粒子滤波的工作流
粒子滤波器是一种递归的贝叶斯状态估计器,它使用离散粒子来近似估计状态的后验分布。
的粒子滤波算法递归计算状态估计,涉及两个步骤:
预测——该算法根据给定的系统模型,使用先前的状态来预测当前的状态。
校正-该算法使用当前传感器测量来校正状态估计。
该算法还周期性地重新分布或重新采样状态空间中的粒子,以匹配估计状态的后验分布。
估计状态由所有状态变量组成。每个粒子代表一个离散的状态假设。所有粒子的集合用来帮助确定最终的状态估计。
你可以将粒子滤波应用到任意的非线性系统模型中。过程和测量噪声可以遵循任意的非高斯分布。
要正确地使用粒子过滤器,您必须指定参数,例如粒子的数量、初始粒子位置和状态估计方法。此外,如果您有一个特定的运动和传感器模型,您可以在状态转换函数和测量似然函数中分别指定这些参数。有关更多信息,请参见粒子滤波参数.
按照这个基本的工作流程来创建和使用粒子过滤器。本页详细介绍了评估工作流程,并展示了如何在循环中运行粒子过滤器以持续评估状态的示例。
评估工作流程
当使用粒子过滤器时,需要一组步骤来创建粒子过滤器并估计状态。预测和修正步骤是连续估计状态的主要迭代步骤。
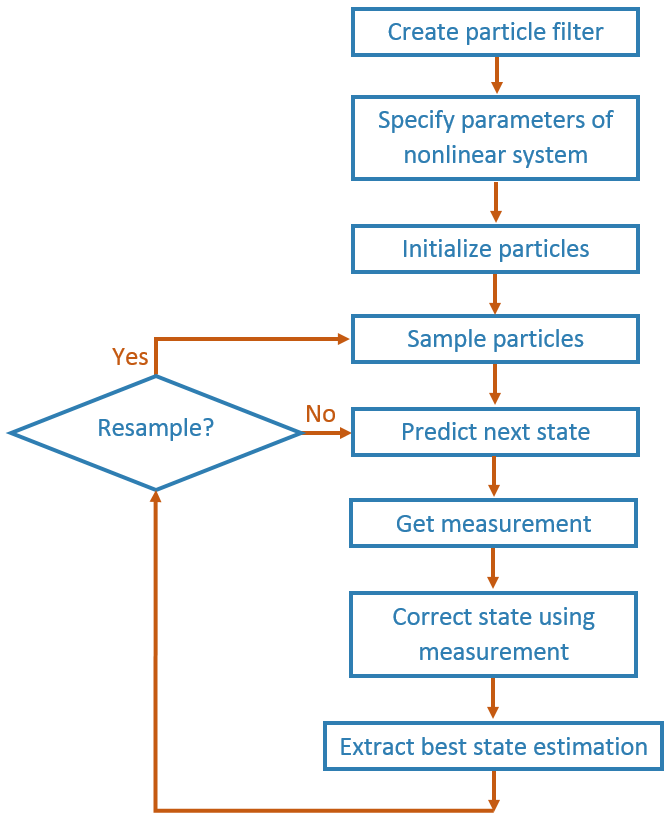
创建粒子滤波
创建一个stateEstimatorPF对象。
设定非线性系统的参数
修改这些stateEstimatorPF适合您的特定系统或应用程序的参数:
StateTransitionFcnMeasurementLikelihoodFcnResamplingPolicyResamplingMethodStateEstimationMethod
这些参数的默认值用于基本操作。
的StateTransitionFcn和MeasurementLikelihoodFcn功能定义了系统行为和度量集成。它们对于粒子滤波器的精确跟踪至关重要。有关更多信息,请参见粒子滤波参数.
初始化粒子
使用初始化函数设置粒子的数目和初始状态。
从一个分布中取样粒子
你可以用两种方法来采样初始粒子的位置:
初始姿态和协方差-如果你知道你的初始状态,建议你指定初始姿态和协方差。这一规格有助于聚集粒子更接近您的估计,所以跟踪是更有效的开始。
状态界限——如果你不知道你的初始状态,你可以指定每个状态变量的可能的界限。粒子均匀地分布在每个变量的状态界上。由于接近实际状态的粒子较少,所以广泛分布的粒子在跟踪方面就不那么有效。使用状态边界通常需要更多的粒子、计算时间和迭代来收敛到实际的状态估计。
预测
根据一个指定的状态转移函数,粒子演化来估计下一个状态。使用预测属性中指定的状态转换函数StateTransitionFcn财产。
得到测量
下一步将使用从传感器收集的测量数据来纠正当前的预测状态。
正确的
然后使用测量来调整预测状态并更正估计。属性指定您的度量值正确的函数。正确的使用MeasurementLikelihoodFcn计算每个粒子的传感器测量值的可能性。当后续迭代的状态发生变化时,需要重新采样粒子来更新您的估计。此步骤将基于ResamplingMethod和ResamplingPolicy属性。
提取最佳状态估计
后调用正确的,则自动提取最佳状态估计权重每个粒子和StateEstimationMethod对象中指定的属性。最佳估计状态和协方差是由正确的函数。
重新取样粒子
此步骤不是单独调用的,而是在调用时执行的正确的.一旦你的状态发生了足够的变化,根据最新的估计重新采样你的粒子。的正确的方法检查ResamplingPolicy用于根据粒子的当前分布及其权重触发粒子重采样。如果未触发重采样,则使用相同的粒子进行下一次估计。如果您的状态变化不大,或者您的时间步长很低,那么您可以调用predict和correct方法而不需要重新采样。
不断地预测和纠正
根据需要重复前面的预测和校正步骤以估计状态。修正步骤决定是否需要重新采样粒子。多次要求预测或正确的可能需要:
没有可用的测量,但控制输入和时间更新发生在一个高频率。使用
预测方法对粒子进行进化,使其更频繁地获得预测的更新状态。多重测量读数是可用的。使用
正确的集成来自相同或多个传感器的多个读数。该函数根据收集的每一组信息纠正状态。
另请参阅
正确的|getStateEstimate|初始化|预测|stateEstimatorPF
相关的例子
更多关于
你也可以从以下列表中选择一个网站: