训练DQN Agent进行波束选择
本示例展示了如何训练深度q网络(DQN)强化学习代理来完成5G新无线电(NR)通信系统中的波束选择任务。经过训练的智能体不再对所有波束对进行详尽的波束搜索,而是通过选择信号强度最高的波束来提高波束选择精度,同时降低波束转换成本。本例的仿真结果表明,在降低波束转换成本的同时,被训练的智能体选择了大于90%最大可能信号强度的波束。
简介
为了实现毫米波(mmWave)通信,必须使用波束管理技术,因为在高频时会出现高路径损耗和阻塞。波束管理是一套第1层(物理层)和第2层(介质访问控制)程序,用以建立和保持最佳的波束对(发射波束和相应的接收波束),以实现良好的连通性[1].有关NR波束管理程序的示例,请参见NR SSB光束扫描而且基于CSI-RS的NR下行传输端波束细化.
本例考虑在用户设备(UE)和gNB之间建立连接时的波束选择过程。在5G NR中,初始接入的波束选择过程包括波束扫描,这需要对发射机和接收机侧的所有波束进行彻底搜索,然后选择提供最强参考信号接收功率(RSRP)的波束对。由于毫米波通信需要许多天线元件,意味着许多波束,对所有波束进行详尽的搜索将变得计算昂贵,并增加初始访问时间。
为了避免重复执行穷尽搜索并减少通信开销,本例使用强化学习(RL)代理在UE绕轨道移动时,使用接收机的GPS坐标和当前波束角度执行波束选择。
在该图中,正方形表示UE(绿色圆圈)所绕的轨道,红色三角形表示基站(gNB)的位置,黄色正方形表示信道散射器,蓝色直线表示所选波束。

有关DQN强化学习代理的更多信息,请参见Deep Q-Network (DQN)代理商(强化学习工具箱).
定义环境
为了训练一个强化学习代理,你必须定义它将与之交互的环境。强化学习代理根据观察结果选择行动。强化学习算法的目标是找到最优的行动,使任务期间从环境中获得的预期累积长期奖励最大化。有关强化学习代理的更多信息,请参见强化学习代理(强化学习工具箱).
对于波束选择环境:
观测结果由UE位置信息和当前波束选择表示。
动作是从gNB的四个总光束角度中选择一个光束。
奖励 时间步长 由:
是对UE (rsrp)测量的信号强度的奖励 是对控制努力的惩罚。 是以度为单位的光束角度。
方法生成的RSRP数据创建环境波束选择的神经网络的例子。在预先录制的数据中,接收器随机分布在一个6米正方形的周长上,并配置有16个波束对(两端各有4个波束,模拟波束由一个射频链组成)。使用MIMO散射信道,示例考虑训练集中的200个接收器位置(nnBS_TrainingData.mat)和测试集中的100个接收器位置(nnBS_TestData.mat).预先录制的数据使用二维位置坐标。
的nnBS_TrainingData.mat文件中包含接收者位置的矩阵,locationMatTrain,以及16对光束的RSRP测量,rsrpMatTrain.由于接收机波束选择不会显著影响信号强度,因此可以计算每个UE位置的每个基站天线波束的平均RSRP。因此,作用空间是四个光束角。所记录的数据被重新排序以模拟接收机沿顺时针方向围绕基站移动。
生成新的训练集和测试集,设置useSavedData来假.请注意,重新生成数据可能需要几个小时。
为重现性设置随机生成器种子rng(0) useSavedData = true;如果useSavedData%负载数据生成的神经网络为梁选择的例子负载nnBS_TrainingData负载nnBS_TestData负载nnBS_position其他的生成数据helperNNBSGenerateData ();% #好吧的位置。posTX = prm.posTx;的位置。ScatPos = prm.ScatPos;结束locationMat = locationMatTrain(1:4:end,:);按顺时针顺序排序位置secLen = size(locationMat,1)/4;[~,b1] = sort(locationMat(1:secLen,2));[~,b2] = sort(locationMat(secLen+1:2*secLen,1));[~,b3] = sort(locationMat(2*secLen+1:3*secLen,2),“下”);[~,b4] = sort(locationMat(3*secLen+1:4*secLen,1),“下”);idx = [b1;secLen+b2;2*secLen+b3;3*secLen+b4];locationMat = locationMat(idx,:);计算每个gNB波束的平均RSRP,并按顺时针顺序排序avgRsrpMatTrain = rsrpMatTrain/4;% prm.NRepeatSameLoc = 4;avgRsrpMatTrain = 100*avgRsrpMatTrain。/ max (avgRsrpMatTrain, [],“所有”);avgRsrpMatTrain = avgRsrpMatTrain(:,:,idx);avgRsrpMatTrain = mean(avgRsrpMatTrain,1);%角度旋转矩阵:更新为nBeams>4txBeamAng = [-78,7,92,177];rotAngleMat = [0 85 170 105 85 0 85 170 170 85 0 85 105 170 85 0];rotAngleMat = 100*rotAngleMat./max(rotAngleMat,[],“所有”);使用生成的数据创建培训环境envTrain = BeamSelectEnv(locationMat,avgRsrpMatTrain,rotAngleMat,position);
环境定义在BeamSelectEnv金宝app类创建的rlCreateEnvTemplate类。BeamSelectEnv.m位于此示例文件夹中。奖励和惩罚函数在代理与环境交互时定义并更新。
创建代理
DQN代理通过使用一个函数来近似给定观察和操作的长期奖励rlVectorQValueFunction(强化学习工具箱)评论家。矢量q值函数近似器将观测值作为输入,状态-动作值作为输出。每个输出元素表示从观察输入所指示的状态中采取相应离散行动所期望的累计长期奖励。
该示例对给定的观察和操作规范使用默认的评论家网络结构。
obsInfo = getObservationInfo(envTrain);actInfo = getActionInfo(envTrain);agent = rlDQNAgent(obsInfo,actInfo);
查看评论家神经网络。
criticNetwork = getModel(get批评家(代理));analyzeNetwork (criticNetwork)
为了促进探索,本例中的DQN代理优化学习速率为1e-3, epsilon衰减因子为1e-4。有关DQN超参数及其描述的完整列表,请参见rlDQNAgentOptions(强化学习工具箱).
指定用于训练的代理超参数。
agent.AgentOptions.CriticOptimizerOptions.LearnRate = 1e-3;agent.AgentOptions.EpsilonGreedyExploration.EpsilonDecay = 1e-4;
火车代理
要训练代理,首先指定使用的训练选项rlTrainingOptions(强化学习工具箱).对于本例,每个训练会话最多运行500集,每集最多持续200个时间步,对应于赛道的一个完整循环。
trainOpts = rlTrainingOptions(...MaxEpisodes = 500,...MaxStepsPerEpisode = 200,...%训练数据大小= 200StopTrainingCriteria =“AverageSteps”,...StopTrainingValue = 500,...情节=“训练进步”);
培训代理使用火车(强化学习工具箱)函数。训练这个代理是一个计算密集型的过程,需要几分钟才能完成。为了在运行此示例时节省时间,请通过设置加载预训练的代理doTraining来假.要亲自训练特工,请设置doTraining来真正的.
doTraining = false;如果doTraining trainingStats = train(agent,envTrain,trainOpts);% #好吧其他的负载(“nnBS_RLAgent.mat”)结束
这张图显示了训练的进程。由于训练过程固有的随机性,您可以预期不同的结果。

模拟训练代理
要验证训练过的代理,请使用代理在训练过程中没有看到的UE位置在测试环境中运行模拟。
locationMat = locationMatTest(1:4:end,:);按顺时针顺序排序位置secLen = size(locationMat,1)/4;[~,b1] = sort(locationMat(1:secLen,2));[~,b2] = sort(locationMat(secLen+1:2*secLen,1));[~,b3] = sort(locationMat(2*secLen+1:3*secLen,2),“下”);[~,b4] = sort(locationMat(3*secLen+1:4*secLen,1),“下”);idx = [b1;secLen+b2;2*secLen+b3;3*secLen+b4];locationMat = locationMat(idx,:);计算平均RSRPavgRsrpMatTest = rsrpMatTest/4;% 4 = prm.NRepeatSameLoc;avgRsrpMatTest = 100*avgRsrpMatTest。/ max (avgRsrpMatTest, [],“所有”);avgRsrpMatTest = avgRsrpMatTest(::,idx);avgRsrpMatTest = mean(avgRsrpMatTest,1);%创建测试环境envTest = BeamSelectEnv(locationMat,avgRsrpMatTest,rotAngleMat,position);
用训练过的智能体模拟环境。有关代理模拟的详细信息,请参见rlSimulationOptions而且sim卡.
情节(envTest) sim (envTest、代理、rlSimulationOptions (“MaxSteps”, 100))
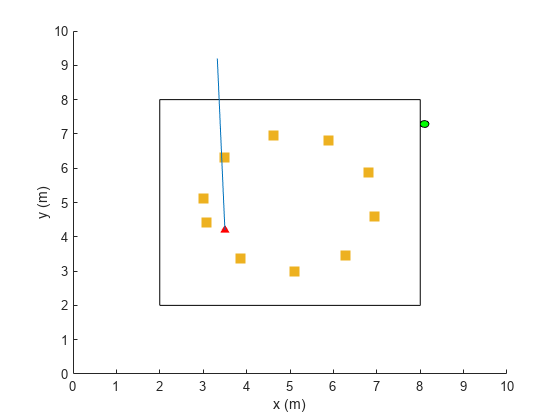
maxPosibleRsrp = sum(max(挤压(avgRsrpMatTest)));rsrpSim = envTest.EpisodeRsrp;disp ("代理RSRP/最大RSRP = "+ rsrpSim/maxPosibleRsrp*100 +“%”)
Agent RSRP/Maximum RSRP = 94.9399%
参考文献
[1] 3gpp tr 38.802。无线接入新技术物理层方面研究第三代伙伴计划;技术规范集团无线接入网.
[2]萨顿,理查德S和安德鲁g巴托。强化学习:简介。第二版。马萨诸塞州剑桥:麻省理工学院出版社,2020年。
相关的话题
- 波束选择的神经网络
- 什么是强化学习?(强化学习工具箱)
- 训练强化学习代理(强化学习工具箱)
- MATLAB深度学习(深度学习工具箱)
您也可以从以下列表中选择一个网站: