使用内存不足特性训练语音数字识别网络
本例使用转换后的数据存储在内存不足的听觉频谱图上训练语音数字识别网络。在本例中,您使用以下方法从音频中提取听觉谱图audioDatastore(音频工具箱)而且audioFeatureExtractor(音频工具箱),然后把它们写到磁盘上。然后使用signalDatastore(信号处理工具箱)在训练期间访问特征。当训练特征不适合内存时,工作流是有用的。在这个工作流中,您只提取一次特征,如果您正在迭代深度学习模型设计,这将加快您的工作流。
数据
下载免费语音数字数据集(FSDD)。FSDD由4位说话者用英语说数字0到9的2000份录音组成。
downloadFolder = matlab.internal.examples.download金宝appSupportFile(“音频”,“FSDD.zip”);dataFolder = tempdir;unzip(下载文件夹,数据文件夹)dataset = fullfile(数据文件夹,数据文件夹)“FSDD”);
创建一个audioDatastore这就指向了数据集。
ads = audioDatastore(dataset, inclesubfolders =true);
显示类和每个类中的示例数量。
[~,filename] = fileparts(ads.Files);ads.Labels = categorical(extractBefore(文件名,“_”));总结(ads.Labels)
0 200 1 200 2 200 3 200 4 200 5 200 6 200 7 200 8 200 9 200
将FSDD分为训练集和测试集。将80%的数据分配给训练集,并保留20%的数据给测试集。您使用训练集来训练模型,使用测试集来验证训练后的模型。
rng默认的广告= shuffle(广告);[adsTrain,adsTest] = splitEachLabel(ads,0.8);countEachLabel (adsTrain)
ans =10×2表标签计数_____ _____ 0 160 1 160 2 160 3 160 4 160 5 160 6 160 7 160 8 160 9 160
countEachLabel (adsTest)
ans =10×2表标签计数_____ _____ 0 40 1 40 2 40 3 40 4 40 5 40 6 40 7 40 8 40 9 40
减少训练数据集
为了用整个数据集训练网络并达到尽可能高的精度,设置speedupExample来假.要快速运行此示例,请设置speedupExample来真正的.
speedupExample =假;如果(adsTrain = splitEachLabel(adsTrain,2);adsTest = splitEachLabel(adsTest,2);结束

设置听觉谱图提取
CNN接受mel频率谱图。
定义用于提取梅尔频率谱图的参数。使用220毫秒的窗口和10毫秒的窗口之间的跳跃。使用2048点DFT和40个频段。
Fs = 8000;frameDuration = 0.22;frameLength = round(frameDuration*fs);hopDuration = 0.01;hopLength = round(hopDuration*fs);segmentLength = 8192;numBands = 40;fftLength = 2048;
创建一个audioFeatureExtractor(音频工具箱)对象从输入音频信号中计算梅尔频率谱图。
afe = audioFeatureExtractor(melSpectrum=true,SampleRate=fs,...窗口=汉明(frameLength,“周期”,OverlapLength=frameLength - hopLength,...FFTLength = FFTLength);
设置mel-frequency谱图参数。
setExtractorParameters (afe“melSpectrum”NumBands = NumBands FrequencyRange = [50 fs / 2], WindowNormalization = true);
创建一个转换后的数据存储,从音频数据中计算梅尔频率谱图。支撑函数金宝app,getSpeechSpectrogram,使录音长度标准化,并使音频输入的振幅标准化。getSpeechSpectrogram使用audioFeatureExtractor对象afe获得基于对数的mel频率谱图。
adsSpecTrain = transform(adsTrain,@(x)getSpeechSpectrogram(x,afe,segmentLength));
将听觉频谱图写入磁盘
使用writeall(音频工具箱)将听觉频谱图写入磁盘。集UseParallel为true时执行并行写入。
outputLocation = fullfile(tempdir,“FSDD_Features”);writeall (adsSpecTrain、outputLocation WriteFcn = @myCustomWriter UseParallel = true);
建立训练信号数据存储
创建一个signalDatastore这就指向了内存不足的特性。read函数返回一个频谱图/标签对。
sds = signalDatastore(outputLocation, inclesubfolders =true,...SignalVariableNames = [“规范”,“标签”), ReadOutputOrientation =“行”);
验证数据
验证数据集适合内存。预计算验证特性。
adsTestT = transform(adsTest,@(x){getSpeechSpectrogram(x,afe,segmentLength)});XTest = readall(adsTestT);XTest = cat(4,XTest{:});
获取验证标签。
YTest = adsTest.Labels;
定义CNN架构
构造一个小的CNN作为一个层数组。使用卷积和批处理归一化层,并使用最大池化层对特征映射进行下采样。为了降低网络记忆训练数据特定特征的可能性,在最后一个全连接层的输入中加入少量的dropout。
sz = size(XTest);specSize = sz(1:2);imageSize = [specSize 1];numClasses = numel(类别(YTest));dropoutProb = 0.2;numF = 12;图层= [imageInputLayer(imageSize,归一化=“没有”) convolution2dLayer (5 numF填充=“相同”) batchNormalizationLayer reluLayer maxPooling2dLayer(3,Stride=2,Padding=“相同”) convolution2dLayer (3 2 * numF填充=“相同”) batchNormalizationLayer reluLayer maxPooling2dLayer(3,Stride=2,Padding=“相同”) convolution2dLayer(3、4 * numF填充=“相同”) batchNormalizationLayer reluLayer maxPooling2dLayer(3,Stride=2,Padding=“相同”) convolution2dLayer(3、4 * numF填充=“相同”) batchNormalizationLayer reluLayer convolution2dLayer(3,4*numF,Padding=“相同”) batchNormalizationLayer reluLayer maxPooling2dLayer(2) dropoutLayer(dropoutProb) fullyConnectedLayer(numClasses) softmaxLayer classificationLayer(Classes=categories(YTest));];
设置用于训练网络的超参数。使用50个小批大小和1e-4的学习率。指定的亚当的优化。若要使用并行池读取转换后的数据存储,请设置DispatchInBackground来真正的.有关更多信息,请参见trainingOptions.
miniBatchSize = 50;选项= trainingOptions(“亚当”,...InitialLearnRate = 1的军医,...MaxEpochs = 30,...LearnRateSchedule =“分段”,...LearnRateDropFactor = 0.1,...LearnRateDropPeriod = 15,...MiniBatchSize = MiniBatchSize,...洗牌=“every-epoch”,...情节=“训练进步”,...Verbose = false,...ValidationData = {XTest,欧美},...ValidationFrequency =装天花板(元素个数(adsTrain.Files) / miniBatchSize),...ExecutionEnvironment =“汽车”,...DispatchInBackground = true);
通过将训练数据存储传递给来训练网络trainNetwork.
trainedNet = trainNetwork(sds,layers,options);

使用训练好的网络预测测试集的数字标签。
[ypredict,probs] = category (trainedNet,XTest);cnnAccuracy = sum(yexpected ==YTest)/ nummel (YTest)*100
cnnAccuracy = 96
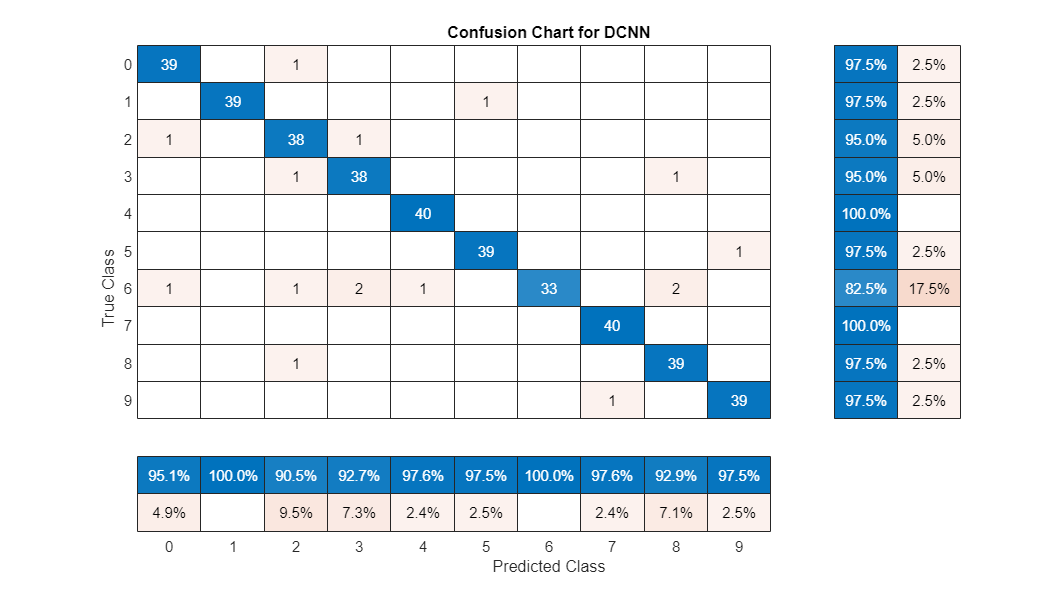
用混淆图总结训练网络在测试集上的性能。通过使用列和行摘要显示每个类的精度和召回率。混淆图底部的表格显示了精度值。混淆图右侧的表格显示召回值。
图(单位=“归一化”,Position=[0.2 0.2 1.5 1.5]);Ypredicted confusionchart(欧美,...Title =“DCNN困惑表”,...ColumnSummary =“column-normalized”RowSummary =“row-normalized”);
金宝app支持功能
获取语音谱图
函数X = getSpeechSpectrogram(X,afe,segmentLength)getSpeechSpectrogram(x,afe,params)计算一个语音谱图%信号x使用audioFeatureExtractor安全。x = scaleandsize (single(x),segmentLength);Spec = extract(afe,x).';X = log10(spec + 1e-6);结束
缩放和调整
函数x = scaleandsize (x,分段长度)% scaleAndResize(x,segmentLength)根据x的最大绝对值和力来缩放%它的长度为segmentLength通过修剪或零填充。L = segmentLength;N = size(x,1);如果N > L x = x(1:L,:);elseifN < L pad = L - N;Prepad =地板(pad/2);Postpad = cell (pad/2);X = [0 (postpad,1); X; 0 (postpad,1)];结束X = X /max(abs(X));结束
自定义写函数
函数myCustomWriter(规范、writeInfo ~)% myCustomWriter(spec,writeInfo,~)写入听觉频谱图/标签%对到MAT文件。文件名= strrep(写入信息。SuggestedOutputName,“wav”,“.mat”);label = writeInfo.ReadInfo.Label;保存(文件名,“标签”,“规范”);结束
您也可以从以下列表中选择一个网站: