深度学习处理器架构
该软件提供了一个通用的深度学习处理器IP核心,它是独立的,可以部署到您指定的任何自定义平台。处理器可以重复使用并共享以适应具有各种层尺寸和参数的深度神经网络。使用此处理器从Matlab快速原型原型神经网络®,然后将网络部署到FPGA。
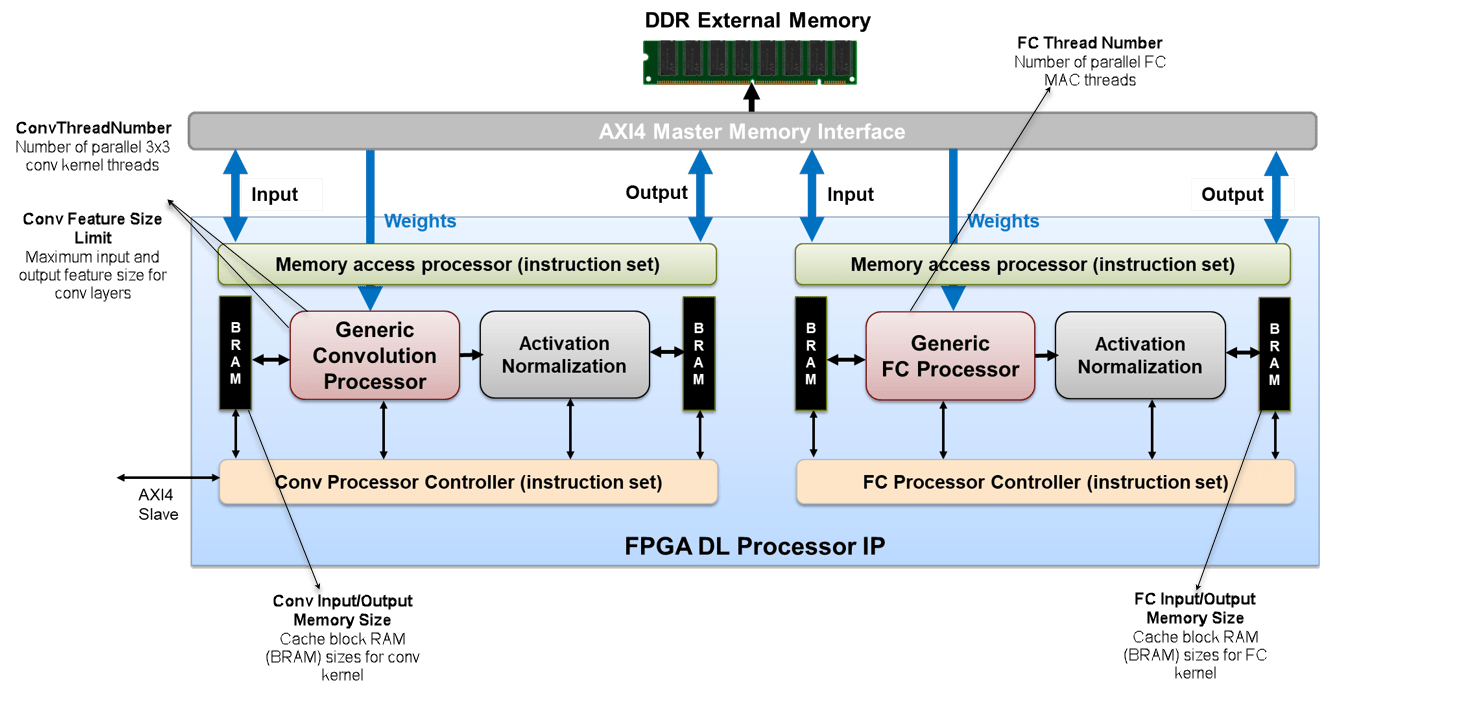
该图显示了深度学习处理器架构。
为了说明深度学习处理器架构,请考虑图像分类示例。
DDR外部内存
您可以将输入图像,权重和输出图像存储在外部DDR内存中。处理器包含与外部存储器通信的四个AXI4主界面。使用其中一个AXI4主接口,您可以将输入图像加载到块RAM上(糟糕)。块RAM提供了激活通用卷积处理器。
通用卷积处理器
这通用卷积处理器执行一个卷积层的等效操作。使用另一个AXI4主界面,提供卷积操作的权重通用卷积处理器。这通用卷积处理器然后对输入图像执行卷积操作,并为此提供激活激活归一化。处理器是通用的,因为它可以支持各种尺寸的张量和形状。金宝app
激活归一化
基于您提供的神经网络,激活归一化模块服务于添加Relu非线性,MaxPool层或执行本地响应标准化(LRN)。你看到处理器有两个激活归一化单位。一个单元跟随通用卷积处理器。另一个单位跟随通用FC处理器。
Conv控制器(调度)
取决于您在预磨料网络中拥有的卷积图层的数量,Conv控制器(调度)充当乒乓缓冲器。这通用卷积处理器和激活归一化可以一次处理一层。处理下一层,Conv控制器(调度)返回到BRAM,然后对网络中的所有卷积图层执行卷积和激活标准化操作。
通用FC处理器
这通用FC处理器执行一个完全连接层(FC)的等效操作。使用另一个AXI4主接口,提供完全连接层的权重通用FC处理器。这通用FC处理器然后在输入图像上执行完全连接的图层操作,并为此提供激活激活归一化模块。该处理器也是通用的,因为它可以支持各种尺寸的张量和形状。金宝app
FC控制器(调度)
这FC控制器(调度)与...类似的工作Conv控制器(调度)。这FC控制器(调度)与之坐标FIFO充当ping-pong缓冲区,用于执行完全连接的层操作和激活归一化根据您在神经网络中拥有的FC层的数量和Relu,MaxPool或LRN功能。之后通用FC处理器和激活归一化模块处理图像中的所有帧,通过AXI4主接口传输预测或分数并存储在外部DDR存储器中。
深度学习处理器应用程序
自定义深度学习处理器IP内核的一个应用是MATLAB控制的深度学习处理器。要创建此处理器,请使用AXI4从接口将深度学习处理器IP与HDL Verifier™MATLAB一起集成为AXI Master IP。通过JTAG或PCI Express界面,您可以从MATLAB导入各种预用的神经网络,执行网络中的网络指定的操作,在深度学习处理器IP中,并将分类结果返回到MATLAB。
有关更多信息,请参阅MATLAB控制深层学习处理器。
您还可以从以下列表中选择一个网站: