序列到序列LSTM网络的代码生成
这个例子演示了如何为长短期记忆(LSTM)网络生成CUDA®代码。该示例生成一个MEX应用程序,该应用程序在输入时间序列的每一步都进行预测。演示了两种方法:一种方法使用标准LSTM网络,另一种方法利用同一LSTM网络的有状态行为。这个例子使用了来自随身携带的智能手机的加速度传感器数据,并对佩戴者的活动进行预测。用户的动作分为五个类别之一,即跳舞、跑步、坐、站和走。该示例使用预先训练的LSTM网络。有关培训的更多信息,请参见利用深度学习进行序列分类示例来自深度学习工具箱™。
第三方的先决条件
要求
本例生成CUDA MEX,并具有以下第三方需求。
CUDA支持NVIDIA®GPU和兼容的驱动程序。
可选
对于非mex构建,如静态、动态库或可执行程序,此示例具有以下附加要求。
英伟达工具包。
NVIDIA cuDNN库。
编译器和库的环境变量。有关更多信息,请参见第三方硬件(GPU编码器)而且设置必备产品下载188bet金宝搏(GPU编码器).
验证GPU环境
使用coder.checkGpuInstall(GPU编码器)函数来验证运行此示例所需的编译器和库是否已正确设置。
envCfg = code . gpuenvconfig (“主机”);envCfg。DeepLibTarget =“cudnn”;envCfg。DeepCodegen = 1;envCfg。安静= 1;coder.checkGpuInstall (envCfg);
的lstmnet_predict入口点函数
序列到序列的LSTM网络使您能够对数据序列的每个时间步做出不同的预测。的lstmnet_predict.m入口点函数接受输入序列,并将其传递给经过训练的LSTM网络进行预测。具体来说,该函数使用的是训练好的LSTM网络利用深度学习对序列进行分类的例子。对象加载网络对象lstmnet_predict.mat文件保存到持久变量中,并在后续的预测调用中重用持久对象。
要显示网络体系结构的交互式可视化和有关网络层的信息,请使用analyzeNetwork函数。
类型(“lstmnet_predict.m”)
函数out = lstmnet_predict(in) %#codegen %版权所有if isempty(mynet) mynet = code . loaddeeplearningnetwork ('lstmnet.mat');End %传入输入输出= predict(mynet,in);
生成CUDA MEX
生成CUDA MEXlstmnet_predict.m入口点函数,创建一个GPU配置对象并指定目标为MEX。将目标语言设置为c++。创建一个深度学习配置对象,将目标库指定为cuDNN。将该深度学习配置对象附加到GPU配置对象上。
cfg = code .gpu config (墨西哥人的);cfg。TargetLang =“c++”;cfg。DeepLearningConfig =编码器。DeepLearningConfig (“cudnn”);
在编译时,GPU Coder™必须知道入口点函数的所有输入的数据类型。对象的输入参数的类型和大小codegen(MATLAB编码器)命令。coder.typeof(MATLAB编码器)函数。对于本例,输入是双数据类型,特征维值为3,序列长度可变。指定序列长度为可变大小,使我们能够对任意长度的输入序列执行预测。
matrixInput = code .typeof(double(0),[3 Inf],[false true]);
运行codegen命令。
codegen配置cfglstmnet_predictarg游戏{matrixInput}报告
代码生成成功:查看报告
在测试数据上运行生成的MEX
加载HumanActivityValidateMAT-file。这个mat文件存储变量XValidate其中包含传感器读数的时间序列样本,您可以在其上测试生成的代码。调用lstmnet_predict_mex在第一次观察中。
负载HumanActivityValidateYPred1 = lstmnet_predict_mex(XValidate{1});
YPred1是一个5 × 53888的数字矩阵,它包含五个类对于53888时间步长的概率。对于每个时间步,通过计算最大概率的指数来找到预测的类。
[~, maxIndex] = max(YPred1, [], 1);
将最大概率的指标与相应的标签关联起来。显示前十个标签。从结果中,你可以看到网络预测人类在前十个时间步骤中是坐着的。
标签=类别({“跳舞”,“奔跑”,“坐”,“站”,“走”});predictedLabels1 = labels(maxIndex);disp (predictedLabels1(1:10)”)
坐,坐,坐,坐,坐,坐,坐,坐,坐,坐
比较预测和测试数据
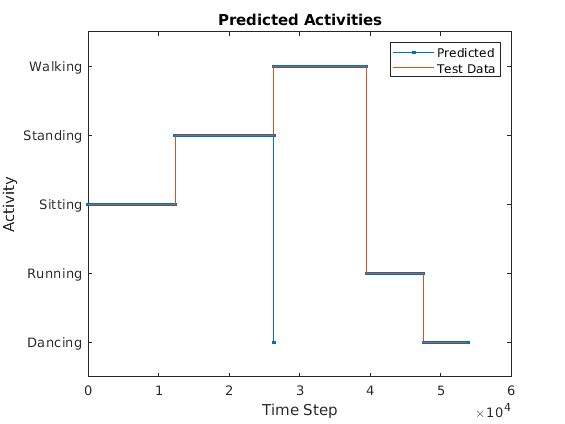
使用图表将MEX输出数据与测试数据进行比较。
图绘制(predictedLabels1,“。”);持有在情节(YValidate {1});持有从包含(“时间步”) ylabel (“活动”)标题(“预测活动”)传说([“预测”“测试数据”])
在不同序列长度的观察上调用生成MEX
调用lstmnet_predict_mex用不同的序列长度进行第二次观察。在这个例子中,XValidate {2}序列长度为64480,而XValidate {1}序列长度为53888。生成的代码正确地处理预测,因为我们将序列长度维度指定为可变大小。
YPred2 = lstmnet_predict_mex(XValidate{2});[~, maxIndex] = max(YPred2, [], 1);predictedLabels2 = labels(maxIndex);disp (predictedLabels2(1:10)”)
坐,坐,坐,坐,坐,坐,坐,坐,坐,坐
生成包含多个观察结果的MEX
如果希望一次对多个观察结果执行预测,可以将观察结果分组在一个单元格数组中,并传递该单元格数组进行预测。单元格数组必须是列单元格数组,并且每个单元格必须包含一个观察结果。每个观测必须具有相同的特征维度,但序列长度可能不同。在这个例子中,XValidate包含五个观察结果。生成一个MEX,可以取XValidate作为输入,将输入类型指定为5 × 1的单元格数组。此外,指定每个单元格的类型与matrixInput,即您为前面的单个观察指定的类型codegen命令。
matrixInput = code .typeof(double(0),[3 Inf],[false true]);cellInput = coder。typeof({matrixInput}, [5 1]);codegen配置cfglstmnet_predictarg游戏{cellInput}报告
代码生成成功:查看报告
YPred3 = lstmnet_predict_mex(XValidate);
输出是一个5乘1的单元格数组,对传入的5个观测结果进行预测。
disp (YPred3)
{5×53888 single} {5×64480 single} {5×53696 single} {5×56416 single} {5×50688 single}
使用有状态LSTM生成MEX
我们不需要在一个步骤中传递整个时间序列来进行预测,而是可以利用函数,通过每次输入一个时间步骤来运行预测predictAndUpdateState该函数接受一个输入,产生一个输出预测,并更新网络的内部状态,以便未来的预测考虑到这个初始输入。
入口点功能lstmnet_predict_and_update.m方法接受单时间步输入并处理该输入predictAndUpdateState函数。predictAndUpdateState输出对输入时间步长的预测并更新网络,以便后续输入被视为相同样本的后续时间步。每次传入一个时间步骤之后,结果输出与所有时间步骤作为单个输入传入时相同。
类型(“lstmnet_predict_and_update.m”)
函数out = lstmnet_predict_and_update(in) %#codegen %版权所有if isempty(mynet) mynet = code . loaddeeplearningnetwork ('lstmnet.mat');end % pass in input [mynet, out] = predictAndUpdateState(mynet,in);
在这个新设计文件上运行codegen。由于每次调用都采用单一的时间步,因此我们指定matrixInput用固定的序列尺寸1代替可变的序列长度。
matrixInput = code .typeof(double(0),[3 1]);codegen配置cfglstmnet_predict_and_updatearg游戏{matrixInput}报告
代码生成成功:查看报告
在第一个验证示例的第一个时间步上运行生成的MEX。
firstSample = XValidate{1};firstTimestep = firstSample(:,1);YPredStateful = lstmnet_predict_and_update_mex(firstTimestep);[~, maxIndex] = max(YPredStateful, [], 1);predictedLabelsStateful1 = labels(maxIndex)
predictedLabelsStateful1 =分类坐着
比较输出标签和基本事实值。
YValidate {1} (1)
ans =分类坐着
您也可以从以下列表中选择网站: