基准测试独立工作在集群上
在这个例子中,我们将展示如何使用独立的工作基准应用程序集群,我们详细分析结果。特别是,我们:
展示如何基准序列代码和任务并行代码的混合物。
解释强和弱扩展。
讨论一些潜在的瓶颈,对客户端和集群。
注意:如果您在大型集群中运行这个例子,可能需要一个小时。
相关例子:
这个示例中所示的代码可以在这个函数:
函数paralleldemo_distribjob_bench
检查集群的配置文件
在我们与集群交互之前,我们验证MATLAB®客户机配置根据我们的需求。调用parcluster会给我们一个集群使用默认配置文件或将抛出一个错误如果默认不是可用的。
myCluster = parcluster;
时机
我们分开时间所有操作允许我们检查细节。我们需要所有这些详细的时间来理解时间,和孤立潜在的瓶颈。目的的例子,实际的基准函数不是很重要;在本例中,我们模拟的纸牌游戏21点或21。
我们写的所有操作尽可能的高效。例如,我们使用矢量化任务创建。我们使用抽搐和toc测量的时间而不是使用的所有操作工作和任务属性CreateDateTime,StartDateTime,FinishDateTime等,因为抽搐和toc给我们次秒级粒度。注意,我们还检测任务函数,返回时间执行我们的基准计算。
函数[*,描述]= timeJob (myCluster、numTasks numHands)%的代码创建工作和任务执行顺序% MATLAB客户机从这里开始。%我们第一次测量需要多长时间来创建一个工作。timingStart =抽搐;开始=抽搐;工作= createJob (myCluster);次了。jobCreateTime = toc(开始);描述。jobCreateTime =“就业时间”;%在一个叫createTask创建的所有任务,并衡量多久%,。开始=抽搐;taskArgs = repmat ({{numHands 1}}, numTasks, 1);createTask(工作,@pctdemo_task_blackjack 2 taskArgs);次了。taskCreateTime = toc(开始);描述。taskCreateTime =“任务创建时间”;%测量需要多长时间提交到集群的工作。开始=抽搐;提交(工作);次了。submitTime = toc(开始);描述。submitTime =“作业提交时间”;%一旦工作已经提交,我们希望所有的任务执行%平行。我们测量需要多长时间的所有任务开始%和运行完成。开始=抽搐;等待(工作);次了。jobWaitTime = toc(开始);描述。jobWaitTime =“工作等待时间”;%的任务已经完成了,所以我们再次执行顺序代码%在MATLAB客户端。我们测量需要多长时间来检索%的工作结果。开始=抽搐;结果= fetchOutputs(工作);次了。resultsTime = toc(开始);描述。resultsTime =“结果检索时间”;%验证工作运行没有任何错误。如果~ isempty ([job.Tasks.Error]) taskErrorMsgs = pctdemo_helper_getUniqueErrors(工作);删除(工作);错误(“pctexample: distribjobbench: JobErrored”,…(发生以下错误(s)在任务”…“执行:\ n \ n % s”),taskErrorMsgs);结束%得到任务的执行时间。我们的任务函数返回%作为第二输出参数。次了。exeTime = max([结果{:2}]);描述。exeTime =任务执行时间的;%测量需要多长时间删除工作及其所有任务。开始=抽搐;删除(工作);times.deleteTime = toc(开始);description.deleteTime =“工作删除时间”;%的总时间从创建工作%点。次了。totalTime = toc (timingStart);描述。totalTime =的总时间;次了。numTasks = numTasks;描述。numTasks =“数量的任务”;结束
我们看一些我们所测量的细节:
就业时间:创建一个工作所花费的时间。MATLAB集群作业调度程序,这涉及到一个远程调用,MATLAB作业调度器分配空间的数据基础。对于其他集群类型,就业需要写一些文件到磁盘。
任务创建时间:所花费的时间创建并保存任务信息。MATLAB作业调度器保存此数据库,而其他集群类型将其保存在文件系统上的文件。
作业提交时间:时间提交工作。MATLAB集群作业调度程序,我们告诉它开始执行工作的数据基础。我们问其他集群类型来执行所有的任务我们已经创建了。
工作等待时间:作业提交后的时间我们等待,直到工作完成。这包括所有的活动发生在作业提交工作已完成,如:集群可能需要开始所有的工人,把工人的任务信息;工人们阅读任务信息,并执行任务的功能。在MATLAB作业调度器集群的情况下,工人们然后把任务结果MATLAB作业调度器,写他们的数据基础,而对于其他集群类型、工人的任务结果写入到磁盘。
任务执行时间:模拟时间21点。我们这次的任务函数精确测量工具。这一次也是包含在等待时间的工作。
检索结果的时间:所花费的时间将工作成果转化为MATLAB客户机。MATLAB作业调度器,我们从数据库中获取它们。对于其他集群类型,我们从文件系统读取它们。
删除工作时间:删除所有的时间工作和任务信息。MATLAB作业调度器删除它从它的数据基础。对于其他集群类型,我们从文件系统中删除文件。
总时间:执行所有的时间。
选择问题的大小
我们知道大多数集群设计为批处理执行中或长时间运行的工作,所以我们故意试图在范围之内,我们的基准计算。然而,我们不希望运行这个例子来花费几个小时的时间,所以我们选择问题的大小,每个任务对我们的硬件,大约需要1分钟,然后重复计时测量几次以提高准确性。作为一个经验法则,如果你的计算任务需要不到一分钟的时间,你应该考虑parfor满足您的低延迟需求比工作和任务。
numHands = 1.2 e6;numReps = 5;
我们探索加速通过运行在不同数量的工人,从1开始,2、4、8、16日等,和结束我们可以使用尽可能多的工人。在这个例子中,我们假设我们有专门的访问为基准,集群和集群的NumWorkers属性被设置正确。假设的情况下,每个任务马上将执行在一个专门的工人,所以我们可以把我们提交的任务数量等同于执行它们的工人数量。
numWorkers = myCluster。NumWorkers;如果isinf (numWorkers) | | (numWorkers = = 0)错误(“pctexample: distribjobbench: InvalidNumWorkers”,…(“不能推断出工人从集群的数量。”…的默认配置文件设置NumWorkers“…“值0或inf。”]);结束numTasks = [pow2(0:装天花板(log2 (numWorkers) - 1)), numWorkers);
弱定标测量
我们不同任务的数量在一个工作,并且每个任务执行一个固定数量的工作。这就是所谓的弱扩展,是我们真正最关心的,因为我们通常扩大集群解决更大的问题。它应该较强扩展基准之后,在本例中所示。基于弱比例也称为加速按比例缩小的加速。
流([“弱扩展时间开始。”…的提交总% d工作。\ n '),numReps *长度(numTasks));为j = 1:长度(numTasks) n = numTasks (j);为itr = 1: numReps[代表(itr),描述]= timeJob (myCluster n numHands);% #好< AGROW >结束%保留最低的迭代总时间。totalTime = [rep.totalTime];=最快找到(totalTime = = min (totalTime), 1);弱(j) =代表(最快);% #好< AGROW >流(的工作等待时间% d任务(s): % f秒\ n ',…n,弱(j) .jobWaitTime);结束
开始弱扩展时机。提交共有45个工作。工作与1任务等待时间:59.631733秒工作等待时间与2任务(s): 60.717059秒的工作与4个任务等待时间:61.343568秒工作等待时间8任务(s): 60.759119秒的工作与16个任务等待时间:63.016560秒的工作与32个任务等待时间:64.615484秒工作等待时间与64年任务(s): 66.581806秒工作等待时间与128年任务(s): 91.043285秒工作等待时间与256年任务(s): 150.411704秒
顺序执行
我们测量的顺序执行时间计算。注意,这个时间应该在集群上执行时间相比只有它们有相同的硬件和软件配置。
seqTime =正;为itr = 1: numReps开始=抽搐;pctdemo_task_blackjack (numHands, 1);seqTime = min (seqTime toc(开始);结束流(的顺序执行时间:\ n % f秒”,seqTime);
顺序执行时间:84.771630秒
基于弱比例和总执行时间的加速
我们首先看看整体加速通过运行在不同数量的工人。加速基于所用的总时间计算,所以它既包括顺序和并行的部分代码。
加速曲线代表了多个项目的功能与未知权重与他们每个人:集群硬件,集群软件,客户端硬件、客户端软件,客户端和集群之间的联系。因此,加速曲线不代表任何一个,但所有加在一起。
如果加速曲线符合你的预期的业绩目标,你知道所有上述因素很好地协同工作在这个特定的基准。然而,如果加速曲线不符合你的目标,你不知道哪个上面列出的许多因素是最罪魁祸首。它甚至可以在应用程序的并行化的方法是罪魁祸首,而不是其他软件或硬件。
新手常常相信这单图给出了完整的集群的硬件或软件的性能。这确实不是这样的,总是需要知道这张图不允许我们对潜在的性能瓶颈得出任何结论。
titleStr = sprintf ([“加速基于总执行时间\ n”…注:本图不确定性能的…“瓶颈”]);pctdemo_plot_distribjob (“加速”(weak.numTasks),(弱。totalTime],…(1)疲软。totalTime titleStr);

详细的图,第1部分
我们再深入一点了解,看看我们的代码的各个步骤的时间了。我们的基准测试弱扩展,我们创建的多个任务,我们做的更多的工作。因此,任务输出数据的大小增加增加任务的数量。有鉴于此,我们希望以下需要更长时间我们创建的多个任务:
任务创建
输出参数检索工作
工作破坏时间
我们没有理由相信以下增加的任务:
就业时间
毕竟,创建工作之前我们定义它的任何任务,所以没有理由随任务的数量。我们可能只期望看到一些随机波动的就业时间。
pctdemo_plot_distribjob (“字段”、弱、描述…{“jobCreateTime”,“taskCreateTime”,“resultsTime”,“deleteTime”},…的时间间隔,以秒为单位);

归一化时代
我们已经得出结论,任务创建时间预计将增加我们增加任务的数量,时间检索的工作输出参数和删除工作。然而,这一增长是由于这一事实我们执行更多的工作增加工人的数量/任务。因此意义来衡量的效率这三个活动通过观察执行这些操作所花费的时间,和规范化的任务的数量。通过这种方式,我们可以看看是否有下列*保持不变,增加,或减少我们不同的任务:
所花费的时间创建一个单一的任务
所花费的时间从一个任务检索输出参数
所花费的时间删除任务的工作
规范化次这张图代表了MATLAB的功能客户端和集群的部分硬件或软件,它可能会相互作用。它通常被认为是好的如果这些曲线保持平坦,和优秀的减少。
pctdemo_plot_distribjob (“normalizedFields”、弱、描述…{“taskCreateTime”,“resultsTime”,“deleteTime”});

有时这些图表显示检索结果每个任务的时间下降随着任务数量的增加。这无疑是好:我们成为我们执行更多的工作更有效率。这可能发生,如果有一个固定数量的操作开销,如果需要一个固定的时间每个任务的工作。
我们不能指望一个加速曲线基于总执行时间是特别好的,如果它包含大量的时间花在连续的活动,如上述,在与数量的任务所花费的时间增加。在这种情况下,连续的活动将主导一旦有足够多的任务。
详细的图,第2部分
可能花费的时间在每个步骤后随任务的数量,但我们希望它不会:
作业提交时间。
任务执行时间。这抓住了模拟的时间21点。不多不少。
在这两种情况下,我们看时间,也称为挂钟时间。我们看在集群上的总CPU时间和规范化。
pctdemo_plot_distribjob (“字段”、弱、描述…{“submitTime”,“exeTime”});

上面有每个时代的情况可能会增加数量的任务。例如:
用一些第三方集群类型、作业提交涉及一个系统调用每个任务的工作,或者是作业提交包括通过网络复制文件。在这些情况下,作业提交时间与任务的数量可能会增加线性。
任务执行时间的图像是最容易暴露硬件限制和资源争用。例如,我们正在执行的任务执行时间可能会增加如果同一台计算机上的多个工人,由于争夺有限的内存带宽。资源争用的另一个例子是如果任务函数读或写大型数据文件使用一个共享文件系统。任务函数在这个例子中,然而,不访问文件系统。这些类型的硬件限制了详细的例子在任务并行资源争用问题。
加速基于弱比例和工作等待时间
现在我们已经切割时间花在我们的代码的不同阶段,我们想创建一个加速曲线,更准确地反映了我们的集群的硬件和软件的功能。我们通过计算加速曲线基于等待时间的工作。
当计算加速曲线基于作业等待时间,我们首先比较所花费的时间执行一个任务在集群上的工作。
titleStr =“加速基于工作等待时间比一个任务的;pctdemo_plot_distribjob (“加速”(weak.numTasks),(弱。jobWaitTime],…(1)疲软。jobWaitTime titleStr);
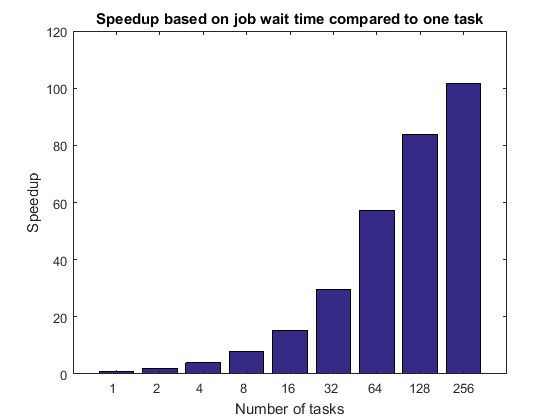
等待时间可能包括工作时间开始所有MATLAB工人。因此可能是有界的IO功能共享的文件系统。等待时间的工作还包括平均任务执行时间,因此任何缺陷在这里也适用。如果我们没有专用访问集群中,我们可以期望加速曲线基于工作等待时间遭受显著。
接下来,我们比较的工作等待时间顺序执行时间,假设客户端计算机的硬件与计算节点。如果客户没有与集群节点,这种比较是完全没有意义的。如果集群有大量的时间滞后,将任务分配给工人,例如,通过将任务分配给工人每分钟只有一次,这张图将严重影响,因为顺序执行时间不受这种滞后。注意,这张图将有相同的形状与前面图,他们只会相差一个常数,乘法因子。
titleStr =“加速基于等待时间相比,连续工作时间;pctdemo_plot_distribjob (“加速”(weak.numTasks),(弱。jobWaitTime],…seqTime titleStr);
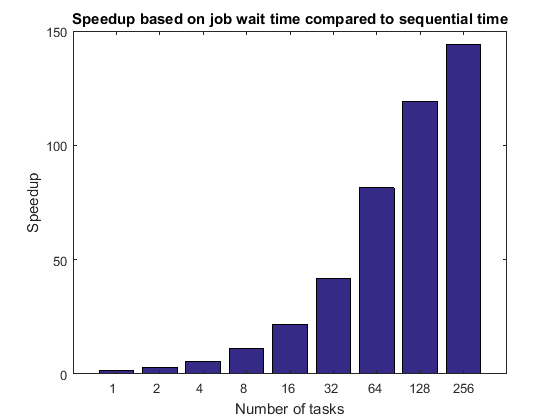
比较工作等待时间和任务执行时间
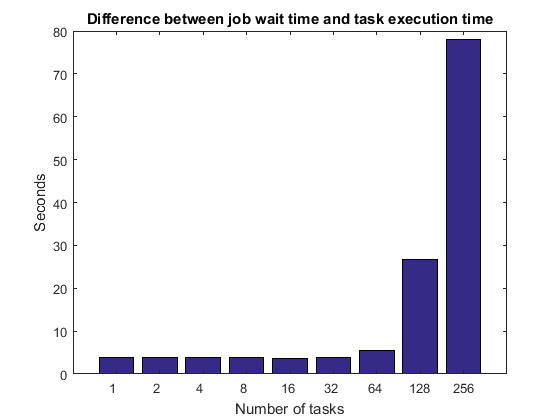
正如我们之前提到过的,包括任务执行时间的工作等待时间+调度,等待时间的集群队列,MATLAB的启动时间,等在懒懒的集群,工作等待时间之间的差异和任务执行时间应该保持不变,至少对于小数量的任务。任务数量的增加到数十,数百或数以千计,我们最终一定会遇到一些限制。例如,当我们有足够多的任务/工人,集群不能告诉所有的工人同时开始执行他们的任务,或者如果MATLAB工人都使用相同的文件系统,他们可能最终饱和的文件服务器。
titleStr =“区别工作等待时间和任务执行时间的;pctdemo_plot_distribjob (“barTime”(weak.numTasks),…(弱。jobWaitTime] -[疲软。exeTime], titleStr);
强大的扩展测量
我们现在衡量一个固定大小的执行时间的问题,而我们使用不同数量的工人来解决这个问题。这就是所谓的强大的扩展,众所周知,如果一个应用程序有任何连续的部分,有一个上限的加速与强大的扩展可以实现。这是正式的Amdahl法则已被广泛讨论和辩论。
你可以很容易遇到强劲的加速扩展的极限时,将作业提交到集群上。如果任务执行一个固定的开销(它通常),哪怕是一秒,我们的应用程序的执行时间永远不会低于1秒。在我们的例子中,我们从一个应用程序,该应用程序在大约60秒执行一个MATLAB工人。如果我们将计算在60多名员工,可能需要为每个工人只要一秒来计算它的整个问题的一部分。然而,一秒钟的假想的任务执行开销已成为一个主要因素的总体执行时间。
除非你的应用程序运行很长一段时间,工作和任务通常不实现好的结果的方式,并有很强的扩展。如果任务执行的开销接近应用程序的执行时间,你应该调查parfor满足您的需求。即使在的情况下parfor,有一个固定数量的开销,尽管远小于常规工作和任务,这开销限制加速,可以实现强大的扩展。你的问题大小相对于集群大小可能是也可能不是很大,你经历这些限制。
一般的经验法则,它只能实现强大的扩展的小问题大量的处理器和专用硬件和大量的编程工作。
流([“强大的扩展时间开始。”…的提交总% d工作。\ n '),numReps *长度(numTasks))为j = 1:长度(numTasks) n = numTasks (j);strongNumHands =装天花板(numHands / n);为itr = 1: numReps代表(itr) = timeJob (myCluster n strongNumHands);结束印第安纳州=找到([代表。totalTime] = = min ([rep.totalTime]), 1);强(n) =代表(印第安纳州);% #好< AGROW >流(的工作等待时间% d任务(s): % f秒\ n ',…n,强(n) .jobWaitTime);结束
强大的扩展时间开始。提交共有45个工作。工作与1任务等待时间:60.531446秒工作等待时间与2任务(s): 31.745135秒的工作与4个任务等待时间:18.367432秒工作等待时间8任务(s): 11.172390秒的工作与16个任务等待时间:8.155608秒的工作与32个任务等待时间:6.298422秒工作等待时间与64年任务(s): 5.253394秒工作等待时间与128年任务(s): 5.302715秒工作等待时间与256年任务(s): 49.428909秒
基于强大的扩展和总执行时间的加速
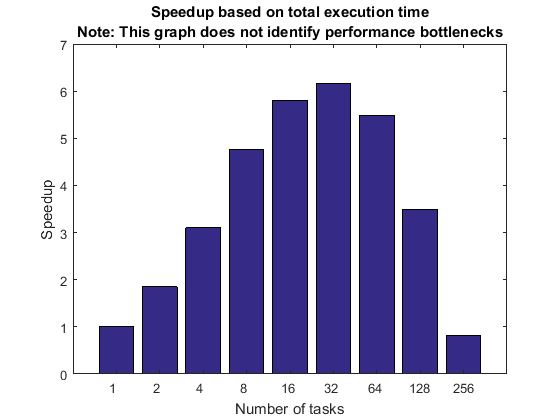
正如我们已经讨论的,加速曲线描述的和执行的时间顺序在MATLAB客户端代码和时间在集群上执行并行代码可以非常误导。下面的图显示了这些信息的最坏的情况强大的扩展。我们故意选择最初的问题是如此之小相对于集群大小的加速曲线会坏。集群的硬件和软件设计时考虑到这种使用。
titleStr = sprintf ([“加速基于总执行时间\ n”…注:本图不确定性能的…“瓶颈”]);pctdemo_plot_distribjob (“加速”(strong.numTasks),…[strong.totalTime]。*[强劲。numTasks],强大的(1)。totalTime titleStr);
选择短的任务:PARFOR
强大的扩展结果看起来并不好,因为我们故意用工作和任务执行的计算时间短。现在我们看看如何parfor适用于同样的问题。注意,我们不包括游泳池的开放时间我们的时间测量。
池= parpool (numWorkers);parforTime =正;strongNumHands =装天花板(numHands / numWorkers);为itr = 1: numReps开始=抽搐;细胞(r = 1, numWorkers);parfori = 1: numWorkers r{我}= pctdemo_task_blackjack (strongNumHands, 1);% #好< PFOUS >结束parforTime = min (parforTime toc(开始);结束删除(池);
开始平行池(parpool)使用“bigMJS”概要文件…连接到256名工人。工人们…做分析和传输文件。
基于强大的扩展与PARFOR加速
最初,顺序计算了大约一分钟,所以每个工人只需要执行几秒钟的大规模计算集群。因此,我们希望强大的扩展性能好得多parfor比工作和任务。
流(的执行时间parfor使用% d工人:% f秒\ n ',…numWorkers parforTime);流([“加速基于强大的扩展parfor使用”,…“% d工人:% f \ n”,numWorkers seqTime / parforTime);
执行时间与使用256名工人parfor: 1.126914秒加速基于强大的扩展parfor使用256名工人:75.224557
总结
我们已经看到弱和强扩展之间的区别,并讨论了为什么我们宁愿看着弱扩展:它衡量我们的能力来解决更大的问题在集群上(更多的模拟,迭代,数据,等等)。大量的图表和详细的数量在这个例子也应该对这一事实的证明标准不能归结为一个数字或一个图。我们需要看整个画面理解应用程序的性能是否可以归因于应用程序,集群的硬件或软件,或两者的结合。
我们也看到,简称计算,parfor可以成为一个伟大的替代工作和任务。更多使用基准测试结果parfor,请参阅示例简单的基准测试PARFOR使用21点。
结束