使用CUDA FFT库模拟衍射模式
这个例子展示了如何使用GPU Coder™利用CUDA®快速傅里叶变换库(cuFFT)在NVIDIA®GPU上计算二维FFT。二维傅里叶变换在光学中用于计算远场衍射模式。当单色光源通过一个小孔径时,比如在杨的双缝实验中,你可以观察到这些衍射图案。这个例子还展示了在生成CUDA MEX、源代码、静态库、动态库和可执行文件时,如何使用GPU指针作为入口点函数的输入。通过使用这个功能,生成代码中的cudaMemcpy调用数量最小化,从而提高了生成代码的性能。
第三方的先决条件
要求
本例生成CUDA MEX,第三方需求如下。
CUDA启用NVIDIA GPU和兼容驱动程序。
可选
对于非mex构建,例如静态、动态库或可执行文件,此示例具有以下附加要求。
英伟达工具包。
编译器和库的环境变量。有关更多信息,请参见第三方硬件而且设置必备产品下载188bet金宝搏.
检查GPU环境
要验证运行此示例所需的编译器和库是否已正确设置,请使用coder.checkGpuInstall函数。
envCfg = code . gpuenvconfig (“主机”);envCfg。BasicCodegen = 1;envCfg。安静= 1;coder.checkGpuInstall (envCfg);
定义坐标系
在模拟通过光圈的光之前,必须定义您的坐标系统。以便在调用时获得正确的数值行为fft2,你必须仔细安排 而且
而且 这样零值就在正确的位置。
这样零值就在正确的位置。N2是每个维度大小的一半。
N2 = 1024;[gx, gy] = meshgrid(-1:1/N2:(N2-1)/N2);
模拟矩形孔径的衍射模式
模拟一束平行的单色光通过一个小的矩形孔径的效果。二维傅里叶变换描述了距离孔径较大的光场。形式孔径作为基于坐标系统的逻辑掩码。光源是一个双精度版本的光圈。函数求远场光信号fft2函数。
孔径= (abs(gx) < 4/N2) .* (abs(gy) < 2/N2);光源=双(光圈);Farfieldsignal = fft2(光源);
显示矩形光圈的光强
的visualize.m函数显示矩形光圈的光强。根据光场大小的平方计算远场光强。为了帮助可视化,可以使用fftshift函数。
类型可视化
函数可视化(farfieldsignal, titleStr) farfieldintensity = real(farfieldsignal .* conj(farfieldsignal));Imagesc (fftshift(farfieldinsity));轴('equal');轴('off');标题(titleStr);结束
STR = sprintf(矩形孔径远场衍射图的MATLAB实现);可视化(farfieldsignal str);

为函数生成CUDA MEX
您不必创建入口点函数。您可以直接为MATLAB®生成代码fft2函数。为MATLAB生成CUDA MEXfft2函数,在配置对象中设置EnablecuFFT属性和使用codegen函数。GPU编码器替代fft,传输线,fft2,ifft2,fftn,ifftn函数调用在您的MATLAB代码到适当的cuFFT库调用。对于二维和更高的转换,GPU Coder创建多个1-D批量转换。这些批处理变换比单个变换具有更高的性能。在生成MEX函数之后,您可以验证它具有与原始MATLAB入口点函数相同的功能。运行生成的fft2_mex然后画出结果。
cfg = code . gpuconfig (墨西哥人的);cfg. gpconfig . enablecufft = 1;codegen配置cfgarg游戏{光源}fft2farfieldsignalGPU = fft2_mex(光源);STR = sprintf(GPU矩形孔径远场衍射图);可视化(farfieldsignalGPU str);
代码生成成功。

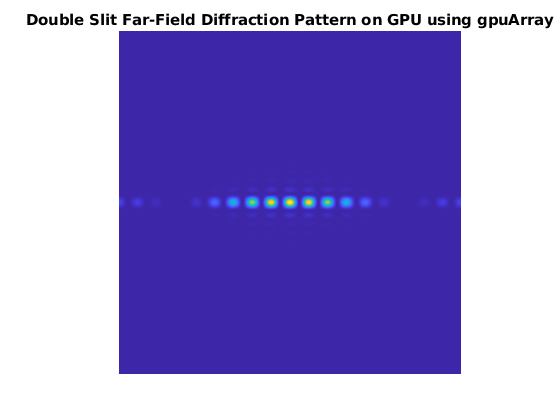
模拟杨氏双缝实验
杨氏双缝实验表明,当孔径由两条平行狭缝组成时,会产生光干涉。在建设性干涉发生的地方,可以看到一系列亮点。在本例中,形成代表两条狭缝的孔径。限制光圈在方向,以确保所产生的图案不完全集中在水平轴上。
缝= (abs(gx) <= 10/N2) .* (abs(gx) >= 8/N2);孔径=缝。* (abs(gy) < 20/N2);光源=双(光圈);
显示杨氏双缝的光强
由于输入的大小、类型和复杂性保持不变,因此可以重用fft2_mex生成mex函数并显示强度。
farfieldsignalGPU = fft2_mex(光源);STR = sprintf(GPU双缝远场衍射图);可视化(farfieldsignalGPU str);

使用GPU指针作为输入生成CUDA MEX
在上面生成的CUDA MEX中,提供给MEX的输入从CPU复制到GPU内存中,在GPU上进行计算,并将结果复制回CPU。或者,可以生成CUDA代码,这样它就可以直接接受GPU指针。对于MEX目标,GPU指针可以从MATLAB®传递到CUDA MEX使用gpuArray.对于其他目标,必须分配GPU内存,并且必须在手写的主函数内将输入从CPU复制到GPU,然后才将它们传递给入口点函数。
lightsource_gpu = gpuArray(光源);cfg = code . gpuconfig (墨西哥人的);cfg. gpconfig . enablecufft = 1;codegen配置cfgarg游戏{lightsource_gpu}fft2- offt2_gpu_mex
代码生成成功。
只有数字和逻辑输入矩阵类型可以作为GPU指针传递给入口点函数。其他不受支持的数据类型可以作为CPU输入传递。金宝app在代码生成过程中,如果提供给入口点函数的输入中至少有一个是GPU指针,那么函数返回的输出也是GPU指针。但是,如果输出的数据类型不支持作为GPU指针,例如结构体或单元格数组,则输出将作为CPU指针返金宝app回。有关将GPU指针传递给入口点函数的更多信息,请参见金宝app支持GPU阵列.
注意使用时生成的CUDA代码中的差异lightsource_gpuGPU的输入。它避免了将输入从CPU复制到GPU内存,也避免了将结果从GPU复制回CPU内存。这会导致更少的cudaMemcpys并提高了生成的CUDA MEX的性能。
以GPU指针为输入的CUDA MEX结果验证
验证生成的CUDA是否使用MEXgpuArray具有相同的功能,运行生成fft2_gpu_mex,在主机上收集结果并绘制结果。
Farfieldsignal_gpu = fft2_gpu_mex(lightsource_gpu);Farfieldsignal_cpu = gather(farfieldsignal_gpu);STR = sprintf(基于gpuArray的GPU双缝远场衍射图);可视化(farfieldsignal_cpu str);
另请参阅
功能
codegen|coder.gpu.kernel|coder.gpu.kernelfun|gpucoder.matrixMatrixKernel|coder.gpu.constantMemory|gpucoder.stencilKernel|coder.checkGpuInstall
对象
相关的话题
您也可以从以下列表中选择一个网站:
