对GPU上的A\b进行基准测试
这个例子着眼于我们如何在GPU上对线性系统进行基准测试。说明:MATLAB®代码求解。-x在A * x =是非常简单的。最常用的是矩阵左除法,也称为mldivide或者使用反斜杠操作符(\)进行计算x(即,x = A \ b).
相关例子:
基准\ b使用分布式阵列。
在这个函数中可以找到这个例子中的代码:
函数结果= paralleldemo_gpu_backslash (maxMemory)
为计算选择合适的矩阵大小是很重要的。我们可以通过指定CPU和GPU可用的系统内存量(以GB为单位)来实现这一点。默认值仅基于GPU上可用的内存数量,您可以指定一个适合您的系统的值。
如果nargin == 0 g = gpuDevice;maxMemory = 0.4 * g.AvailableMemory / 1024 ^ 3;结束
基准测试函数
我们想要基准矩阵左除法(\),而不是在CPU和GPU之间传输数据的成本,创建矩阵的时间,或其他参数。因此,我们将数据生成与线性系统的求解分离开来,只测量后者所需的时间。
函数[A, b] = getData(n, clz) fprintf(“创建大小为%d-by-%d.\n的矩阵”n, n);A = rand(n, n, clz) + 100*eye(n, n, clz);B = rand(n, 1, clz);结束函数time = timeSolve(A, b, waitFcn) tic;x = \ b;%#ok不需要x的值。 waitFcn ();%等待操作完成。时间= toc;结束
选择问题的大小
与许多其他并行算法一样,并行求解线性系统的性能很大程度上取决于矩阵的大小。就像在其他例子中看到的基准\ b,比较了算法在不同矩阵大小下的性能。
%声明矩阵大小为1024的倍数。maxSizeSingle =地板(√maxMemory * 1024 ^ 3/4));maxSizeDouble =地板(√maxMemory * 1024 ^ 3/8));一步= 1024;如果maxSizeDouble/((5*步));/ *步结束sizeSingle = 1024:步骤:maxSizeSingle;sizeDouble = 1024:步骤:maxSizeDouble;
比较性能:吉拍
我们使用每秒浮点运算数来衡量性能,因为这允许我们比较不同矩阵大小下算法的性能。
给定矩阵大小,基准测试函数创建矩阵一个右边b一次,然后解一个\ b几次就能准确计算出所需的时间。我们使用HPC Challenge的浮点运算计数,因此对于一个n × n矩阵,我们将浮点运算计数为2/3 * n ^ 3 + 3/2 * n ^ 2。
这个函数被传递到一个'wait'函数的句柄中。在CPU上,这个函数不执行任何操作。对于GPU,此功能将等待所有未完成的操作完成。这样的等待确保了准确的时间。
函数gflops = benchFcn(A, b, waitFcn) numrep = 3;时间=正;我们解了线性系统几次,并计算了千兆浮点运算%基于最佳时间。为itr = 1: numrep tcurr = timeSolve(A, b, waitFcn);Time = min(tcurr, Time);结束%测量调用wait函数带来的开销。tover =正;为itr = 1: numrep tic;waitFcn ();tcurr = toc;Tover = min(tcurr, Tover);结束从测量的时间中删除开销。不要让时间去做%变得消极。Time = max(Time - tover, 0);n = size(A, 1);= 2/3*n^3 + 3/2*n^2;gflops =失败/时间/ 1 e9;结束CPU不需要等待:这个函数句柄是一个占位符。函数waitForCpu ()结束%在GPU上,为了确保准确的定时,我们需要等待设备%以完成所有挂起的操作。函数waitForGpu(设备)等(设备);结束
执行标准
完成所有设置后,执行基准测试就很简单了。然而,计算可能需要很长时间才能完成,因此我们在完成对每个矩阵大小的基准测试时打印一些中间状态信息。我们还在函数中封装了所有矩阵大小的循环,以对单精度和双精度计算进行基准测试。
函数[gflopsCPU, gflopgpu] = executeBenchmarks(clz,大小)fprintf([“以%d不同的%s-precision开始基准测试”...' '大小从%d-by-%d到%d-by-%d的矩阵。\n'],...长度(尺寸),clz,尺寸(1),尺寸(1),尺寸(结束),...大小(结束));gflopsGPU = 0(大小(尺寸));gflopsCPU = 0(大小(尺寸));gd = gpuDevice;为I = 1:length(size) n = size (I);[A, b] = getData(n, clz); / /获取数据gflopsCPU(i) = benchFcn(A, b, @waitForCpu);流(' CPU上的Gigaflops: %f\n'gflopsCPU(我));= gpuArray ();b = gpuArray (b);gflopsGPU(i) = benchFcn(A, b, @() waitForGpu(gd)));流(“GPU上的Gigaflops: %f\n”gflopsGPU(我));结束结束
然后以单精度和双精度执行基准测试。
[cpu, gpu] = executeBenchmarks(“单一”, sizeSingle);结果。sizeSingle = sizeSingle;结果。gflopsSingleCPU = cpu;结果。gflopsSingleGPU = gpu;[cpu, gpu] = executeBenchmarks(“双”, sizeDouble);结果。sizeDouble = sizeDouble;结果。gflopsDoubleCPU = cpu;结果。gflopsDoubleGPU = gpu;
开始基准测试时使用7个不同的单精度矩阵,大小从1024 × 1024到19456 × 19456。创建一个1024 × 1024大小的矩阵。GPU: 78.474002创建一个4096 × 4096的矩阵。创建一个大小为7168 × 7168的矩阵。GPU: 862.755636创建大小为10240 × 10240的矩阵。GPU: 978.362901创建13312 × 13312的矩阵GPU: 1107.983667创建一个16384 × 16384的矩阵。GPU: 1186.423754创建大小为19456 × 19456的矩阵。启动基准测试,使用5个不同的双精度矩阵,大小从1024 × 1024到13312 × 13312。创建一个1024 × 1024大小的矩阵。 Gigaflops on CPU: 34.902918 Gigaflops on GPU: 72.191488 Creating a matrix of size 4096-by-4096. Gigaflops on CPU: 74.458136 Gigaflops on GPU: 365.339897 Creating a matrix of size 7168-by-7168. Gigaflops on CPU: 93.313782 Gigaflops on GPU: 522.514165 Creating a matrix of size 10240-by-10240. Gigaflops on CPU: 104.219804 Gigaflops on GPU: 628.301313 Creating a matrix of size 13312-by-13312. Gigaflops on CPU: 108.826886 Gigaflops on GPU: 681.881032
绘制的性能
现在我们可以绘制结果,并比较CPU和GPU的性能,包括单精度和双精度。
首先,我们看看反斜杠操作符在单精度下的性能。
无花果=图;ax =轴(“父”图);情节(ax,结果。sizeSingle results.gflopsSingleGPU,“- x”,...结果。sizeSingle results.gflopsSingleCPU,“o”网格)在;传奇(“图形”,“CPU”,“位置”,“西北”);标题(ax,单精度性能的) ylabel (ax,“吉拍”);包含(ax,矩阵大小的);drawnow;

现在,我们来看看反斜杠操作符在双精度下的性能。
无花果=图;ax =轴(“父”图);情节(ax,结果。sizeDouble results.gflopsDoubleGPU,“- x”,...结果。sizeDouble results.gflopsDoubleCPU,“o”)传说(“图形”,“CPU”,“位置”,“西北”);网格在;标题(ax,“双精度性能”) ylabel (ax,“吉拍”);包含(ax,矩阵大小的);drawnow;

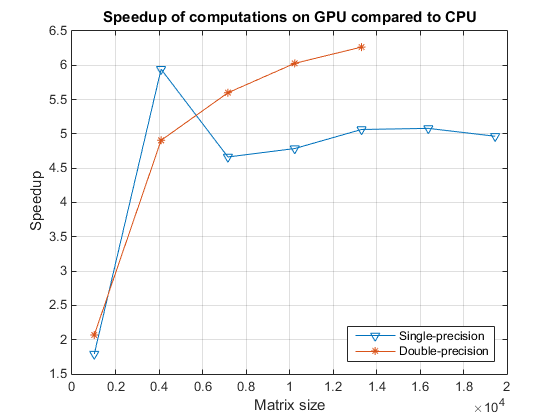
最后,在比较GPU和CPU时,我们看看反斜杠运算符的加速。
speedupDouble = results.gflopsDoubleGPU. / results.gflopsDoubleCPU;speedupSingle = results.gflopsSingleGPU. / results.gflopsSingleCPU;无花果=图;ax =轴(“父”图);情节(ax,结果。sizeSingle speedupSingle,“v”,...结果。sizeDouble speedupDouble,“- *”网格)在;传奇(单精度的,“双精度”,“位置”,“东南”);标题(ax,与CPU相比,GPU的计算速度更快);ylabel (ax,“加速”);包含(ax,矩阵大小的);drawnow;
结束
ans = sizeSingle: [1024 4096 7168 10240 13312 16384 19456] gflopsSingleCPU: [1x7 double] gflopsSingleGPU: [1x7 double] sizeDouble: [1024 4096 7168 10240 13312] gflopsDoubleCPU: [34.9029 74.4581 93.3138 104.2198 108.8269] gflopsdoulegpu: [72.1915 365.3399 522.5142 628.3013 681.8810]
你也可以从以下列表中选择一个网站: