在MATLAB中使用高阵列分析大数据
此示例显示了如何在MATLAB®中使用高数组处理大数据。您可以使用高数组对内存中不适合的不同类型的数据执行各种计算。这些计算包括基本计算,以及统计和机器学习工具箱中的机器学习算法™.
此示例在一台计算机上对一小部分数据进行操作,然后将其放大以分析所有数据集。然而,这种分析技术可以进一步扩展,以处理太大而无法读入内存的数据集,或者处理ApacheSpark之类的系统™.
塔式阵列简介
高数组和高表用于处理具有任意行数的内存不足数据。不用编写专门的代码来考虑数据的巨大大小,高数组和表让您以类似于内存中的MATLAB®数组的方式处理大数据集。区别在于高的在请求执行计算之前,阵列通常保持未计算状态。
这种延迟评估使MATLAB能够在可能的情况下组合排队计算,并获得通过数据的最小次数。由于通过数据的次数会极大地影响执行时间,因此建议仅在必要时请求输出。
为文件集合创建数据存储
通过创建数据存储,您可以访问数据集合。数据存储可以处理任意数量的数据,数据甚至可以分布在多个文件夹中的多个文件中。您可以为大多数类型的文件创建数据存储,包括表格文本文件集合(此处演示),电子表格,图像,SQL数据库(数据库工具箱™ 必需)、Hadoop®序列文件等。
为数据库创建数据存储. csv包含航空公司数据的文件。Treat“不”值丢失,以便表格数据存储将它们替换为南值。属性的分类数据类型,并选择感兴趣的变量起源和桌子变量。预览内容。
ds=表格数据存储(“airlinesmall.csv”); D.TreatAsMissing=“不”;ds.SelectedVariableNames={“年”,“月”,“延迟”,“德布雷”,“起源”,“目的地”};ds.选定格式(5:6)={“%C”,“%C”};=之前预览(ds)
前=8×6表年-月ARRRDEPDLAY DEPDLAY Origin Dest(目的地)(目的地)(目的地)(目的地)(目的地)(目的地)(目的地)(目的地)目的地(目的地)目的地(目的地)目的地)目的地(目的地)目的地)目的地(目的地)目的地)目的地)目的地(目的地
创建高数组
高数组与内存中的MATLAB数组类似,只是它们可以有任意数量的行。高数组可以包含数字、逻辑、日期时间、持续时间、日历持续时间、分类或字符串数据。此外,还可以将内存中的任何阵列转换为高阵列。(在内存阵列中)A.必须是受支持的数据类型之一。)金宝app
高数组的底层类基于支持它的数据存储的类型。例如,如果数据存储ds包含表格数据,然后高(ds)返回包含数据的高表。
tt =高(ds)
tt=Mx6高台年-月ARRDEAL DEPDLAY Origin Dest\uuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu
该显示显示了基础数据类型,并包括前几行数据。表的大小显示为“Mx6”,表示MATLAB还不知道有多少行数据。
在高数组上执行计算
您可以使用与内存中的MATLAB数组和表类似的方式来处理高数组和高表。
高大阵列的一个重要方面是,当您使用它们时,MATLAB不会立即执行大多数操作。这些操作似乎执行得很快,因为实际的计算会推迟到您专门请求输出时进行。这种延迟求值很重要,因为即使是像尺寸(X)在10亿行的高数组上执行不是一个快速计算。
当您使用塔式阵列时,MATLAB会跟踪所有要执行的操作,并优化通过数据的次数。因此,使用未评估的塔式阵列并仅在需要时请求输出是正常的。在您请求阵列b之前,MATLAB不知道未评估的塔式阵列的内容或大小e评估并显示。
计算平均起飞延误。
mDep =意味着(tt。DepDelay,“奥米南”)
mDep=高双?
将结果收集到工作区中
延迟求值的好处是,当使用MATLAB执行计算时,通常可以将操作组合成通过数据的次数最小化的方式。因此,即使您执行许多操作,MATLAB也只在绝对必要时对数据进行额外的传递。
这个收集函数强制计算所有排队的操作,并将结果输出带回内存。因为收集返回整个结果,你应该确保结果将适合内存。例如,使用收集在高数组上,它是一个函数减少高数组的大小的结果,例如总和,闵,意思是,等等。
使用收集计算平均出发延误,并将答案存入内存。此计算需要对数据进行一次传递,但其他计算可能需要对数据进行多次传递。MATLAB确定计算的最佳通过次数,并在命令行中显示此信息。
mDep=聚集(mDep)
using the Local MATLAB Session: - Pass 1 of 2: Completed in 0.82 sec - Pass 2 of 2: Completed in 0.74 sec
mDep=8.1860
选择高数组的子集
您可以通过下标或索引从高数组中提取值。您可以从顶部或底部开始索引数组,或者使用逻辑索引。的函数头和尾是索引的有用替代方法,使您能够探索高数组的第一部分和最后一部分。同时收集两个变量以避免额外的数据传递。
h=头部(tt);tl=尾部(tt);[h,tl]=聚集(h,tl)
using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.72 sec
h =8×6表年-月ARRRDEPDLAY DEPDLAY Origin Dest(目的地)(目的地)(目的地)(目的地)(目的地)(目的地)(目的地)(目的地)目的地(目的地)目的地(目的地)目的地)目的地(目的地)目的地)目的地(目的地)目的地)目的地)目的地(目的地
tl =8×6表年-月ARRRDEPDLAY DEPDLAY Origin Dest(目的地)(目的地)(目的地)(目的地)(目的地)(目的地)(目的地)(目的地)目的地(目的地)目的地(目的地)目的地)目的地(目的地)目的地)目的地(目的地)目的地)目的地(目的地)目的地)目的地
使用头在缩放到完整数据集之前,从原型代码数据中选择10000行的子集。
ttSubset=人头(tt,10000);
按条件选择数据
您可以在高数组上使用典型的逻辑操作,这对于使用逻辑索引选择相关数据或删除离群值非常有用。逻辑表达式创建一个高的逻辑向量,然后用它来下标,标识条件为真的行。
通过比较分类变量的元素,仅选择从波士顿起飞的航班起源价值“BOS”.
idx=(ttSubset.Origin)==“BOS”);bosflights = ttSubset (idx:)
bosflights = 207 x6高表年月ArrDelay DepDelay起源服务台 ____ _____ ________ ________ ______ ____ 1987年10 8 0 BOS LGA 1987 -13 1 BOS LGA 1987 10 1987年12 11日机场BOS BWI 10 3 0 BOS英文文宣写作研习营1987 10 5 0 BOS奥德1987 10 1987年31日19日BOS PHL 10 3 0 BOS蜡烛1987 11 5 5 BOS STL : : : : : : : : : : : :
您可以使用相同的索引技术从tall数组中删除缺少数据或NaN值的行。
idx=any(ismissing(ttSubset),2);ttSubset(idx,:)=[];
确定最大延迟
由于大数据的性质,使用传统的方法对所有数据进行排序,如分类或索特罗斯效率低下。但是,托普克罗斯用于高数组的函数返回顶部K按排序顺序排列的行。
计算十大最严重的起飞延误。
biggestDelays = topkrows (ttSubset 10“德布雷”);biggestDelays =收集(biggestDelays)
使用本地MATLAB会话评估tall表达式:评估在0.066秒内完成
最大的延误=10×6表年份-月份延迟-延迟-延迟起始日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期-日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期:日期
在高数组中可视化数据
在大数据集中绘制每个点是不可行的。因此,高阵列的可视化涉及使用采样或分块来减少数据点的数量。
用直方图可视化每年的飞行次数。可视化函数传递数据并在您调用它们时立即评估解决方案,所以收集不需要。
直方图(ttSubset。一年,“BinMethod”,“整数”)
使用本地MATLAB会话评估tall表达式:评估在0.42秒内完成
xlabel(“年”)伊拉贝尔(航班的数量)头衔(‘按年份划分的航班数量,1987-1989’)

缩放到整个数据集
而不是使用从头,您可以通过使用的结果对整个数据集执行计算高(ds).
tt=高(ds);idx=任何(ismissing(tt),2);tt(idx,:)=[];mnDelay=平均值(tt.DEPDLAY,“奥米南”);biggestDelays = topkrows (tt 10“德布雷”); [mnDelay,biggestDelays]=聚集(mnDelay,biggestDelays)
使用本地MATLAB会话评估tall表达式:-第1次通过(共2次):在0.46秒内完成-第2次通过(共2次):在0.81秒内完成评估在1.4秒内完成
mnDelay=8.1310
最大的延误=10×6表年-月ARRRDEPDLAY DEPDLAY Origin Dest_uuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu
直方图(tt.Year,“BinMethod”,“整数”)
使用本地MATLAB会话评估tall表达式:-通过1/2:在1.2秒内完成-通过2/2:在0.6秒内完成评估在2.1秒内完成
xlabel(“年”)伊拉贝尔(航班的数量)头衔(‘按年份划分的航班数量,1987-2008’)

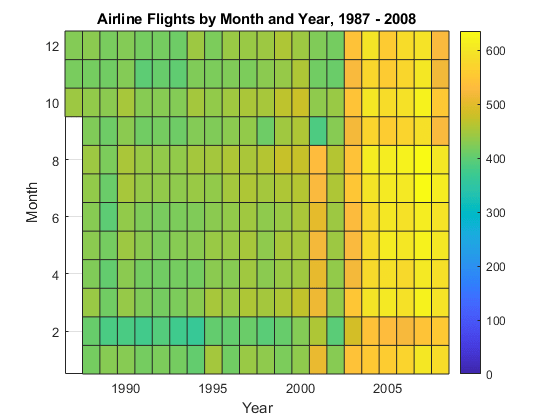
使用histogram2将整个数据集按月进一步分解飞行次数。因为箱子月和年如果提前知道,请指定箱子边缘,以避免额外通过数据。
年份=1986.5:2008.5;月份=0.5:12.5;历史图2(tt.年、tt.月、年、月边缘、,“显示样式”,“瓷砖”)
using the Local MATLAB Session: - Pass 1 of 1: Completed in 1.1 sec
colorbar包含(“年”)伊拉贝尔(“月”)头衔(‘1987-2008年按月份和年份划分的航空航班’)
高数组的数据分析和机器学习
使用Statistics和machine learning Toolbox™中的函数,您可以对高数组执行更复杂的统计分析,包括计算预测分析和执行机器学习。
有关详细信息,请参阅高阵列大数据分析(统计和机器学习工具箱).
扩展到大数据系统
MATLAB中高阵列的一个关键功能是与大数据平台的连接,如计算集群和ApacheSpark™.
此示例仅触及了大数据的高阵列可能存在的问题的表面。请参阅扩展高数组与其他产品下载188bet金宝搏有关使用的详细信息,请参阅:
统计和机器学习工具箱™
数据库工具箱™
并行计算工具箱™
MATLAB®并行服务器™
MATLAB编译器™
另见
相关话题
您还可以从以下列表中选择网站:
