会发现有一个额外的情节产生的相对误差模型。但也有定量措施,你可以使用它来比较这两个适合。所以我们可以节省prop_pooled这个估计的结果。
现在,我们能做的,是我们可以抓住一个数据表。所以我们创建一个新的数据表。我们将这些估计的结果拖到数据表。现在我们可以比较两个在一起。我们可以比较的估计,但我们还可以比较日志可能性。再一次,我们想最大化的可能性,我们可以比较控制措施Akaike信息标准和贝叶斯信息准则。
特别是AIC和BIC是好看到哪一个给你最适合的方法。较低的AIC代表一个更好的选择。所以在这种情况下,常数误差模型可能是最适合这个数据集。
在我们完成参数估计的固定效果。在我们的下一节中,我们还将考虑执行混合效果评估在相同的数据集。