利用极值理论和copula评估市场风险
这个例子展示了如何用蒙特卡洛模拟技术,使用学生的t联系函数和极值理论(EVT)来模拟一个假设的全球股票指数投资组合的市场风险。该过程首先利用非对称GARCH模型从每个收益序列中提取过滤后的残差,然后利用内部的高斯核估计和上下尾部的广义Pareto分布估计构建每个资产的样本边际累积分布函数(CDF)。然后对数据进行拟合,并使用Student's t copula来诱导每个资产的模拟残差之间的相关性。最后,模拟评估了一个月内假设的全球股票投资组合的风险价值(VaR)。
请注意,这是一个相对高级、全面的示例,假设您对EVT和copula有所了解。关于广义Pareto分布的估计和copula模拟的详细信息,请参见用广义帕吻码分布建模尾数据和使用Copulas模拟依赖随机变量在统计和机器学习工具箱™。有关本示例大部分所基于的方法的详细信息,请参见[5]和[6]).
检查全球股权指数数据的日常关闭
原始数据由跨越交易日期27-九九393年至2003年7月14日至7月14日至2003年的以下代表性股票指数的日常收盘价值2665年的日常闭幕价值观。
加拿大:TSX综合(Ticker ^ GSPTSE)法国:CAC 40(Ticker ^ Fchi)德国:DAX(Ticker ^ Gdaxi)日本:Nikkei 225(Ticker ^ N225)UK:FTSE 100(Ticker ^ FTSE)US:标准普尔500指数(Ticker^ GSPC)
负载data_globalidx1.%每日进口指数收盘
以下绘图说明了每个索引的相对价格运动。每个索引的初始水平已被标准化为Unity,以便于比较相对性能,并且没有明确考虑股息调整。
图绘图(日期,Ret2price(Price2ret(数据)))DateTick(“x”)xlabel(“日期”)ylabel('指数值') 标题 (“相对每日指数收盘”)传奇(系列,'地点','西北')

在为后续建模做准备时,将每个指数的收盘水平转换为每日对数回报(有时称为几何回报,或连续复合回报)。
返回= price2ret(数据);%对数返回T =大小(回报,1);%返回数量(即,历史样本大小)
由于在整体建模方法的第一步涉及到重复应用GARCH过滤和极值理论来描述每个单独的股票指数回报序列的分布,这有助于检查特定国家的细节。您可以将下一行代码更改为集合{1,2,3,4,5,6}中的任意整数,以检查任何索引的详细信息。
指数= 1;%1 =加拿大,2 =法国,3 =德国,4 =日本,5 =英国,6 =美国Figure plot(date (2:end), returns(:,index))“x”)xlabel(“日期”)ylabel(“返回”)标题(“每日对数收益”)
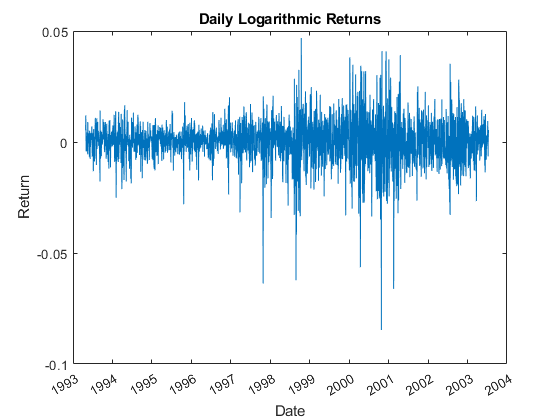
筛选每个索引的返回值
用GPD模拟分布的尾部需要观测值近似独立且同分布(i.i.d)。然而,大多数财务收益序列表现出一定程度的自相关,更重要的是,异方差。
例如,与所选指数相关的回报的样本自相关函数(ACF)显示出一些轻微的序列相关性。
图autocorr(返回(:,指数))标题(“退货ACF样本”)

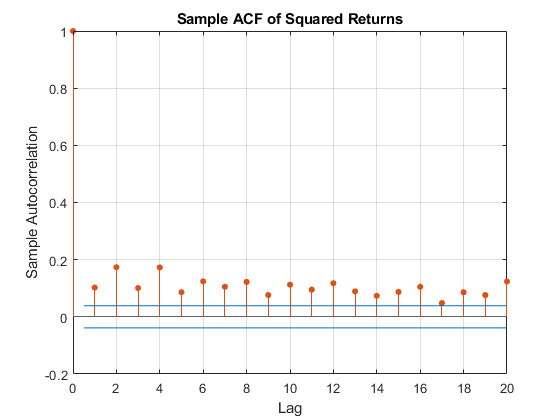
然而,平方返回的样本ACF说明了方差的持续性程度,并暗示GARCH建模可能显著地限制了后续尾估计过程中使用的数据。
图autocorr(返回(:,指数)。^ 2)标题(“平方回报的样本ACF”)
为了产生一系列的i.i.d.观察,拟合一阶自回归模型到每个股票指数回报的条件均值

与条件方差的不对称加法模型

第一阶自回归模型补偿自相关,而GARCH模型可补偿异质瘢痕性。特别地,最后一个术语包含不对称(杠杆),通过布尔指示器的差异,如果先前的模型残差为负,否则为0,则为0(参见[3]).
此外,每个指数的标准化残差被建模为标准化的学生的T分布,以补偿通常与股权回报相关的脂肪尾。那是

下面的代码段从每个股票指数的收益中提取过滤后的残差和条件方差。
型号= Arima(基于“增大化现实”技术的,楠,'分配',“t”,'方差'gjr (1,1));nIndices =大小(数据,2);索引% #残差= NaN(T,Nindices);%preallocate存储variances = nan(t,nindices);适合=细胞(Nindices,1);选项= Optimoptions(@Fmincon,“显示”,“关闭”,......'诊断',“关闭”,“算法”,“sqp”,'tolcon'1 e);为i = 1:nindices fit {i} =估计(模型,返回(:,i),“显示”,“关闭”,'选项'、选择);(残差(:,i)、方差(:,我)]=推断(适合{我},返回(:,我));结束
对于所选索引,比较模型残差和从原始返回滤除的相应条件标准偏差。下图清楚地说明了过滤残留物中存在的挥发性(异源性瘢痕度)的变化。
图subplot(2,1,1) plot(date (2:end), residuals(:,index)) datetick(“x”)xlabel(“日期”)ylabel('剩余的') 标题 ('过滤残留') subplot(2,1,2) plot(date (2:end), sqrt(variance (:,index))) datetick(“x”)xlabel(“日期”)ylabel('挥发性') 标题 ('过滤条件标准偏差')
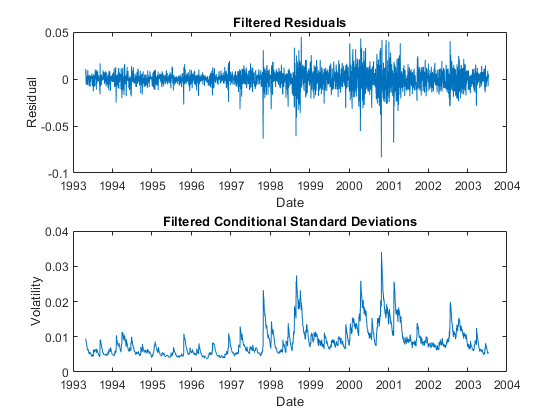
从每个收益序列中过滤出模型残差后,用相应的条件标准差对残差进行标准化。这些标准化残差代表潜在的零均值、单位方差、i.i.d.系列,样本CDF尾的EVT估计是基于这些系列。
残差=残差./ sqrt(variances);
要结束本节,请检查标准化残留和平方标准化残留的ACF。
将标准化残差的ACF与原始回报的相应ACF进行比较显示标准化残差现在大约是I.I.D。因此,远远超过后续尾估计。
figure autocorr(残差(:,索引))标题(“标准化残差的样本ACF”)图autocorr(residuals(:,index).^2)'平方标准化残差的样本ACF')


估计半参数cdf
鉴于标准化,i.i.d.从上一步中的残差,用高斯内核估计每个索引的经验CDF。这使CDF估计平滑,消除了无缝样品CDF的楼梯模式。尽管非参数核CDF估计非常适合于发现大多数数据的分布的内部,但是当施加到上部和下尾时,它们往往会表现不佳。为了更好地估计分配的尾部,将EVT应用于每个尾部的那些残留物。
具体地说,找到上下限阈值,以便为每条尾巴保留10%的残差。然后用最大似然法将每个尾部的极端残差超出相关阈值的数量拟合为参数GPD。这种方法通常被称为分布超标或者超过门槛的峰值方法。
鉴于每个尾部的超标,优化负值对数似函数来估计GPD的尾索引(Zeta)和比例(β)参数。
以下代码段创建类型的对象Paretotails.,每个索引返回序列都有一个这样的对象。这些paretotails对象封装了参数化GP下尾、非参数核光滑内部和参数化GP上尾的估计,为每个指标构造了一个复合半参数CDF。
得到的分段分布对象允许在CDF内部进行插值,并在每个尾部进行外推(函数评估)。推断是非常可取的,它允许对历史记录之外的分位数进行估计,对于风险管理应用程序来说是无价的。
此外,Pareto tail对象还提供了计算CDF和反CDF(分位数函数)的方法,以及查询分段分布各分段之间边界的累积概率和分位数的方法。
nPoints = 200;CDF的每个区域中的%#采样点数tailFraction = 0.1;分配给每个尾部的残留物的%小数尾部=细胞(nindices,1);帕累托尾部对象的单元格数组为i = 1:nindices tails {i} = paretotails(残留物(:,i),taymfraction,1 - tay tay tay,“内核”);结束
估计了复合半参数经验CDF的三个不同区域,图形连接并显示结果。再次注意,分别显示为红色和蓝色的下尾和上尾区域适合于外推,而核平滑的内部(黑色)适合于插值。
下面的代码用非适合所基于的数据调用感兴趣的Pareto tail对象的CDF和反CDF方法。具体来说,参考方法可以访问拟合状态,现在可以调用这些方法来选择和分析概率曲线的特定区域,作为一种强大的数据过滤机制。
图持有在网格在minprobability = cdf(tails {index},(min(残差(:,索引))))));maxprobability = cdf(tails {index},(max(残差(indems(:,索引))))));plowertail = linspace(minprobability,taymfraction,npoints);%样本下尾Puppertail = Linspace(1 - Taymfraction,MaxProbability,NPoints);样品上尾%pInterior = linspace(tailFraction, 1 - tailFraction, nPoints);%样品内部绘图(ICDF(尾部{Index},Plowertail),Plowertail,“红色”,'行宽',2)情节(ICDF(尾部{指数},Pinterior),Pinterior,'黑色的','行宽', 2) plot(icdf(tails{index}, pUpperTail), pUpperTail,“蓝”,'行宽',2)xlabel('标准化残留')ylabel(“概率”)标题(“经验提供”)({传奇'帕累托下尾''内核平滑内部'......'帕累托上尾'},'地点','西北')

评估GPD匹配度
虽然前面的图表说明了复合CDF,但更详细地检查GPD适合性是有指导意义的。
GP分布的CDF参数化为

对于超越(y),尾指数参数(zeta)和刻度参数(beta)。
为了视觉评估GPD拟合,将残留物的上尾超标的经验CDF与GPD装配的CDF绘制。虽然仅使用了10%的标准化残留物,但拟合的分布密切相关,因此GPD模型似乎是一个不错的选择。
figure [P,Q] = boundary(tails{index});边界的%累积概率和量子y = sort(残差(残差(:,index)> q(2),索引) - q(2));%排序超标情节(y) (cdf(反面{指数},y + Q (2)) - P (2)) / P (1)) (F (x) = ecdf (y);%经验提供持有在楼梯(x,f,“r”网格)在传奇(“拟合广义Pareto CDF”,“经验提供”,'地点','东南');包含(“超过数”)ylabel(“概率”)标题('标准化残留的上尾')

校准t Copula
鉴于标准化残差,现在估计使用T copula的标量参数(DOF)和线性相关矩阵(R)使用COPULAFIT.函数可在统计和机器学习工具箱中找到。的COPULAFIT.函数允许用户通过两种不同的方法估计t copula的参数。
默认方法是一种形式化的最大似然方法,执行两步过程。
具体来说,虽然完全对数似然可以直接最大化,但在多维空间中目标函数的最大值往往出现在长、平、窄的谷中,在高维空间中可能会出现收敛困难。为了规避这些困难,COPULAFIT.最大似然估计(MLE)分两步进行。内步长最大化了线性相关矩阵的对数似然,给定一个固定的自由度值。条件最大化被放置在关于自由度的一维最大化中,从而最大化所有参数的对数可能性。在这个外部步骤中被最大化的函数被称为自由度的轮廓对数似然函数。
相反,下面的代码段使用了一种替代方法,它近似于大样本规模下自由度参数的配置文件对数似然值。尽管这种方法通常比MLE快得多,但使用时应谨慎,因为对于小或中等样本量的估计和置信限可能不准确。
具体地说,近似是通过对线性相关矩阵的对数似然函数微分得到的,假设自由度是一个固定的常数。由此得到的非线性方程,然后迭代求解相关矩阵。这个迭代又嵌套在另一个优化中,以估计自由度。该方法在本质上类似于上述的剖面对数似然法,但不是一个真正的最大似然法,因为在给定的自由度下,相关矩阵不收敛于条件最大似然法。然而,对于大的样本量,估计值通常非常接近MLE(见[1]和[7]).
另一种方法是先计算样本秩相关矩阵(Kendall’s或Spearman’s),然后通过鲁棒正弦变换将秩相关转换为线性相关。给定这个线性相关矩阵的估计,对数似然函数然后是最大的关于自由度参数单独。这种方法似乎也受到profile log-likelihood方法的启发,但根本不是MLE方法。然而,这种方法不需要矩阵反演,因此在存在接近奇异的相关矩阵时具有数值稳定的优势(见[8]).
最后是Nystrom和Skoglund[6]建议将自由度参数保留为用户指定的仿真输入,从而允许用户主观地诱导资产之间的尾部依赖程度。特别是,他们建议一个相对较低的自由度,在1到2之间,这样就可以更仔细地检查关节极端的可能性。这种方法对压力测试是有用的,其中极端相互依赖的程度是至关重要的。
下面的代码段首先将标准化的残差转换为均匀变体通过上面导出的半参数验证CDF,然后将T copula符合转换数据。当通过每个边距的经验CDF转换均匀变体时,校准方法通常称为规范最大可能性(CML)。
U = 0(大小(残差));为i = 1: nIndices U (:, i) = cdf(反面{我},残差(:,我));%变成制服边距结束[R, DoF] = copulafit“t”,你,'方法','近似值');%适合copula
用t Copula模拟全球指数投资组合的回报
鉴于T copula的参数,现在通过首先模拟相应的依赖标准化残差来模拟共同相关的股权指数返回。
要做到这一点,首先使用copularnd函数可在统计和机器学习工具箱中找到。
然后,通过推断到GP尾部并插入平滑内部,通过每个指标的半参数边缘CDF的反转变换均匀变化对标准化残留物。这产生了与上面的Ar(1)+ GJR(1,1)过滤过程中获得的模拟标准化残留物。这些残差及时独立,但在任何时间点依赖。模拟标准化残差阵列的每列代表i.i.d.单独观察时,单次随机过程,而每行共享Copula诱导的等级相关性。
以下代码段模拟了在一个月内22个交易日内独立的标准化指数残差的2000个随机试验。
s = randstream.getGlobalStream();重置(s)ntrials = 2000;% #的独立随机试验地平线= 22;%var预测地平线z =零(地平线,ntrials,nindices);%标准化残差数组u = copularnd(“t”,r,dof,horizo n * ntrials);%t copula模拟为j = 1: nIndices Z (:,:, j) =重塑(icdf(反面{j}, U (:, j)),地平线,nTrials);结束
使用模拟的标准化残差作为i.i.d.输入噪声过程,通过OuthoMetrics Toolbox™重新引入在原始索引中观察到的自相关和异源性瘢痕度过滤器函数。
注意过滤器接受用户指定的标准化干扰从Copula派生,并一次模拟单个索引模型的多个路径,这意味着在连续中模拟并存储所有样本路径并为每个索引存储。
为了充分利用当前信息,指定必要的预先模型残差,差异和返回,以便每个模拟路径从常见的初始状态演变。
Y0 =回报(结束:);% presample回报Z0 =残差(结束:);%样品前标准化残差v0 = variances(结束,:);%预先规定差异simulatedReturns = 0 (horizon, nTrials, nIndices);为i = 1:nindices simulatedreturns(:,:,i)=过滤器(fit {i},z(:,:,i),......'y0',y0(i),'z0'Z0(我),“半”,v0(i));结束
现在重新塑造模拟返回阵列,使得每个页面代表多变量返回系列的单一试验,而不是单变量回报系列的多个试验。
simulatedreturns = erfute(simulatedreturns,[1 3 2]);
最后,考虑到每个指数的模拟回报,形成一个由单个指数组成的权重相等的全球指数组合(一个由国家指数组成的全球指数)。由于我们使用的是每天的对数回报,因此风险范围内的累积回报就是每个干预期间的回报之和。还要注意,投资组合的权重在整个风险范围内都是固定的,并且模拟忽略了重新平衡投资组合所需的任何交易成本(每日的再平衡过程假定是自融资的)。
请注意,尽管模拟收益是对数的(连续复合的),投资组合的收益序列是通过首先将单个对数收益转换为算术收益(价格变化除以初始价格),然后加权单个算术收益来获得投资组合的算术收益,最后转换回投资组合的对数回报。对于日数据和短期VaR范围,重复转换的差异很小,但对于较长的时间周期,差异可能是显著的。
cumulativereturns =零(ntrials,1);权重= repmat(1 / nindices,nindices,1);等加权投资组合为i = 1:ntrials cumulativereturns(i)= sum(log(exp(simulatedreturns(simulatedreturns(:,i)) - 1)*权重)));结束
总结结果
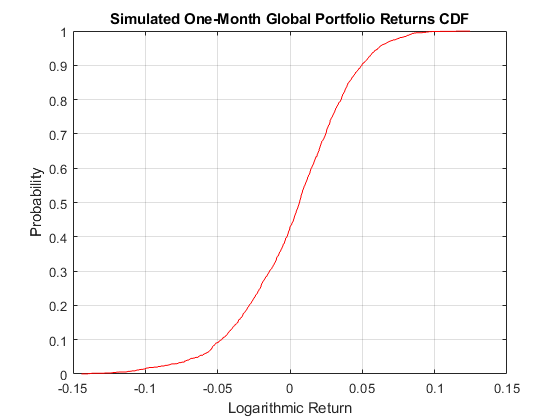
模拟每个指数的回报,形成全球投资组合,报告最大的收益和损失,以及不同信心水平的VaR,在一个月的风险水平。此外,绘制全球投资组合的实证CDF。
var = 100 * stantile(cumulativereturns,[0.0 0.05 0.01]');DISP('')流('最大模拟损失:%8.4f%s \ n', -100 *分钟(cumulativeReturns),'%')流(“最大模拟增益:%8.4f%s\n\n”,100 * max(cumulativereturns),'%')流('模拟90 %% var:%8.4f%s \ n'VaR (1),'%')流('模拟95 %% var:%8.4f%s \ n'VaR (2),'%')流('模拟99 %% var:%8.4f%s \ n',var(3),'%') figure h = cdfplot(累计返回);h.Color =“红色”;包含(“对数回归”)ylabel(“概率”) 标题 (“模拟一个月全球投资组合回报CDF”)
最大模拟损失:14.4162%最大模拟增益:12.4510%模拟90%var:-4.7456%模拟95%var:-6.3244%模拟99%var:-10.6542%
参考
[1]E. Bouye, V. Durrleman, A. Nikeghbali, G. Riboulet, and Roncalli, T。金融copula:阅读指南和一些应用Rech Groupe de。运作。,Credit Lyonnais,Paris,2000。
[2]Embrechts, P., A. McNeil和D. Straumann。风险管理中的相关性和依赖性:属性和陷阱。风险管理:风险和超越价值.剑桥:剑桥大学出版社,1999,第176-223页。
[3]Glosten,L. R.,R.Jagannathan和D. E. Runkle。“关于预期价值与标称超额股票的波动性关系。”财务杂志.卷。48,第5,1993,第5,199,PP。1779-1801。
[4]麦克尼尔,A.和R.Frey。“异源金融时间序列尾尾风险措施的估计:极值方法。”经验金融杂志.卷。7,2000,第271-300页。
[5]Nystrom,K.和J. Skoglund。“单变量极值理论,加汤和风险衡量标准。”预印文,提交了2002年。
[6]Nystrom,K.和J. Skoglund。“基于方案的风险管理框架。”预印文,提交了2002年。
[7]Roncalli,T.,A. Durrleman和A. Nikeghbali。“哪个copula是正确的?”Rech Groupe de。运作。,Credit Lyonnais,Paris,2000。
[8]Mashal,R.和A. Zeevi。“超越相关性:金融资产之间的极端共同运动。”哥伦比亚大学,纽约,2002年。
您还可以从以下列表中选择一个网站:
