Multilabel图使用图注意网络的分类
这个例子展示了如何分类图,有多个独立的标签使用图关注网络(GATs)。
如果您的数据的观测图结构有多个独立的标签,您可以使用手枪[1]来预测未知标签为观察标签。图上使用图形结构和信息节点,得到使用戴面具的多线程self-attention机制总体特性在邻近的节点,计算每个节点的输出特性或嵌入的图。输出特征用于分类图通常使用后读出,或图形池、操作聚合或总结节点的输出特性。
这个例子展示了如何使用QM7-X数据集训练得到[2],图形代表6950个分子的集合。每个分子由23个原子,它被表示为节点。数据集包含5独特的原子:碳(C)、氢(H)、氮(N)、氧气(O)和硫(S)。三个原子作为节点的物理化学性质信息:标量Hirshfeld偶极矩,原子极化率,范德瓦耳斯半径。图标签官能团或特定团体的原子,分子的形成发挥了重要的作用。每个功能组代表子图,所以图可以有多个标签或没有标签,如果分子代表图没有官能团。这个例子中认为官能团CH、CH2甲基,N, NH,氨基,能剧,哦。
这个数字说明了multilabel图分类工作流在这个例子。

注:培训都是计算密集型任务。示例运行更快,这个例子中跳过步骤和加载pretrained网络培训。而不是训练网络,设置doTraining变量来真正的。
doTraining = false;
加载数据
下载并解压缩的文件夹包含处理版本QM7-X MathWorks网站的数据集。处理过的版本的数据集是一个4.85 MB垫文件组成的数据提取原始版本的下载<一个href="https://doi.org/10.5281/zenodo.3905360" target="_blank">QM7-X网站。
zipFile = matlab.internal.examples.download金宝appSupportFile (“nnet”,“数据/ QM7X.zip”);dataFolder = fileparts (zipFile);解压缩(zipFile dataFolder);
加载QM7-X数据。
负载(fullfile (dataFolder“QM7X”,“QM7X.mat”))
查看数据。
dataQM7X
dataQM7X =结构体字段:atNUM(23×6950双):atXYZ:[23×3×6950双]hDIP:[23×6950双]atPOL:[23×6950双]vdwR:(23×6950双)
与5个领域的数据结构。这个领域atNUM包含原子序数,atXYZ包含节点坐标,hDIP,atPOL,vdwR包含节点功能。共有6950个图的数据由23节点每图。对于有少于23节点的图,用0填充数据。
准备培训资料
提取和连接节点的特性。
特点=猫(3 dataQM7X.hDIP dataQM7X.atPOL dataQM7X.vdwR);特点=排列(特性,[1 3 2]);
视图的大小特征数据。
大小(特性)
ans =1×323 6950
提取原子序数和坐标数据,并使用它们来构建邻接矩阵数据使用coordinates2Adjacency功能,附加到这个例子作为支持文件。金宝app要访问这个文件,打开生活的脚本示例。
atomicNumber = dataQM7X.atNUM;坐标= dataQM7X.atXYZ;邻接= coordinates2Adjacency(坐标,atomicNumber);
邻接的大小数据视图。
大小(邻接)
ans =1×36950年23日23日
提取使用的标签uniqueFunctionalGroups功能,附加到这个例子作为支持文件。金宝app要访问这个文件,打开生活的脚本示例。
标签= uniqueFunctionalGroups(邻接,atomicNumber);
标签的大小数据视图。
大小(标签)
ans =1×26950年1
分区数据训练、验证和测试分区含80%,10%,和10%的数据。获得一个随机分裂,使用trainingPartitions功能,附加到这个例子作为支持文件。金宝app要访问这个文件,打开生活的脚本示例。
numGraphs =大小(邻接,3);[idxTrain, idxValidation idxTest] = trainingPartitions (numGraphs [0.8 0.1 0.1]);featuresTrain =特性(:,:,idxTrain);featuresValidation =特性(:,:,idxValidation);featuresTest =特性(:,:,idxTest);adjacencyTrain =邻接(:,:,idxTrain);adjacencyValidation =邻接(:,:,idxValidation);adjacencyTest =邻接(:,:,idxTest);labelsTrain =标签(idxTrain);labelsValidation =标签(idxValidation); labelsTest = labels(idxTest);
规范化的特点使用均值和方差的非零元素培训功能。
numFeatures =大小(featuresTrain, 2);muX = 0 (1、numFeatures);numFeatures sigsqX = 0 (1);为i = 1: numFeatures X = 0 (featuresTrain(:,我,:));muX (i) =意味着(X);sigsqX (i) = var (X, 1);结束
规范化培训功能,不含垫的零元素数据。
numGraphsTrain =大小(featuresTrain, 3);为j = 1: numGraphsTrain validIdx = 1: nnz (featuresTrain (:, 1, j));featuresTrain (validIdx: j) = (featuresTrain (validIdx: j) - muX)。/√(sigsqX);结束
正常使用相同的统计和验证特性也排除垫的零元素数据。
numGraphsValidation =大小(featuresValidation, 3);为j = 1: numGraphsValidation validIdx = 1: nnz (featuresValidation (:, 1, j));featuresValidation (validIdx: j) = (featuresValidation (validIdx: j) - muX)。/√(sigsqX);结束
标签数据的类名。
一会=独特(猫({}):1、标签)
一会=8×1的字符串“CH2”“CH CH3”“N”“NH”“氨基”“能剧”“哦”
培训标签编码成二进制数组的大小numObservations——- - - - - -numClasses,在那里numObservations是观察和的数量吗numClasses类的数量。在每一行中,非零项对应于每个观测的标签。
TTrain = 0 (numGraphsTrain元素个数(类名);为j = 1: numGraphsTrain如果~ isempty (labelsTrain {j}) [~, idx] = ismember (labelsTrain {j},类名);TTrain (j, idx) = 1;结束结束
查看培训目标数据的大小。
大小(TTrain)
ans =1×25560年8
可视化图形的数量每个类使用条形图。
classCounts = (TTrain, 1)之和;图酒吧(classCounts) ylabel (“数”)xticklabels(类名)

可视化标签的数量每图使用直方图。
labelCounts = (TTrain, 2)之和;图直方图(labelCounts)包含(“标签”)ylabel (“频率”)

图显示一个非常小的比例的图表没有标签。
编码验证标签为一个二进制数组。
TValidation = 0 (numGraphsValidation元素个数(类名);为j = 1: numGraphsValidation如果~ isempty (labelsValidation {j}) [~, idx] = ismember (labelsValidation {j},类名);TValidation (j, idx) = 1;结束结束
训练使用mini-batches数据,创建数组的数据存储功能,邻接,目标训练数据和组合它们。
featuresTrain = arrayDatastore (featuresTrain IterationDimension = 3);adjacencyTrain = arrayDatastore (adjacencyTrain IterationDimension = 3);targetTrain = arrayDatastore (TTrain);dsTrain =结合(featuresTrain adjacencyTrain targetTrain);
使用mini-batches做出预测的数据,创建一个数组数据存储验证特性和邻接数据并把它们。
featuresValidation = arrayDatastore (featuresValidation IterationDimension = 3);adjacencyValidation = arrayDatastore (adjacencyValidation IterationDimension = 3);dsValidation =结合(featuresValidation adjacencyValidation);
定义模型
定义模型。模型将特征矩阵作为输入X和邻接矩阵一个和输出分类预测。

该模型使用一个蒙面多线程自我注意力机制聚合特性在附近的一个节点,也就是说,一组节点直接相连的节点。面具,从邻接矩阵,获得用于预防注意节点之间并不在同一个小区。
后的模型使用ELU非线性前两个运营商的关注,随着激活函数。
帮助收敛,该模型使用一个跳过最后两个关注运营商之间的联系。
graph-level预测使用输出节点特性,模型使用平均总结节点功能。
最后,概率模型计算独立类使用一个s形的操作。
初始化模型参数
为每个操作定义的参数,包括它们的结构。
创建一个结构,包含正面关注操作的数量。
numHeads =结构;
为第一和第二指定3个正面关注操作。第三注意指定5个正面操作。
numHeads。一个ttn1 = 3; numHeads.attn2 = 3; numHeads.attn3 = 5;
创建一个结构,包含可学的参数模型。
参数=结构;
使用格式parameters.operationName.parameterName,在那里参数的结构,operationName是操作的名称(例如,“attn1”),然后呢parameterName参数的名称(例如,“权重”)。
初始化权重可学的使用initializeGlorot功能,附加到这个例子作为支持文件。金宝app访问功能,打开生活的脚本示例。
注意操作使用两种类型的权重。线性加权用于转换输入头线性特性在不同的关注。关注权重系数在每个头是用来计算关注。指定的两个权重结构字段linearWeights和attentionWeights。
初始化权值的第一个关注操作输出大小为96。输入大小通道的输入特性数据的数量。
numInputFeatures =大小(功能,2);numHiddenFeatureMaps = 96;numClasses =元素个数(类名);深圳= [numInputFeatures numHiddenFeatureMaps];numOut = numHiddenFeatureMaps;numIn = numInputFeatures;parameters.attn1.weights。linearWeights=initializeGlorot(sz,numOut,numIn); parameters.attn1.weights.attentionWeights = initializeGlorot([numOut 2],1,2*numOut);
初始化权值的第二个注意操作相同的输出大小与前面的乘法操作。输入大小输出的大小之前关注操作。
深圳= [numHiddenFeatureMaps numHiddenFeatureMaps];numOut = numHiddenFeatureMaps;numIn = numHiddenFeatureMaps;parameters.attn2.weights。linearWeights=initializeGlorot(sz,numOut,numIn); parameters.attn2.weights.attentionWeights = initializeGlorot([numOut 2],1,2*numOut);
第三注意初始化权重操作有一个输出大小匹配的类的数量。输入大小输出的大小之前关注操作。
numOutputFeatureMaps = numHeads.attn3 * numClasses;深圳= [numHiddenFeatureMaps numOutputFeatureMaps];numOut = numClasses;numIn = numHiddenFeatureMaps;parameters.attn3.weights。linearWeights=initializeGlorot(sz,numOut,numIn); parameters.attn3.weights.attentionWeights = initializeGlorot([numOutputFeatureMaps 2],1,2*numOut);
查看参数结构。
参数
参数=结构体字段:attn1:(1×1结构)attn2: [1×1 struct] attn3: [1×1 struct]
查看第一个注意操作的参数。
parameters.attn1.weights
ans =结构体字段:linearWeights: [3×96 dlarray] attentionWeights: [96×2 dlarray]
定义模型函数
创建函数模型中定义的,<一个href="//www.tatmou.com/help/deeplearning/ug/multilabel-graph-classification-using-graph-attention-networks.html" class="intrnllnk">模型函数部分的例子,使用模型作为输入参数,输入特性和邻接矩阵,每图和节点的数量,并返回标签的预测。
定义模型损失函数
创建函数modelLoss中定义的,<一个href="//www.tatmou.com/help/deeplearning/ug/multilabel-graph-classification-using-graph-attention-networks.html" class="intrnllnk">损失函数模型部分的例子,使用模型作为输入参数,mini-batch输入特性和对应的邻接矩阵,每个图的节点数量,和相应的编码目标的标签,并返回损失,损失的梯度对可学的参数,和模型预测。
指定培训选项
70年火车时代mini-batch大小为300。大型mini-batches GATs有关的训练数据可以导致内存不足的错误。如果你的硬件没有足够的内存,那么减少mini-batch大小。
numEpochs = 70;miniBatchSize = 300;
培训使用的学习速率0.01。
learnRate = 0.01;
预测概率转换成二进制编码的标签,指定一个标签阈值为0.5。当网络做出预测,网络输出1的概率大于或等于阈值。
labelThreshold = 0.5;
每210次迭代模型进行了验证。
validationFrequency = 210;
火车模型
火车模型使用自定义训练循环。
使用minibatchqueue处理和管理mini-batches训练数据。为每个迭代和mini-batch:
丢弃部分mini-batches。
使用自定义mini-batch预处理功能
preprocessMiniBatch中定义的,<一个href="//www.tatmou.com/help/deeplearning/ug/multilabel-graph-classification-using-graph-attention-networks.html" class="intrnllnk">预处理Mini-Batch函数节的例子删除零填充数据,每图计算的节点数量,合并成一个单一的多个图形实例图实例。的preprocessMiniBatch函数返回4变量作为输出。因此,设置输出的数量minibatchqueue对象为4。默认情况下,minibatchqueue对象集的输出变量的输入数据存储的数量,这是3。输出的数据类型的数据
双。邻接的数据作为一个稀疏矩阵,返回和稀疏的不支持金宝app单。默认情况下,minibatchqueue对象的数据类型单。数据转换的功能
dlarray对象。默认情况下,minibatchqueue将所有输出数据转换为对象dlarray对象。火车在GPU如果可以通过指定第一个输出的输出环境
“汽车”剩下的输出“cpu”。默认情况下,minibatchqueue将每个输出转换为对象gpuArray如果一个GPU是可用的。使用GPU需要并行计算工具箱™和支持GPU设备。金宝app支持设备的信息,请参阅金宝app<一个href="//www.tatmou.com/help/parallel-computing/gpu-computing-requirements.html" data-docid="distcomp_ug#mw_57e04559-0b60-42d5-ad55-e77ec5f5865f" class="a">GPU计算的需求(并行计算工具箱)。
兆贝可= minibatchqueue (dsTrain 4…MiniBatchSize = MiniBatchSize,…PartialMiniBatch =“丢弃”,…MiniBatchFcn = @preprocessMiniBatch,…OutputCast =“替身”,…OutputAsDlarray = [1 0 0 0],…OutputEnvironment = [“汽车”“cpu”“cpu”“cpu”]);
的modelPredictions函数,定义的<一个href="//www.tatmou.com/help/deeplearning/ug/multilabel-graph-classification-using-graph-attention-networks.html" class="intrnllnk">模型的预测部分的例子,可以用来获得验证网络模型预测。由迭代函数使得预测mini-batches使用读取的数据的大小属性数据存储对象。设置读取大小属性数组的数据存储验证数据miniBatchSize。您可以使用任何的价值在你的硬件内存津贴。
dsValidation.UnderlyingDatastores {1}。ReadSize = miniBatchSize;dsValidation.UnderlyingDatastores {2}。ReadSize = miniBatchSize;
初始化参数为亚当的优化器。
trailingAvg = [];trailingAvgSq = [];
火车模型。
对于每一个时代,洗牌mini-batches数据和循环。
为每个mini-batch:
评估损失和梯度模型使用
dlfeval和modelLoss函数。更新网络参数使用
adamupdate函数。更新培训的阴谋。
如果有必要,验证网络使用
modelPredictions函数。的modelPredictions函数作为输入数据存储对象dsValidation和模型参数并返回模型预测。损失计算验证和更新培训的阴谋。
注:培训都是计算密集型任务。示例运行更快,这个例子中跳过步骤和加载pretrained网络培训。而不是训练网络,设置doTraining变量来真正的。
如果doTraining%初始化培训进展阴谋。图C = colororder;lineLossTrain = animatedline(颜色= C (2:));lineLossValidation = animatedline (…线型=”——“,…标志=“o”,…MarkerFaceColor =“黑色”);ylim([0正])包含(“迭代”)ylabel (“损失”网格)在迭代= 0;开始=抽搐;%循环时期。为时代= 1:numEpochs%洗牌数据。洗牌(兆贝可);而hasdata(兆贝可)迭代=迭代+ 1;% mini-batches读取的数据。[XTrain,火车,numNodes TTrain] =下一个(兆贝可);%计算模型和梯度使用dlfeval损失% modelLoss函数。(损失、渐变Y) = dlfeval (@modelLoss、参数、XTrain火车、numNodes TTrain, numHeads);%更新使用亚当优化网络参数。(参数、trailingAvg trailingAvgSq) = adamupdate(参数、渐变…trailingAvg trailingAvgSq,迭代,learnRate);%显示培训进展。D =持续时间(0,0,toc(开始),格式=“hh: mm: ss”);标题(”时代:“+时代+”,过去:“+字符串(D)) =双重损失(损失);addpoints drawnow (lineLossTrain,迭代,损失)%显示验证指标。如果迭代1 = = | |国防部(迭代,validationFrequency) = = 0 YValidation = modelPredictions(参数、dsValidation numHeads);lossValidation = crossentropy (YValidation TValidation TargetCategories =“独立”DataFormat =“公元前”);lossValidation =双(lossValidation);drawnow addpoints (lineLossValidation迭代,lossValidation)结束结束结束其他的%加载pretrained参数。负载(“parametersQM7X_GAT.mat”)结束

测试模型
标准化测试功能使用培训的统计特性。
numGraphsTest =大小(featuresTest, 3);为j = 1: numGraphsTest validIdx = 1: nnz (featuresTest (:, 1, j));featuresTest (validIdx: j) = (featuresTest (validIdx: j) - muX)。/√(sigsqX);结束
为测试创建数组数据存储特性和相邻数据,设置他们的ReadSize属性miniBatchSize,结合他们。
featuresTest = arrayDatastore (featuresTest IterationDimension = 3, ReadSize = miniBatchSize);adjacencyTest = arrayDatastore (adjacencyTest IterationDimension = 3, ReadSize = miniBatchSize);dst =结合(featuresTest adjacencyTest);
编码测试标签为一个二进制数组。
tt = 0 (numGraphsTest元素个数(类名);为j = 1: numGraphsTest如果~ isempty (labelsTest {j}) [~, idx] = ismember (labelsTest {j},类名);tt (j, idx) = 1;结束结束
使用modelPredictions功能测试数据进行预测。
预测= modelPredictions(参数、dst numHeads);
预测概率转换成二进制编码的标签使用一个标签阈值为0.5,这是一样的标签阈值labelThreshold时,使用培训和验证模型。
预测=双(收集(extractdata(预测)));欧美=双(预测> = 0.5);
通过计算f值使用评估性能fScore函数,定义的<一个href="//www.tatmou.com/help/deeplearning/ug/multilabel-graph-classification-using-graph-attention-networks.html" class="intrnllnk">f值函数部分的例子。
的fScore函数使用一个权重参数β更重视精度或召回。精确的比例是正确的积极的结果积极的结果,包括那些被错误地预测为正,回忆是真正积极的结果比实际积极的样本。
使用三个权重参数计算f值:
0.5 -精度两次召回一样重要。
1 -精度和召回也同样重要。使用这个值来监控模型在训练和验证的性能。
2 -召回是重要的两倍精度。
scoreWeight = [0.5 - 1 2];为i = 1:3 scoreTest (i) = fScore(欧美、tt、scoreWeight(我));结束
查看表中的分数。
scoreTestTbl =表;scoreTestTbl。β= scoreWeight ';scoreTestTbl。FScore = scoreTest'
scoreTestTbl =3×2表βFScore ___ _____ 0.9458 0.5 0.9475 0.9492 - 1 2
想象的混乱为每个类图表。
图tiledlayout (“流”)为i = 1: numClasses nexttile confusionchart(欧美(:,我),tt(:,我));标题(类名(我))结束

接受者操作特征曲线(ROC)可视化为每个类。
ROC曲线阴谋的真正积极的自杀率和假阳性,说明模型在所有标签的性能阈值。真阳性率的比率是正确的积极的结果对所有实际积极的样本,包括那些错误地预测模型为负。假阳性率是假阳性的比率对所有实际负样本,包括那些被错误地预测为正数。曲线下的面积(AUC)提供一个聚合的性能在所有可能的标签阈值。
为每一个类:
计算真阳性和假阳性的比例使用
中华民国函数。计算AUC使用
trapz函数。ROC曲线和显示AUC的阴谋。也绘制ROC曲线的一个随机,或任何技巧,预测模型,随机预测,或总是相同的结果。
图tiledlayout (“流”)为i = 1: numClasses currentTargets = tt(:,我)”;currentPredictions =预测(:,i) ';[truePositiveRates, falsePositiveRates] =中华民国(currentTargets currentPredictions);AUC = trapz (falsePositiveRates truePositiveRates);nexttile情节(falsePositiveRates truePositiveRates,…falsePositiveRates falsePositiveRates,”——“,线宽= 0.7)文本(0.075,0.75," \ bf AUC = "+ num2str (AUC),字形大小= 6.75)包含(“玻璃钢”)ylabel (“TPR”(我)标题(类名)结束乐金显示器=传奇(“ROC曲线——手枪”,“ROC曲线——随机”);lgd.Layout。Tile = numClasses+1;

预测使用新数据
加载预处理QM7X示例数据。
负载(fullfile (dataFolder“QM7X”,“preprocessedQM7XSample.mat”))
邻接矩阵和节点特性的示例数据。
adjacencyMatrixSample = dataSample.AdjacencyMatrix;featuresSample = dataSample.Features;
查看图中节点的数量。
numNodesSample =大小(adjacencyMatrixSample, 1)
numNodesSample = 10
提取图像数据。计算关注分数,删除添加self-connections邻接矩阵,然后利用矩阵构造图。
= adjacencyMatrixSample -眼(numNodesSample);图G =(一个);
地图符号使用的原子序数atomicSymbol功能,附加到这个例子作为支持文件。金宝app要访问这个函数,打开生活的脚本示例。
atomicNumbersSample = dataSample.AtomicNumbers;[符号,symbolsCount] = atomicSymbol (atomicNumbersSample);
在阴谋中显示图形,使用映射的符号作为节点标签。
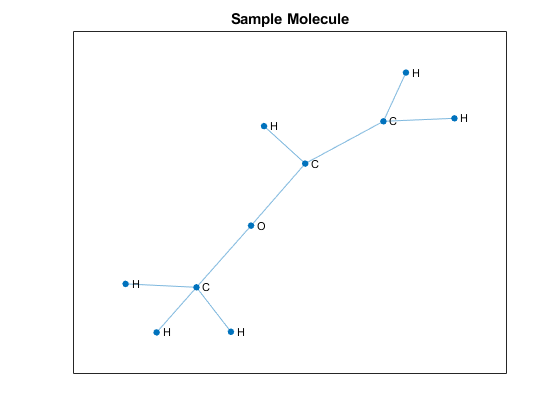
图绘制(G, NodeLabel =符号,线宽= 0.75,=布局“力”)标题(“样品分子”)
转换的功能dlarray对象。
XSample = dlarray (featuresSample);
如果一个GPU可用,将输入数据转换成gpuArray。
如果canUseGPU XSample = gpuArray (XSample);结束
预测使用模型函数。也获得成绩的关注关注运营商的计算模型。
[YSample, attentionScores] =模型(参数、XSample adjacencyMatrixSample、numNodesSample numHeads);
预测概率转换成二进制编码的标签。
YSample =收集(extractdata (YSample));YSample = YSample > = 0.5;
预测二元标签转换为实际的标签。
(YSample predictionsSample =类名)
predictionsSample =3×1的字符串“CH2”“CH CH3”
可视化的关注分数。
创建一个热图的注意人均得分在最后注意操作模型的使用的热图。
attention3Scores =双(收集(extractdata (attentionScores.attn3)));numHeadsAttention3 = numHeads.attn3;图tiledlayout (“流”)为i = 1: numHeadsAttention3 nexttile热图(symbolsCount、symbolsCount attention3Scores(:,:我),ColorScaling =“scaledrows”、标题=“头”+ num2str (i))结束

注意力地图中的x和y值对应的节点标签下面的情节。
图绘制(G, NodeLabel = symbolsCount,线宽= 0.75,=布局“力”)

彩色地图表示的相对强度水平的关注节点在一个特定的行索引给节点在一个特定的列索引。例如,头1,第一个碳原子C1了几乎同等程度的重视前三个氢原子H1, H2, H3,让很少或根本没有注意本身的氧原子O1,它也是连接,或者其他原子因为两者没有任何联系。
模型函数
的模型函数作为模型输入参数参数,特征矩阵X的邻接矩阵一个,每个图的节点数量numNodes和正面的次数numHeads,并返回预测和关注分数。
功能:
计算图关注每一层使用
注意函数中定义<一个href="//www.tatmou.com/help/deeplearning/ug/multilabel-graph-classification-using-graph-attention-networks.html" class="intrnllnk">注意函数部分的例子。使用ELU非线性,使用
elu函数中定义<一个href="//www.tatmou.com/help/deeplearning/ug/multilabel-graph-classification-using-graph-attention-networks.html" class="intrnllnk">ELU函数部分的例子是第一个两层的激活函数。雇佣了一个隐藏层中的残余连接来援助收敛。
使用
globalAveragePool函数,定义的<一个href="//www.tatmou.com/help/deeplearning/ug/multilabel-graph-classification-using-graph-attention-networks.html" class="intrnllnk">全球平均池功能部分的例子,最后一层后执行读出操作。使用
乙状结肠作为独立的类函数来计算标签预测概率。
函数[Y, attentionScores] =模型(参数X, A numNodes numHeads)权重= parameters.attn1.weights;numHeadsAttention1 = numHeads.attn1;Z1 = X;(Z2, attentionScores。一个ttn1] = attention(Z1,A,weights,numHeadsAttention1,“猫”);Z2 = elu (Z2);重量= parameters.attn2.weights;numHeadsAttention2 = numHeads.attn2;[Z3, attentionScores。一个ttn2] = attention(Z2,A,weights,numHeadsAttention2,“猫”);Z3 = elu (Z3) + Z2;重量= parameters.attn3.weights;numHeadsAttention3 = numHeads.attn3;(Z4, attentionScores。一个ttn3] = attention(Z3,A,weights,numHeadsAttention3,“的意思是”);Z4 = globalAveragePool (Z4, numNodes);Y =乙状结肠(Z4);结束
损失函数模型
的modelLoss函数作为模型输入参数参数,特征矩阵X的邻接矩阵adjacencyTrain,每个图的节点数量numNodes二进制编码的标签T和正面的次数numHeads的梯度,并返回损失对模型参数,相应的损失,和模型预测。
函数(损失、渐变Y) = modelLoss(参数X, adjacencyTrain numNodes, T, numHeads) Y =模型(参数X, adjacencyTrain numNodes, numHeads);损失= crossentropy (Y, T, TargetCategories =“独立”DataFormat =“公元前”);梯度= dlgradient(损失、参数);结束
预处理Mini-Batch函数
的preprocessMiniBatch函数作为输入特性数据featureData,邻接的数据adjacencyData,t和目标数据argetData,合并mini-batches不同图实例为一个图的实例。
请注意,目标数据是一个可选的输入参数的函数。
对于每个图,功能:
计算节点的数量和连接数据。
删除零填充的
adjacencyData输入和连接数据通过建立稀疏block-diagonal矩阵,节点在不同的图实例不互动,也就是说,他们不认为是邻居。矩阵中的每个块对应于一个图的邻接矩阵实例。删除零填充的
featureData输入和连接数据。
函数(特性、邻接numNodes、目标)= preprocessMiniBatch (featureData、adjacencyData targetData)%提取特征和邻接单元阵列和数据连接%数据沿着第三维度(批处理)featureData =猫(3,featureData {:});adjacencyData =猫(3,adjacencyData {:});%提取目标数据如果它存在如果输入参数个数> 2目标=猫(targetData {:});结束邻接=稀疏([]);特点= [];numNodes = [];为i = 1:尺寸(adjacencyData, 3)%在当前图的节点数量numNodesInGraph = nnz (featureData(:, 1,我));numNodes = [numNodes;numNodesInGraph];%得到实际的非零数据的指标validIdx = 1: numNodesInGraph;%从adjacencyData删除零填充tmpAdjacency = adjacencyData (validIdx validIdx,我);%添加自己的连接tmpAdjacency = tmpAdjacency +眼(大小(tmpAdjacency));%建立邻接矩阵块对角矩阵邻接= blkdiag(邻接,tmpAdjacency);%从featureData删除零填充tmpFeatures = featureData (validIdx:,我);特点=[功能;tmpFeatures];结束结束
f值函数
的fScore函数计算micro-average f值,衡量模型准确性的数据使用的精度和召回。
可以定义为micro-average精度
,
在哪里Y二进制编码的预测,T二进制编码的目标,N是观测的数量,和C类的数量。
可以定义为micro-average回忆
,
和micro-average f值被定义为:
,
在哪里 是一个加权参数,用于放置精密或召回更大的价值。
函数分数= fScore(预测,目标,β)truePositive =总和(预测。*目标,“所有”);falsePositive =总和(预测。* (1-targets),“所有”);%的精度精度= truePositive / (truePositive + falsePositive);%回忆回忆= truePositive /笔(目标,“所有”);% FScore如果输入参数个数= = 2β= 1;结束得分=(1 +β^ 2)*精度*回忆/(β^ 2 *精度+回忆);结束
模型的预测函数
的modelPredictions函数作为模型输入参数参数,数据存储对象ds控股的特性和相邻数据和正面的数量numHeads,并返回遍历mini-batches模型预测的数据和每个mini-batch使用预处理preprocessMiniBatch函数。
函数Y = modelPredictions(参数、ds numHeads) Y = [];重置(ds)而hasdata (ds)数据=阅读(ds);featureData =数据(:1);adjacencyData =数据(:,2);[特性、邻接numNodes] = preprocessMiniBatch (featureData adjacencyData);X = dlarray(特性);minibatchPred =模型(参数X,邻接,numNodes numHeads);Y = [Y; minibatchPred];结束结束
注意函数
的注意使用蒙面多线程self-attention函数计算节点的功能。
给定的输入节点的功能 的维度 ,在那里 节点和数量吗 是输入的数量特征,层 ,注意函数计算节点的输出特性 的维度 ,在那里 的是输出的数量特征层,如下:
使用 独立,它计算线性变换 ,因为 使用权重矩阵,输入的特性 的维度 。也就是说, 。
它使用一个注意力机制计算系数标量的关注 所有节点对 ,在那里 是一个向量的维度 对应于n矩阵的行 。注意系数 代表节点的重要性 到节点 在头 。注意机制 可以是一个点积运算的功能 和 或神经网络。这个例子遵循[1]中的方法,在特征 和 连接和注意力机制是一个单层神经网络权重数组 组成的 元素,所有节点共享,其次是leaky-ReLU非线性。
防止注意力没有直接相连的节点之间,都实现了蒙面注意通过使用图结构,定义的邻接矩阵,计算一个面具,掩盖了关注系数 对所有 ,在那里 节点的邻居吗 ,包括 , 对所有 。
关注分数计算正常化使用系数的注意蒙面softmax操作。也就是说,注重分数 。
注意分数然后用于获得输出层的特性的线性组合转换 。也就是说,给定一个 矩阵的关注分数 计算在头 、输出特性 从关注头 得到了, 。
每个关注的特性输出头聚合,通过连接,也就是说, ,或平均 ,输出层的特性。
的注意函数作为输入特性矩阵inputFeatures,邻接矩阵邻接可学的参数权重的头numHeads,多注意头和聚合方法聚合,计算并返回功能使用蒙面多线程自我关注。
函数将可学的参数分为多个正面,和为每一个关注的头,它:
计算一个线性变换的输入特性。
注意计算系数使用线性转换特性。
面具注意系数。
规范化蒙面注意系数。
规范化使用规范化的蒙面注意系数线性转换功能。
最后,它聚合了不同的输出特性的关注。
函数[outputFeatures, normAttentionCoeff] =注意(inputFeatures邻接,重量、numHeads、聚合)%分割权重对正面的次数和重塑矩阵三维数组szFeatureMaps =大小(weights.linearWeights);numOutputFeatureMapsPerHead = szFeatureMaps (2) / numHeads;linearWeights =重塑(weights.linearWeights [szFeatureMaps (1) numOutputFeatureMapsPerHead, numHeads]);attentionWeights =重塑(权重。attentionWeights,(numOutputFeatureMapsPerHead, 2, numHeads]);%计算线性变换的输入特性值= pagemtimes (inputFeatures linearWeights);%计算关注系数查询= pagemtimes(价值,attentionWeights (: 1:));关键= pagemtimes(价值,attentionWeights (:, 2:));attentionCoefficients =查询+交换(钥匙,(2,1,3));attentionCoefficients = leakyrelu (attentionCoefficients, 0.2);%计算系数蒙面的关注掩码= -10 e9 *(1 -邻接);attentionCoefficients = attentionCoefficients +面具;%计算归一化系数蒙面的关注normAttentionCoeff = softmax (attentionCoefficients DataFormat =“拍”);使用规范化的蒙面注意系数%功能正常化headOutputFeatures = pagemtimes (normAttentionCoeff值);%的总特点从多个正面如果比较字符串(聚合,“猫”)outputFeatures = headOutputFeatures (:,);其他的outputFeatures =意味着(headOutputFeatures, 3);结束结束
ELU函数
的elu函数实现了ELU激活函数定义为
这个函数使用
函数y = elu (x) y = max (0, x) + (exp (min (0, x)) 1);结束
全球平均池功能
的globalAveragePool函数作为输入特性表示inFeatures每图和节点的数量numNodes,并返回一个输出特性表现为每个图的平均输入特性对每个图的节点数。
对于一个图 与 节点,该函数计算图的输出特性 ,在那里 是一个 向量,对应nth的行 图的子矩阵的输入特性 是输入的数量特征。
函数outFeatures = globalAveragePool (inFeatures numNodes) numGraphs =元素个数(numNodes);numFeatures =大小(inFeatures, 2);outFeatures = 0 (numGraphs numFeatures,“喜欢”,inFeatures);startIdx = 1;为i = 1: numGraphs endIdx = startIdx + numNodes (i) - 1;idx = startIdx: endIdx;outFeatures(我)=意味着(inFeatures (idx:));startIdx = endIdx + 1;结束结束
引用
佩,VeličkovićGuillem Cucurull单打项目卡萨诺瓦,阿德里亚娜罗梅罗,Pietro利奥,Yoshua Bengio。“图网络关注。”Preprint, submitted February 4, 2018. https://arxiv.org/abs/1710.10903.
Hoja,约翰内斯·达·芬奇Medrano Sandonas,布莱恩·恩斯特阿尔瓦罗·Vazquez-Mayagoitia Robert a . DiStasio和亚历山大Tkatchenko。“QM7-X:量子力学的综合数据集属性生成有机小分子的化学空间。“Zenodo, 11月23日,2020年。<一个href="https://doi.org/10.5281/ZENODO.3905360" target="_blank">https://doi.org/10.5281/ZENODO.3905360。
另请参阅
dlarray|dlfeval|dlgradient|minibatchqueue