美国经济模式
这个例子说明了向量的使用纠错(VEC)模型的线性替代Smets-Wouters动态随机一般均衡(DSGE)宏观经济模型,和许多Smets-Wouters技术适用于美国经济的描述。
此外,更多的例子突出了很多特色多个在计量经济学时间序列分析发现工具箱™,包括评估、蒙特卡罗模拟,过滤、预测和脉冲响应功能。这个例子也说明了如何确定协整排使用Johansen协整测试的套件,以及在估计参数约束的实施。
Smets-Wouters模型([11],[12],[13])是一种非线性方程组的形式DSGE模型。DSGE模型试图解释总体经济行为,如经济增长,商业周期,和货币和财政政策的影响,利用宏观经济模型来源于微观经济原则。
“动态随机一般均衡”模型是动态的;他们研究经济体如何随时间变化。“动态随机一般均衡”模型也随机;他们占随机冲击的影响包括技术变化和价格波动。
因为DSGE模型从微观经济原则约束的决策,而不是依赖历史相关性,他们更难以解决和分析。然而,因为他们也是基于经济主体的偏好,DSGE模型提供了一个自然基准评估政策变化的影响。
相比之下,传统的宏观计量经济学预测模型估计变量之间的关系在不同经济部门的使用历史数据,通常更容易实现,分析和解释。
这个例子实现了一个传统的线性预测模型。的目的不是复制原始的结果Smets-Wouters DSGE模型,也没有解释其结果。相反,这个例子说明了如何使用计量经济学的工具箱支持工作流的功能类似于手中,伍特斯金宝app[13]使用相同的宏观经济时间序列数据。
这个例子使用一个共合体向量自回归(VAR)模型,也称为向量纠错(VEC)模型,两者都是由各种功能在计量经济学工具。金宝app这种描述性的宏观经济模型提供了一个很好的起点,检查各种冲击美国经济的影响,尤其是在2008年的财政危机。这个示例使用Johansen协整测试和演示了估计,模拟、过滤和VAR和VEC多元时间序列模型预测的特性在计量经济学工具。风格的手中,武泰,这个例子反应模型相同的7系列:输出(GDP)、价格(GDP平减指数),工资,工作时间,利率(联邦基金),消费和投资。
同时,强调季度经济时间序列数据的操作和管理,这个示例使用时间表和datetime数据类型。
获得经济数据
该文件Data_USEconVECModel.mat包含适当的经济系列存储在两个时间表:弗雷德和国会预算办公室。弗雷德包含的示例模型是合适的,从美国联邦储备理事会(美联储,fed)经济数据库(FRED)[14]1957期:Q1(31 - 3月- 1957)到2016年:第四季度(2016年- 12月31日)。国会预算办公室来自国会预算办公室(CBO)[1]为的一个子集,包含10年经济预测弗雷德系列。国会预算办公室在预测地平线;这个示例使用观察其中条件预测和仿真超出了弗雷德的最新数据。
响应系列使用:
弗雷德系列描述- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -国内生产总值占国内生产总值(GDP)(季度)数十亿美元,占国内生产总值(GDP) GDPDEF内含平减物价指数(季度)指数2009 = 100,COE支付薪酬的员工(数十亿美元,季度)HOANBS非农商业部门小时的所有人(指数2009 = 100,季度)FEDFUNDS有效联邦基金利率(年化,百分比,每月)PCEC个人消费支出(季度)数十亿美元,GPDI国内私人投资总额(数十亿美元,季度)
负载Data_USEconVECModel
如果你有一个数据处理工具箱™许可证,然后你可以加载,同步,和合并最新的经济数据直接从弗雷德为了更好的理解更全面的工作流程。直接从弗雷德下载最新数据,数据处理工具箱的用户可以运行以下命令:
弗雷德= Example_USEconData;
弗雷德返回所有数据在每个周期的开始。除了联邦基金,弗雷德返回季度,经季节性因素调整后的系列在每个季度的开始。联邦基金月度报告在每月的开始。因为GDP内含平减物价指数模型中,这个示例使用名义系列。
手中的一致性和武泰,弗雷德这个例子中同步数据到一个季度周期性使用end-of-quarter报告大会。
例如,弗雷德报告2012:第一季度国内生产总值(GDP)日期为01 - 1月- 2012年和2012年:M3联邦基金01 - 3月- 2012。当同步常见end-of-quarter周期性,系列2012年- 3月31日,2012年第一季度的最后一天。对于任何给定的年YYYY,一季度的数据,第二季度,第三季度,第四季度对应31-Mar-YYYY, 30-Jun-YYYY, 30-Sep-YYYY和31-Dec-YYYY分别。
变换原始数据
弗雷德的原始数据,转换系列手中和伍特斯[13]利率(FEDFUNDS)是不变,其余系列展览指数增长表示为相应的报告值的对数100倍。为简单起见,保留原始的同一系列的名字和转换数据。
数据=弗雷德;%分配日期和原始数据数据。国内生产总值= 100 *日志(FRED.GDP);% %(输出)数据。GDPDEF = 100 *日志(FRED.GDPDEF);% GDP内含平减物价指数数据。COE = 100 *日志(FRED.COE);%员工薪酬(工资)数据。HOANBS = 100 *日志(FRED.HOANBS);%的时间所有人(小时)数据。PCEC = 100*log(FRED.PCEC);%个人消费支出(消费)数据。GPDI = 100 *日志(FRED.GPDI);%私人国内总投资(投资)
显示模型数据
检查模型中的数据,绘制每个系列和覆盖阴影乐队确定经济衰退时期由美国国家经济研究局(NBER)[9]。的recessionplot功能块的衰退,这个例子包括经济衰退在图形化的结果。recessionplot任意设置月中经济衰退的开始或结束日期。
图次要情节(2 2 1)情节(数据。时间,(数据。国内生产总值,Data.GDPDEF]) recessionplot标题(“& GDP平减物价指数”)ylabel (“对数(x100)”)h =传奇(“国内生产总值”,“GDPDEF”,“位置”,“最佳”);h。盒=“关闭”;次要情节(2,2,2);(数据。时间,(数据。PCEC Data.GPDI]) recessionplot title(消费与投资的)ylabel (“对数(x100)”)h =传奇(“PCEC”,“GPDI”,“位置”,“最佳”);h。盒=“关闭”;次要情节(2,2,3)情节(数据。时间,(数据。COE Data.HOANBS]) recessionplot标题(的工资和小时的)ylabel (“对数(x100)”)h =传奇(“卓越中心”,“HOANBS”,“位置”,“最佳”);h。盒=“关闭”;次要情节(2,2,4)情节(数据。时间,Data.FEDFUNDS) recessionplot标题(“联邦基金”)ylabel (“百分比”)

大纲的估计方法
VEC模型可以包含一个适当的规范,个人经验和熟悉数据,特别分析、行业最佳实践,法规要求,统计严谨。此外,模型规范可以应用于分类指标如AIC / BIC信息标准和样本外预测性能。尽管许多研究人员通常包括所有这些要素指标以迭代方式,这样做这是超出了一个例子的范围。
考虑到手中,伍特斯[13]强调样本外预测性能,本例中没有评估样本内拟合优度的措施。然而,计量经济学的工具箱支持这类评估(例如,看到的金宝appaicbic)。
了解规范方法在本例中,它是有用的观察VEC模型,评估工作分为两个步骤:
估计协整关系。这通常被称为约翰森一步。对非平稳时间序列
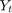 ,协整排(
,协整排(r)是独立的线性组合的数量是静止的,可以大致解释为长期均衡关系的数量。换句话说,尽管组件系列可以单独非平稳,各种固定它们的线性组合。固定数量的独立线性组合是协整的排名,和相应的固定线性组合的协整关系。估计一个VAR模型在不同使用协整关系预测的第一步。因为包含预测回归组件添加一个VAR模型,这通常被称为VARX一步。
工作流用于指定一个适当的矢量,或共合体VAR模型是:
确定滞后长度(
P)的模型。无论你喜欢VEC (p - 1)形式的差异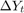 或VAR (P)形式的水平,
或VAR (P)形式的水平,P代表的数量presample反应需要初始化模型。确定协整等级(
r)。确定最好的协整模型捕获数据的确定的条款。
总的来说,这个序列决定了协整关系和对应的第一步两步估计的方法。
额外的结构强加于VARX模型的参数:
估计一个无限制VARX模型作为基准模型。
确定和实施适当的限制VARX模型的参数,包括常数,回归系数和自回归系数。
VEC模型估计
首先指定滞后长度(PVEC (p - 1))的模型。这个例子需要一种简单的方法和采用Johansen的指导[4],4页,Juselius[5],p . 72。假设P= 2落后足以描述各系列之间的动态交互。
低延迟订单的好处是模型简单。特别是,每个额外的延迟估计的无约束VEC模型需要额外7 * 7 = 49参数,所以低滞后over-parameterization减轻了顺序的影响。
估计的协整关系
一个特别重要的一步是确定协整排的同时系列,同时需要一个模型的协整。因为数据明显表现出时间趋势,检查的可能性描述的数据可以通过两种约翰森参数形式,结合线性时间趋势。
更普遍的两种形式是约翰森H *模型中,一个组件的整体持续出现内部(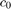 )和外部(
)和外部(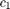 协整关系,而时间趋势(
协整关系,而时间趋势(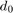 )仅限于协整关系:
)仅限于协整关系:
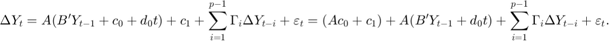
因为不断出现的一个组成部分内部和外部的协整关系,整个常数(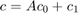 )是不受限制的和H *模型就变成:
)是不受限制的和H *模型就变成:
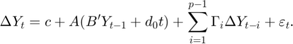
重要的是观察,VEC模型表达差异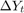 ,所以不受限制的常数(
,所以不受限制的常数( )代表相应的线性趋势水平
)代表相应的线性趋势水平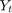 。
。
第二个模型是约翰森H1模型,模型常数也无限制,但没有协整关系包含时间趋势:
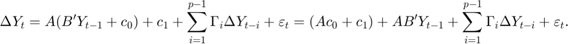
H1模型强调了无限制的性质不变:
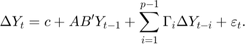
观察到H1模型是一个限制在H1 H *模型的参数化模型强加了一个额外的r限制参数的无限制的H *模型。具体来说,H1模型协整关系通过限制排除时间趋势= 0。协整关系时都会出现这种情况,随波逐流常见的线性趋势和趋势斜率线性趋势是相同的系列。
在这两种模型,反应

与创新
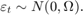
确定协整排名(r),使用Johansen假设检验函数jcitest默认情况下,它实现Johansen的跟踪测试。
jcitest返回一个逻辑决策指标(h)中,h= 1(真正)表示拒绝零协整排名(r)的替代和h= 0(假)表示拒绝零失败。检验统计量,后续输出是假定值的临界值,VEC模型参数的极大似然估计为每个协整测试。默认情况下,MATLAB®以表格的形式显示了测试结果。
P = 2;VEC模型(p - 1) %的数量落后Y = Data.Variables;%从时间表中提取所有数据方便[h, pValue,统计,cValue mleHstar] = jcitest (Y,“滞后”p - 1,“模型”,“H *”);[h, pValue,统计,cValue mleH1] = jcitest (Y,“滞后”p - 1,“模型”,“标题”);
* * * * * * * * * * * * * * * * * * * * * * * *结果汇总(试验1)数据:Y有效样本大小:238模型:H *滞后:1统计:跟踪显著性水平:0.05 r H stat cValue pValue eigVal - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 0 1 1 1 164.7259 117.7103 0.0010 0.3470 266.1410 150.5530 0.0010 105.0660 0.2217 - 2 1 3 0 88.8042 0.0028 0.1665 61.7326 63.8766 0.0748 0.1323 - 4 5 0 27.9494 42.9154 0.6336 0.0446 17.0919 25.8723 0.4470 0.0379 6 0 7.9062 12.5174 0.2927 0.0327 * * * * * * * * * * * * * * * * * * * * * * * *结果汇总(试验1)数据:Y有效样本大小:238模型:H1滞后:1统计:跟踪显著性水平:0.05 r H stat cValue pValue eigVal - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 0 1 261.9245 125.6176 0.0010 0.3460 1 2 1 160.8737 95.7541 0.0010 0.2212 101.3621 69.8187 0.0010 0.1661 3 1 58.1247 47.8564 0.0045 0.1323 13.4866 4 0 24.3440 29.7976 0.1866 0.0446 5 0 6 1 5.2631 3.8415 0.0219 0.0219 15.4948 0.0982 0.0340
H *测试结果表明,测试无法拒绝r= 3协整排名在5%的显著性水平,但不是在10%的水平r= 4无法拒绝(见假定值列5)。相比之下,H1测试强烈拒绝失败r= 4协整排名在5%的水平。因此,它似乎r= 4协整关系是合理的。
使用r= 4协整等级,确定哪两个模型更好地描述了数据通过使用两个likelihood-ratio-based测试方法。
第一种方法执行一个似然比测试使用lratiotest函数的H *模型是不受限制的模型和H1模型是限制模型r限制。由此产生的检验统计量渐近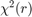 ,请参阅[8]p。342。
,请参阅[8]p。342。
使用lratiotest,提取loglikelihood值估计和H1模型返回的jcitest对协整排r= 4,然后执行一个似然比检验。
r = 4;%协整排uLogL = mleHstar.r4.rLL;% Loglikelihood无限制的H r = 4 *模型rLogL = mleH1.r4.rLL;% Loglikelihood限制的H1模型r = 4[h, pValue,统计,cValue] = lratiotest (uLogL rLogL, r)
h =逻辑0 pValue = 0.9618统计cValue = 9.4877 = 0.6111
测试失败拒绝限制H1模型。
第二种方法也进行似然比测试,但测试由向量张成的空间使用协整关系jcontest函数。以下测试确定是否可以实行零限制(一种排斥约束)的趋势系数H *的模型。具体来说,测试不包括在协整关系和时间趋势对整个经济系统的限制。从本质上讲,它决定是否限制在于协整向量平稳性的空间由协整矩阵,张成[6]175 - 178页。
一个H *模型限制对协整关系的线性时间趋势,你可以估计一个通过添加额外的行协整矩阵。这是通过重写H *模型更加突出:
![$ $ & # xA; \δY} {_t =左c + A \[开始\{数组}{c} B \ d0数组{}\ \端]& # xA;左\[开始\{数组}{c} Y_ {t - 1} \ \ t \结束数组{}\]+ \ sum_ {i = 1} ^ {p - 1} \ Gamma_i \三角洲{Y} _ {t -我}+左\ varepsilon_t = c + \[开始\ B{数组}{c} \ \数的数组{}\ \端]“左\[开始\{数组}{c} Y_ {t - 1} \ \ t \结束数组{}\]+ \ sum_ {i = 1} ^ {p - 1} \ Gamma_i \三角洲{Y} _ {t -我}+ \ varepsilon_t强生# xA; $ $](http://www.tatmou.com/es/es/help/examples/econ/win64/Demo_USEconModel_eq02738640285036516735.png)
现在,格式约束矩阵(R),这样
![$ $ & # xA; R '左\ [\ B开始{数组}{c} \ \ d0的\{数组}\]= \左右结束[\ 0开始{数组}{c} \ \ 0 \ 0 \ \ 0 \ \ 1 \结束数组{}\]左\[开始\ B{数组}{c} \ \数的数组{}\ \端)= 0 & # xA; $ $](http://www.tatmou.com/es/es/help/examples/econ/win64/Demo_USEconModel_eq02650731615522487550.png)
并进行测试使用jcontest。
R =[0(1、尺寸(Y, 2)) 1] ';%约束矩阵[h, pValue,统计,cValue] = jcontest (Y, r,“BCon”R“模型”,“H *”,“滞后”p - 1)
h =逻辑0 pValue = 0.9618统计cValue = 9.4877 = 0.6111
的jcontest和lratiotest结果是相同的,即决策失败拒绝限制H1模型。
总之,协整排的假设检验结果表明,模型4和H1 Johansen参数形式。协整关系的评估已经完成。
估计VARX模型的差异
可以表达VEC(1)模型作为VARX(1)模型协整关系预测的差异,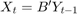 和调整矩阵(
和调整矩阵(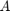 )是相应的回归系数:
)是相应的回归系数:
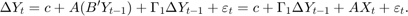
确定限制VARX的参数模型,重要的是要理解Johansen协整参数(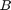 )在第一步估计收敛速度与样本规模成比例
)在第一步估计收敛速度与样本规模成比例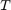 。因此,使用协整关系获得的第一步第二步的预测并不影响第二步VARX的分布参数。相比之下,第二步VARX参数的渐近正态分布和收敛速度
。因此,使用协整关系获得的第一步第二步的预测并不影响第二步VARX的分布参数。相比之下,第二步VARX参数的渐近正态分布和收敛速度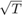 ,所以你可以解释他们t统计数据以通常的方式。
,所以你可以解释他们t统计数据以通常的方式。
当你使用季度经济数据,你应该关心over-parameterization模型相对于样本容量的估计。这是理由的一部分使用低滞后长度。
估计一个基线模型使用估计函数。返回参数估计的标准误差,这样您就可以计算t统计数据和使用它们来进一步限制VEC(1)初步估计基线模型。
(Mdl, se) =估计(结果(大小(Y, 2)、r p - 1), Y,“模型”,“标题”);
因为VARX是渐近正态分布的参数估计错误,可以减轻over-parameterization和提高样本外预测性能的影响排除(设置为零),VARX参数t统计在绝对值小于2。
创建一个VEC模型相同的参数形式作为基准模型Mdl,但排除限制强加于第二步的VARX参数包括常数()、短期矩阵(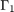 ),调整矩阵()。参考指排除限制子集的限制,这是一个特例VEC支持的个人约束的类型和VAR模型。金宝app
),调整矩阵()。参考指排除限制子集的限制,这是一个特例VEC支持的个人约束的类型和VAR模型。金宝app
“=结果(Mdl。NumSeries Mdl。排名,Mdl。P - 1);toFit.Constant (abs (Mdl。常数。/ se.Constant) < 2) = 0;toFit.ShortRun {1} (abs (Mdl。短期的{1}。/ se.ShortRun {1}) < 2) = 0;toFit.Adjustment (abs (Mdl。调整。/ se.Adjustment) < 2) = 0;
符合限制H1模型,然后情节最后参考模型的协整关系。
适合=估计(“Y“模型”,“标题”);B =[健康。协整;健康。CointegrationConstant ';Fit.CointegrationTrend ');图绘制(数据。时间,[Y的(大小(Y, 1), 1)(-(健康。P- 1):(size(Y,1) - Fit.P))'] * B) recessionplot title(“协整关系”)

情节表明协整关系约静止不动的,虽然时间的波动性和突变出现集群在经济衰退。
脉冲响应分析
当经济状况的改变,特别是在应对政策的决定,你可以评估系统使用一个脉冲响应的灵敏度分析。
计算脉冲响应函数(IRF)名义GDP的一个标准差的冲击,经济变量使用armairf函数。默认情况下,armairf显示了使正交化剩余的脉冲响应协方差矩阵是由它的柯列斯基分解使正交化。的armairf功能也支持金宝app广义脉冲响应Pesaran和胫骨[10]结果,但对于名义GDP在概要文件是相似的。
的armairf函数返回世界宗教自由在一个三维数组。每一页(三维)捕捉一个特定变量的响应,在给定预测地平线,系统中所有变量的一个标准差的冲击。具体来说,元素t,j,k变量的反应吗k在时间t在预测地平线,一个创新冲击变量j在时间为0。列和页面对应于响应变量的数据,和t= 0,1,……跳频,在那里跳频预测的时间跨度是长度。
安装VEC模型转换为其共合体使用VAR表示varm转换函数。然后,计算世界宗教自由40季度(10年)。
地平线= 40;VAR = varm(配合);IRF = armairf (VAR。基于“增大化现实”技术,{},“InnovCov”VAR.Covariance,“NumObs”地平线);h =图;iSeries = 1;%第1列与GDP相关系列为我= 1:Mdl。NumSeries次要情节(Mdl.NumSeries 1 i)情节(IRF(:,我,iSeries))标题(“GDP脉冲响应”+ Data.Properties.VariableNames (i))结束屏幕=得到(h,“父”);集(h,“位置”,(h.Position (1) screen.MonitorPositions (4) * 0.1 h.Position (3) screen.MonitorPositions (4) * 0.8));

虽然前面的情节显示脉冲响应历时10年,实际上每个响应方法稳态渐近水平表明单位根和表明冲击是持久和对名义GDP产生永久性影响。
计算样本外预测和评估预测的准确性
为了测试模型的准确性,迭代计算样本外预测。执行一个实验类似于手中,建议和伍特斯[13],页21 - 22:
VEC模型估计在最初的20年的样本期间1957:Q1 - 1976:第四季度
预测数据的1、2、3、4季度进入未来。
重新评估模型在此期间1957:Q1 - 1977: Q1,下个季度的数据添加到样本从而增加可用的样本容量估计。
重复步骤2和3,积累的时间序列预测,直到结束的样本。
Y =数据;%的工作直接与时间表T0 = datetime (1976、12、31);%初始化预测起源(31 - 12月- 1976 =(1976、12、31)三联体)T = T0;地平线= 4;%预测地平线上季度(4 = 1年)numForecasts =元素个数(Y.Time (timerange (T, Y.Time(结束),“关闭”)))-层;yForecast =南(numForecasts,地平线,Mdl.NumSeries);为t = 1: numForecasts%%得到end-of-quarter日期为当前预测起源。%quarterlyDates = timerange (Y.Time (1), T,“关闭”);%% VEC模型估计。%适合=估计(“Y {quarterlyDates:},“模型”,“标题”);%%每季度预测模型在预测地平线。%%存储当前预估起源(T)作为一个三维数组中% 1页存储所有预估第一系列(GDP),第二页%存储所有预估第二系列(GDPDEF),等等。这%存储公约促进数据的访问时间表%下面创建的预测。%yForecast (t):,) =预测(健康,地平线,Y {quarterlyDates:});%%更新预测来源包括下个季度的数据。%T = dateshift (T)“结束”,“季”,“下一个”);结束
计算预测日期共同起源预测预测地平线,和特定的季度日期的每个预测应用。然后,创建一个时间表的常见的时间戳(每一行)的日期是每个季度预测。在每个预测起源、商店的预测每个7系列1,2,3,4季度未来,以及每个预测的季度日期适用。时间表是格式化的方式促进访问给定的经济系列的预测。
originDates = dateshift (T0,“结束”,“季”(0:(numForecasts-1)));forecastDates = NaT (numForecasts,地平线);为i = 1:地平线forecastDates (:, i) = dateshift (originDates,“结束”,“季”,我);结束预测=时间表(forecastDates,“RowTimes”originDates,“VariableNames”,{“次”});为i = 1:尺寸(Y, 2)预期。(Y.Properties.VariableNames{我})= yForecast(:,:我);结束
用迭代预测,评估实际GDP的预测精度(名义国内生产总值GDP平减物价指数网)通过绘制其预测和真实的报道值预测地平线(4-quarters-ahead)。同时,绘制相应的预测错误。
forecastRealGDP = Forecast.GDP (:, 4)——Forecast.GDPDEF (:, 4);realGDP = Y.GDP (Forecast.Times (:, 4))——Y.GDPDEF (Forecast.Times (:, 4));图次要情节(2,1,1)情节(Forecast.Times (:, 4), forecastRealGDP,“r”)举行在情节(Forecast.Times (: 4), realGDP,“b”)标题(“实际GDP与预测:4-Quarters-Ahead”)ylabel (“美元”)recessionplot h =传奇(“预测”,“实际”,“位置”,“最佳”);h。盒=“关闭”;次要情节(2,1,2)情节(Forecast.Times (:, 4), forecastRealGDP - realGDP)标题(“实际GDP预测误差:4-Quarters-Ahead”)ylabel (“美元”)recessionplot
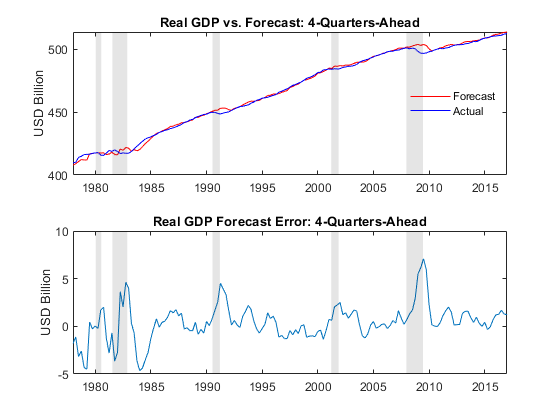
期间和之后的情节说明经济衰退时期GDP预测倾向于高估真实GDP。特别是,观察大积极错误后2008年的财政危机和2009年上半年。
供参考,虽然故事情节不显示无约束VARX模型的预测误差不排斥限制不变,短期,和调整参数,限制导致情节代表大约减少了25%的均方根误差(RMSE)实际GDP的预测。
分析2008年的财政危机:预测实际国内生产总值
附近的调查预测2008年的财政危机的更多细节。具体地说,探讨预测性能随着经济危机之前转换到衰退,然后又在危机后的复苏。出于完整性的考虑,检查使用最新数据的预测行为。
风格的手中和伍特斯[13]使用12-quarter(3年)预测地平线。为了将预测超过一个系列的,检查实际国内生产总值。
估计和预测未来12个季度实际国内生产总值数据,2007年底,抵押贷款危机之前。
地平线= 12;T = datetime (2007、12、31);%预测危机起源之前(31 - 12月- 2007 =(2007、12、31)三联体)适合=估计(“Y {timerange (Y.Time (1), T,“关闭”):},“模型”,“标题”);[yForecast, yMSE] =预测(健康,地平线,Y {timerange (Y.Time (1), T,“关闭”):});σ= 0(地平线,1);%的预测标准误差为i = 1:地平线σ(i) = sqrt (yMSE{我}(1,1)- 2 * yMSE{我}(1、2)+ yMSE{我}(2,2));结束forecastDates = dateshift (T)“结束”,“季”1:地平线);图绘制(forecastDates (yForecast (: 1)——yForecast(:, 2)) +σ,“r”)举行在情节(forecastDates yForecast (: 1)——yForecast (:, 2),“r”)情节(forecastDates (yForecast (: 1)——yForecast(:, 2)) -σ,“r”)情节(forecastDates Y.GDP (forecastDates)——Y.GDPDEF (forecastDates),“b”)标题(“实际GDP与12-Q预测:起源= "+字符串(T)) ylabel (“美元”)recessionplot h =传奇(“预测+ 1 \σ”,“预测”,“预测σ1 \”,“实际”,“位置”,“最佳”);h。盒=“关闭”;

估计模型未能预测戏剧性的经济衰退。考虑到危机的严重性,未能捕捉到经济衰退的程度,也许,有些奇怪。
估计和预测未来12个季度实际GDP数据到2009年中期,也就是在抵押贷款危机之后。
T = datetime (2009、6、30);%预测危机起源后(30 - 2009年6月- =(2009、6、30)三联体)适合=估计(“Y {timerange (Y.Time (1), T,“关闭”):},“模型”,“标题”);[yForecast, yMSE] =预测(健康,地平线,Y {timerange (Y.Time (1), T,“关闭”):});σ= 0(地平线,1);%的预测标准误差为i = 1:地平线σ(i) = sqrt (yMSE{我}(1,1)- 2 * yMSE{我}(1、2)+ yMSE{我}(2,2));结束forecastDates = dateshift (T)“结束”,“季”1:地平线);图绘制(forecastDates (yForecast (: 1)——yForecast(:, 2)) +σ,“r”)举行在情节(forecastDates yForecast (: 1)——yForecast (:, 2),“r”)情节(forecastDates (yForecast (: 1)——yForecast(:, 2)) -σ,“r”)情节(forecastDates Y.GDP (forecastDates)——Y.GDPDEF (forecastDates),“b”)标题(“实际GDP与12-Q预测:起源= "+字符串(T)) ylabel (“美元”)h =传奇(“预测+ 1 \σ”,“预测”,“预测σ1 \”,“实际”,“位置”,“最佳”);h。盒=“关闭”;
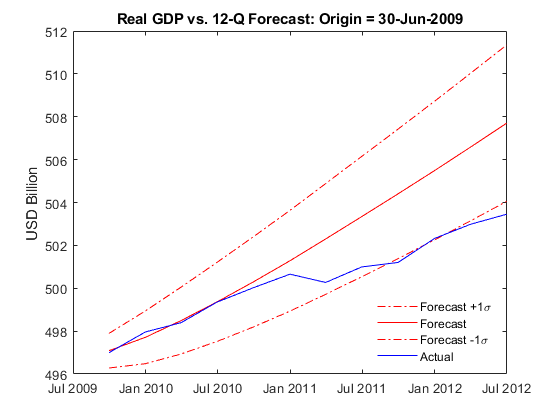
一旦经济衰退数据包含在估计,实际GDP的预测相当不错同意真正的价值观。预测的时间跨度虽然超出了2年,预期仍然存在过度乐观的经济复苏。
最后,结合后危机时代的最新统计数据。
T = dateshift (Data.Time(结束),“结束”,“季”地平线);适合=估计(“Y {timerange (Y.Time (1), T,“关闭”):},“模型”,“标题”);[yForecast, yMSE] =预测(健康,地平线,Y {timerange (Y.Time (1), T,“关闭”):});σ= 0(地平线,1);%的预测标准误差为i = 1:地平线σ(i) = sqrt (yMSE{我}(1,1)- 2 * yMSE{我}(1、2)+ yMSE{我}(2,2));结束forecastDates = dateshift (T)“结束”,“季”1:地平线);图绘制(forecastDates (yForecast (: 1)——yForecast(:, 2)) +σ,“r”)举行在情节(forecastDates yForecast (: 1)——yForecast (:, 2),“r”)情节(forecastDates (yForecast (: 1)——yForecast(:, 2)) -σ,“r”)情节(forecastDates Y.GDP (forecastDates)——Y.GDPDEF (forecastDates),“b”)标题(“实际GDP与12-Q预测:起源= "+字符串(T)) ylabel (“美元”)h =传奇(“预测+ 1 \σ”,“预测”,“预测σ1 \”,“实际”,“位置”,“最佳”);h。盒=“关闭”;
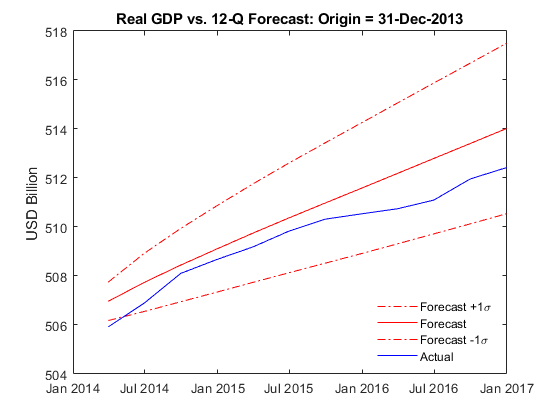
现在恢复了一些势头和稳定,三年预测同意与真实值更紧密地合作。
业者进行灵敏度:伟大的通货膨胀与伟大的节制
检查的稳定性和灵敏度分析,比较两种截然不同的次级样本的估计结果。
遵循了手中,武泰的方法[13]页,28 - 29日通过执行假设敏感性分析,称为反事实的实验。检查模型的响应拟合数据在一个周期内冲击来自模型拟合。
具体来说,手中和武泰识别结束在1979年:Q2的任命保罗沃尔克理事会主席的美国联邦储备理事会(美联储,fed)的大通胀1984年,开始:Q1的大缓和。大通胀和大缓和之间的差距,显然,一个过渡时期,包括1980年代的两次经济衰退。
VEC模型估计,在此期间1957:1979 Q1: Q2,然后又从1984年:第一季度的最新季度数据是可用的。虽然相同的pre-estimation模型评估执行完整的样品上面可以为每个业者进行重复,为简单起见VEC模型和子集保留相同的约束之前使用。
T1 = datetime (1979、6、30);%第四季度大通胀(30 - 1979年6月- =(1979、6、30)三联体)日元= Y (timerange (Y.Time (1), T1,“关闭”):);%大通胀数据[Fit1, ~, ~, E1] =估计(Y1.Variables“,“模型”,“标题”);T2 = datetime (1984、3、31);%第一季度大缓和(31 - 3月- 1984 =(1984、3、31)三联体)Y2 = Y (timerange (T2, Y.Time(结束),“关闭”):);%大稳健数据Y2.Variables Fit2 =估计(“,“模型”,“标题”);
过滤推断从第一业者获得残差(大通胀)通过模型从最近获得业者(大缓和)使用过滤器函数。
更好地比较下面的过滤反应得到的拟合结果大缓和了,初始化滤波器使用第一个P的观察大缓和业者。换句话说,尽管大通胀的残差推断过滤器通过拟合模型获得伟大的节制,你使用数据从一开始初始化滤波器的节制。
YY =过滤器(Fit2 E1,“Y0”、Y2 {1: Fit2.P,:}“规模”、假);Y2 = Y2 ((Fit2。P+ 1):(size(E1,1) + Fit2.P),:);%提取相关数据,方便比较YY = array2timetable (YY,“RowTimes”Y2.Time,“VariableNames”,Y.Properties.VariableNames);
比较实际GDP数据公布在大稳健滤波得到的大通胀的冲击,通过模型拟合适度。
图绘制(YY。时间,Y2。GDP——Y2.GDPDEF“b”)举行在情节(YY。时间,YY。GDP——YY.GDPDEF“r”)标题(的实际GDP业者进行比较)ylabel (“美元”)recessionplot h =传奇(“大缓和数据报告”,“大通胀过滤剩余工资”,“位置”,“最佳”);h。盒=“关闭”;
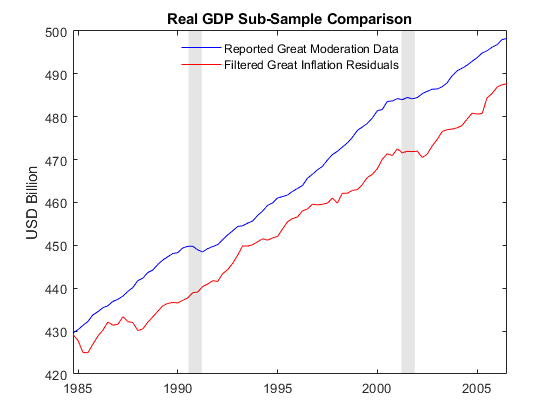
情节表明,过滤后的结果比报道大缓和波动数据,观察指出手中和伍特斯[13],30页。
执行过滤器的过滤从大通胀获得残差模型拟合大缓和,但在更广泛的历史模拟代表只有一个选择,过滤和预测框架。
例如,尽管分析这一点主要关注GDP,有趣的是,分析还提供了一个合理的准确表示其他系列,可能除了短期利率(FEDFUNDS)。
在Smets-Wouters模型中,只剩下系列未经调整的利率。此外,手中和武泰包括数据只能通过2004年底,抵押贷款危机之前。在2004年底短期利率已经处于低水平,然而实际上接近零2008年底财政危机随之而来,经济衰退开始了。尽管经济复苏,利率保持在历史低位数年。
VEC模型是考虑到VAR和真正的线性近似,未知向量过程的依赖被多元高斯分布,这并不令人惊讶,遇到负利率。事实上,尽管FEDFUNDS利率从未负的,其他短期有息账户,特别是在欧洲,已经知道提供负收益率。
有条件的预测与仿真
有条件的分析密切相关压力测试。具体来说,提前指定的变量值的一个子集,经常受到不利条件和极端值,为了评估影响其余变量在经济危机时期。
一个经济时间序列建模方法接近于零的利率执行有条件的预测和仿真用模型拟合大缓和捕捉最新的数据。
具体来说,分析了10年的经济预测来自国会预算办公室(CBO)[1]出版的季度预估以下子集弗雷德系列:
CBO系列描述- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -国内生产总值占国内生产总值(GDP)占国内生产总值(GDP)(十亿美元)GDPDEF内含平减物价指数(指数2009 = 100)COE支付薪酬的员工(数十亿美元)TB3M三个月期国库券(折合成年率百分比)
虽然三个月期国库券us3mt =和FEDFUNDS利率不相同,近年来,他们几乎是没有区别的。所以,你可以使用三个月期国库券us3mt = rr收益率代表FEDFUNDS率。
获得有条件的预测,建立一个时间表,CBO预测捕捉已知数据未知的未来演化预测条件。当格式化的时间表,南值显示未知(失踪)预测条件(non-missing)信息。
至于弗雷德系列、所有CBO系列除了短期利率转换。转换系列并将它们存储在一个新的时间表(YF),它捕获的子集系列提前知道,是你的数据计算出剩余的预测。
YF =国会预算办公室;%分配日期和原始数据YF。国内生产总值= 100 *日志(CBO.GDP);% %(输出)YF。GDPDEF = 100 *日志(CBO.GDPDEF);% GDP隐含价格平减指数YF。COE = 100 *日志(CBO.COE);%员工薪酬(工资)
检查去年4季度CBO预测和观察,工作时间(HOANBS),消费(PCEC)和投资(GPDI)失踪(nan)因为CBO并不为这些系列发布的预测,而GDP、GDP平减指数(GDPDEF),补偿(COE), FEDFUNDS包含CBO预测。
YF (end-3:,)
ans = 4 x7时间表时间GDP GDPDEF COE HOANBS FEDFUNDS PCEC GPDI ___________交交________ ____ ____ 31 - 3月- 2027 2.8 1023.5 492.1 963.14南南南30 - 2027年6月- 1024.4 492.6 964.07 2.8南南南30 - 9 - 2027 2.8 1025.4 493.09 964.99南南南31 - 12月- 2027 1026.3 493.59 965.89 2.8南南南
比较实际GDP的预测来自国会预算办公室预测,从有条件获得VEC模型的预测。名义国内生产总值(GDP)预测有条件地设置CBO预测的名义GDP nan表示缺乏信息的名义GDP。显示去年4季度预测。
YF.GDP(:) =南;YF (end-3:,)
ans = 4 x7时间表时间GDP GDPDEF COE HOANBS FEDFUNDS PCEC GPDI ___________看上去___长得一样________ ____ ____ 31 - 3月- 2027年南492.1 - 963.14南南南30 - 2.8 2.8 492.6 - 964.07 2027年6月,南南南南30 - 9月2.8 493.09 - 964.99 - 2027南南南南2027年- 12月31日南493.59 2.8 965.89南南南
提取季度CBO预测之外的日期最近的弗雷德数据和预测未知的系列条件的预测。
的预测VEC模型转换为等价的整数阶,使用卡尔曼滤波器,失踪的预测。缺失值成为过滤状态计算的最小均方误差(MMSE)条件期望。
forecastQuarters = timerange (Y.Time(结束),CBO.Time(结束),“openleft”);YF = YF (forecastQuarters:);yForecast =预测(Fit2、大小(YF, 1), Y.Variables,“。”,YF.Variables);yForecast = array2timetable (yForecast,“RowTimes”YF.Time,“VariableNames”,Y.Properties.VariableNames);
检查结果发现失踪的GDP, HOANBS, PCEC,和GPDI系列填充条件预测,尽管GDPDEF, COE, FEDFUNDS系列用于调节不变。
yForecast (end-3:,)
ans = 4 x7时间表时间GDP GDPDEF COE HOANBS FEDFUNDS PCEC GPDI ___________交交________交31 - 3月- 2027 1024.1 492.1 963.14 488.27 2.8 987.67 837.48 30 - 1025年6月- 2027 492.6 964.07 488.69 2.8 988.6 838.42 9月30 - 31 - 2027 1025.9 493.09 964.99 489.05 2.8 989.5 838.98 - 12月- 2027 1026.7 493.59 965.89 489.4 2.8 990.38 839.51
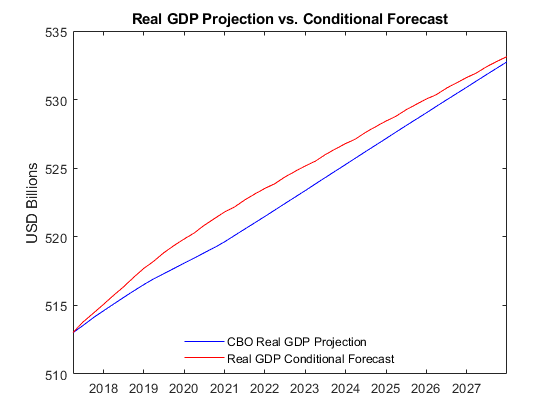
比较实际国内生产总值来自条件预测来自国会预算办公室预测。密切观察,他们同意。
图绘制(YF。时间,100 *日志(CBO.GDP (forecastQuarters))——YF.GDPDEF“b”)举行在情节(YF。时间,yForecast。GDP——yForecast.GDPDEF“r”)标题(“实际GDP投影与条件预测”)ylabel (数十亿美元的)h =传奇(“国会预算办公室实际GDP投影”,“实际GDP条件预测”,“位置”,“最佳”);h。盒=“关闭”;
不仅限于条件分析预测,和扩展模拟。nan和non-NaNs模式YF,你可以嫁祸于未知值的采样条件,多元高斯分布。
模拟1000条件样本路径模拟函数。
rng默认的YY =模拟(Fit2、大小(YF, 1),“Y0”Y.Variables,“。”YF.Variables,“NumPaths”,1000);
情节,例如,第一个10样本路径的实际国内生产总值。
图为我= 1:10情节(YF。我时间,YY (: 1)——YY(:, 2,我))在结束标题(“实际GDP样本路径”)ylabel (“美元”)

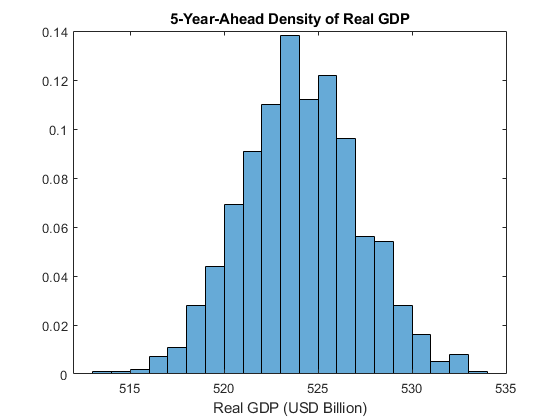
情节表明实际GDP的分布变化明显作为时间的函数,所以感兴趣的另一个指标是实际GDP的分布。
情节的经验概率密度函数(PDF) 5年实际GDP(20人)到未来。
YY =排列(挤压(YY (20::)), 1 [2]);图直方图(YY (: 1)——YY (:, 2),“归一化”,“pdf”)包含(的实际国内生产总值(亿美元))标题(“实际GDP 5-Year-Ahead密度”)
引用
[1]国会预算办公室、预算和经济数据,10年的经济预测,https://www.cbo.gov/data/budget-economic-data。
[2]▽黑人,M。,Schorfheide, F., Smets, F. and Wouters, R. "On the Fit of New Keynesian Models."商业和经济统计》杂志上。2号卷。25日,2007年,页123 - 162。
[3]汉密尔顿,詹姆斯D。时间序列分析。普林斯顿,纽约:普林斯顿大学出版社,1994年。
[4]约翰森,S。基于可能性推理在共合体向量自回归模型。牛津:牛津大学出版社,1995年。
[5]Juselius, K。共合体VAR模型。牛津:牛津大学出版社,2006年。
[6]金博,M。“基本的定量分析Neomonetarist模式。”杂志的钱,信贷,银行,第2部分:流动性,货币政策,金融中介。27卷,第4期,1995年,页1241 - 1277。
[7]Lutkepohl,赫尔穆特·马库斯Kratzig、编辑。应用时间序列计量经济学。第1版。剑桥大学出版社,2004年。https://doi.org/10.1017/CBO9780511606885。
[8]Lutkepohl,赫尔穆特。新的多元时间序列分析的介绍。纽约,纽约州:斯普林格出版社,2007年版。
[9]国家经济研究局(NBER),商业周期的扩张和收缩,https://www.nber.org/research/data/us-business-cycle-expansions-and-contractions。
[10]Pesaran, H . H。,和Y. Shin. "Generalized Impulse Response Analysis in Linear Multivariate Models."经济上的字母。58卷,1998年,17 - 29页。
[11]手中,f .武泰,R。“估计随机动态一般均衡模型欧元区。”欧洲央行(ecb)、工作报告系列。171号,2002年。
[12]手中,f .武泰,R。“对比美国和欧元区的冲击和摩擦商业周期:贝叶斯动态随机一般均衡模型的方法。”欧洲央行(ecb)、工作报告系列。391号,2004年。
[13]手中,f .武泰,R。“美国商业周期冲击和摩擦:贝叶斯动态随机一般均衡模型的方法。”欧洲央行(ecb)、工作报告系列。722号,2007年。
[14]美国联邦储备理事会(美联储,fed)的经济数据(FRED),联邦储备银行圣路易斯https://fred.stlouisfed.org/。