GPU执行生成的代码的分析
这个例子向您展示了如何为生成的CUDA®代码生成一个执行分析报告gpucoder.profile函数。以雾整流为例说明了这一概念。
先决条件
CUDA支持NVIDIA®GPU。
nvidia cuda工具包和司机。
编译器和库的环境变量。有关编译器和库支持的版本的信息,请参见金宝app第三方硬件.有关设置环境变量,请参见设置前提产品下载188bet金宝搏.
本例的概要分析工作流依赖于
nvprof.从NVIDIA的工具。在CUDA工具箱v10.1中,NVIDIA限制只有管理员用户才能访问性能计数器。若要让所有用户都能使用GPU性能指标,请参见具体操作步骤https://developer.nvidia.com/nvidia-development-tools-金宝搏官方网站solutions-err_nvgpuctrperm-permission-issue-performance-counters..
验证GPU环境
要验证运行此示例所需的编译器和库是否正确设置,请使用Coder.CheckGPuInstall.函数。
envCfg = coder.gpuEnvConfig ('主持人');envCfg。BasicCodegen = 1;envCfg。安静= 1;coder.checkGpuInstall (envCfg);
准备代码生成和分析
的fog_rectification.m函数以模糊图像作为输入,并返回去雾图像。要生成CUDA代码,创建一个带有动态库的GPU代码配置对象(“dll”)构建类型。因为这gpucoder.profile函数仅接受嵌入式编码器配置对象,a编码器。EmbeddedCodeConfig配置对象,即使是选项没有明确地被选择。
inputImage = imread ('foggyinput.png');输入= {inputImage};designFileName =“fog_rectification”;cfg = coder.gpuConfig (“dll”);cfg.GpuConfig.MallocMode =“离散”;
生成执行分析报告
运行gpucoder.profile阈值为0.003以查看SIL执行报告。0.003的阈值只是代表性的数字。如果生成的代码有很多CUDA API或内核呼叫,则每个呼叫可能只构成总时间的一小部分。建议设置低阈值(0.001-0.005)以生成有意义的分析报告。不建议将执行值设置为非常低的数字(小于5),因为它不会产生典型执行配置文件的准确表示。
gpucoder.profile(designFileName, inputs,“CodegenConfig”cfg,“阈值”,0.003,“我会”,10);
clear fog_rectification_sil执行分析数据可供查看。打开< a href = " matlab金宝app: Simulink.sdi.view;“>模拟数据检查员。终止后可用的执行分析报告。###停止SIL执行' fog_整流'
的代码执行分析报告fog_rection.功能
代码执行分析报告提供了基于从SIL或PIL执行收集的数据的指标。执行时间由由仪器探测器记录的数据计算,添加到SIL或PIL测试线束或为每个组件生成的代码内部。有关更多信息,请参阅视图执行时间(嵌入式编码).这些数字具有代表性。实际值取决于硬件设置。该分析使用MATLAB R2020a在一台具有6核3.5GHz Intel®Xeon®CPU和NVIDIA TITAN XP GPU的机器上完成
1.总结

2.代码的剖面部分

3.用于FOG_RECTIONIGE的GPU分析跟踪
第3节显示了与阈值高的运行时的GPU调用的完整跟踪。的“阈值”参数被定义为运行的最大执行时间的分数(不包括第一次运行)。例如,9个呼叫到顶级fog_rection.功能,如果第三个呼叫占据了最大时间( ,多发性硬化症),则最大执行时间为毫秒。所有GPU都呼叫超过
,多发性硬化症),则最大执行时间为毫秒。所有GPU都呼叫超过 本节中显示了毫秒。将光标放在呼叫上显示每个呼叫的其他相关非计时相关信息的运行时值。例如,将光标放在上面
本节中显示了毫秒。将光标放在呼叫上显示每个呼叫的其他相关非计时相关信息的运行时值。例如,将光标放在上面fog_rection_kernel10.显示了该调用的块维度、网格维度和KiB中的静态共享内存大小。该跟踪对应于花费最大时间的运行。

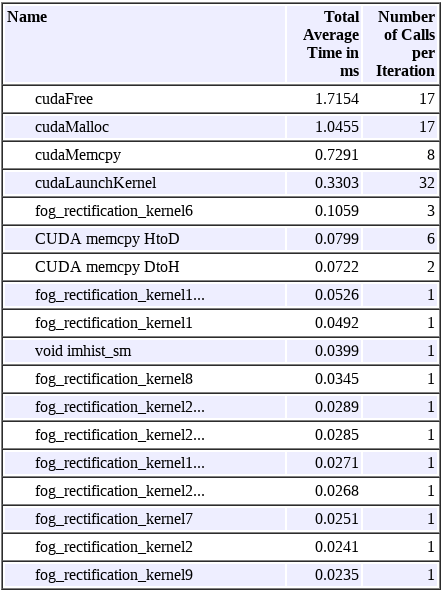
4.用于fog_整流的GPU分析概要
报告中的第4节显示了第3节中显示的GPU呼叫摘要cudaFree每次运行称为17次fog_rection.17个电话的平均时间cudaFree超过9次fog_rection.是1.7154毫秒。这个总结是按时间降序排列的,让用户知道哪个GPU调用占用了最大的时间。
您还可以从以下列表中选择一个网站:
