流数据从硬件到软件
本实例介绍了一种利用SoC Blockset设计硬件逻辑(FPGA)与嵌入式处理器之间的数据路径的系统方法。应用程序通常被划分为硬件逻辑和片上系统(SoC)设备上的嵌入式处理器之间,以满足吞吐量、延迟和处理需求。您将设计和模拟整个应用程序,包括FPGA和处理器算法,内存接口和任务调度,以满足系统需求。然后,您将通过从模型生成代码并在SoC设备上实现来验证硬件上的设计。
金宝app支持硬件平台:
Xilinx®Zynq®ZC706评估试剂盒
Xilinx Zynq UltraScale™+ MPSoC ZCU102评估试剂盒
Xilinx Zynq UltraScale™+ RFSoC ZCU111评估试剂盒
Zynq-7000开发委员会
Altera®Cyclone®V SoC开发套件
Altera Arria®10 SoC开发套件
设计任务和系统需求
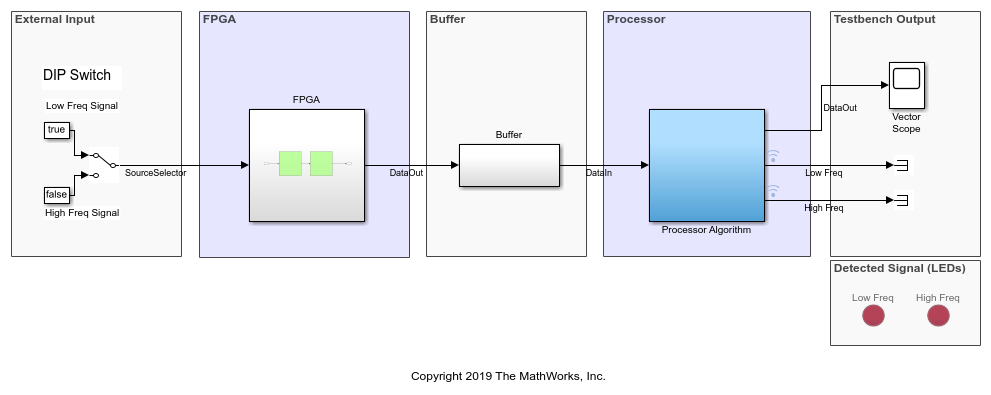
考虑一个在FPGA和嵌入式处理器上连续处理数据的应用程序。在这个例子中,FPGA算法过滤输入信号并将结果数据流送到处理器。在实现模型中soc_hwsw_stream_implementation,缓冲块表示从FPGA到处理器的数据传输。处理器对缓冲数据进行操作,并将数据分类为高频率或低频率处理器的算法子系统。FPGA根据拨码开关设置产生低频或高频正弦波的测试数据测试数据来源子系统。
应用程序的性能要求如下:
吞吐量:每秒10e6个样本
最大延迟:100 ms
丢弃的样本:< 1 / 10000
设计数据路径的挑战
FPGA处理一个样本一个样本的数据,同时处理器一次处理一帧数据。数据在FPGA和处理器之间异步传输,软件任务每次执行的时间可能不同。因此,FPGA和处理器之间需要一个队列来保存数据,以防止数据丢失。这个队列是在两个阶段实现的,一个作为FIFO的数据样本在FPGA内存和其他作为一系列帧缓冲区在外部内存。你需要设置三个与队列相关的参数:帧大小(数据帧中的样本数量),帧缓冲区的数量和FIFO大小(FIFO中样本突发的数量)。

这些设计参数会影响性能和资源利用率。增加帧大小可以让软件任务有更多的时间执行,并以增加延迟为代价满足吞吐量需求。通常,只有当你准备在硬件上实现时,你才能设置这些参数,这将带来以下挑战:
由于缺乏可见性,很难调试像在硬件中掉落样例这样的问题。
如果不首先评估硬件接口的效果,就很难有效地设计应用程序。它可能需要多次设计-实现迭代,因为您只能通过硬件上的实现来评估性能。
很难优化设计,因为很难通过实现确定性能和因果关系。
理想情况下,您希望在设计时开发应用程序时考虑到这些硬件影响,然后再在硬件上实现和运行。满足这些需求的一种方法是在设计时模拟硬件效果。如果可以模拟任务持续时间、内存缓冲区/ fifo利用率和外部内存传输延迟的变化,就可以评估它们对应用程序设计的影响,并在硬件上实现经过验证的设计。SoC Blockset允许您模拟这些效果,以便您可以在硬件上运行之前评估部署的应用程序的性能。
使用SoC模块集进行设计
创建一个SoC模型soc_hwsw_stream_top从实现模型soc_hwsw_stream_implementation使用流从FPGA到处理器模板.顶部型号包括FPGA型号soc_hwsw_stream_fpga和处理器模型soc_hwsw_stream_proc实例化为模型引用。该顶部模型还包括内存通道和内存控制器模块,该模块在FPGA和处理器之间共享外部内存。之前在实现模型中使用缓冲区块对它们进行了建模。为了提高仿真性能,对FPGA算法进行了基于帧的处理建模soc_hwsw_stream_fpga_frame并作为模型变型子系统包含在顶层。通过选择FPGA子系统的掩码,可以选择在基于帧或基于采样的处理中运行的模型。

设计以满足延迟需求: FPGA到处理器的数据路径的时延包括FPGA逻辑的时延和FPGA到处理器的数据通过内存通道传输的时间。在本例中,FPGA时钟为10MHz,延迟为纳秒量级。与内存通道内的延迟(以毫秒为量级)相比,这可以忽略不计。因此,让我们以以下方式来设计数据传输的延迟。
从一些可能的帧大小开始,计算表-1中每个帧大小的帧周期。帧周期是FPGA到处理器的两个连续帧之间的时间。对于本例,FPGA输出采样时间为10e-6,因为有效数据每100个时钟周期从FPGA输出一次。
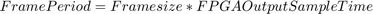
内存通道的延迟是由于帧缓冲区队列和FPGA FIFO中的采样所消耗的时间。让我们将FPGA FIFO的大小等效于一个帧缓冲区。为了保持在最大延迟要求,计算每个帧大小的帧缓冲区的数量,按照:
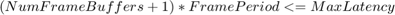
本示例允许的最大延迟是100毫秒。由于缓冲区的数量决定了最大延迟需求,所以对于表1中的所有情况,延迟需求都得到了满足。软件DMA驱动允许的最大帧缓冲区数是64。在外部存储器中至少需要3帧缓冲器来进行数据传输。其中一个帧缓冲区由FPGA写入,另一个帧缓冲区由处理器读取。因此,下表中的案例#8-10被拒绝,因为它们违反了最小缓冲区要求。

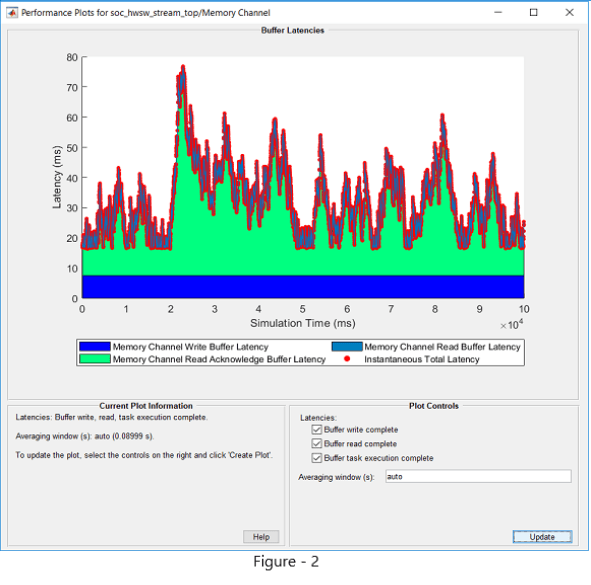
要可视化延迟,模拟模型并打开内存通道块,去性能选项卡,然后点击查看性能的情节.选择下面的所有延迟选项阴谋控制并点击创建图.如图- 2所示,您将注意到复合延迟满足< 100 ms的要求。
设计满足吞吐量要求:一般情况下,软件任务处理必须在一帧周期内完成,否则会导致任务超出,导致数据丢失,违反吞吐量要求。即。
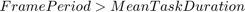
有各种方法可以获得与算法帧大小相对应的平均任务持续时间,这在后面会涉及到任务执行的例子。表2显示了不同帧大小下的平均任务持续时间。
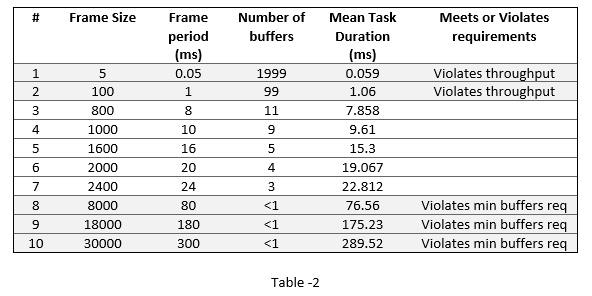
要用表中行(#2-#7)对应的参数来模拟模型,使用该函数set_hwsw_stream_set_parameters函数以行#作为参数。设置第2行模型参数如下:
soc_hwsw_stream_set_parameters (2);%行# 2
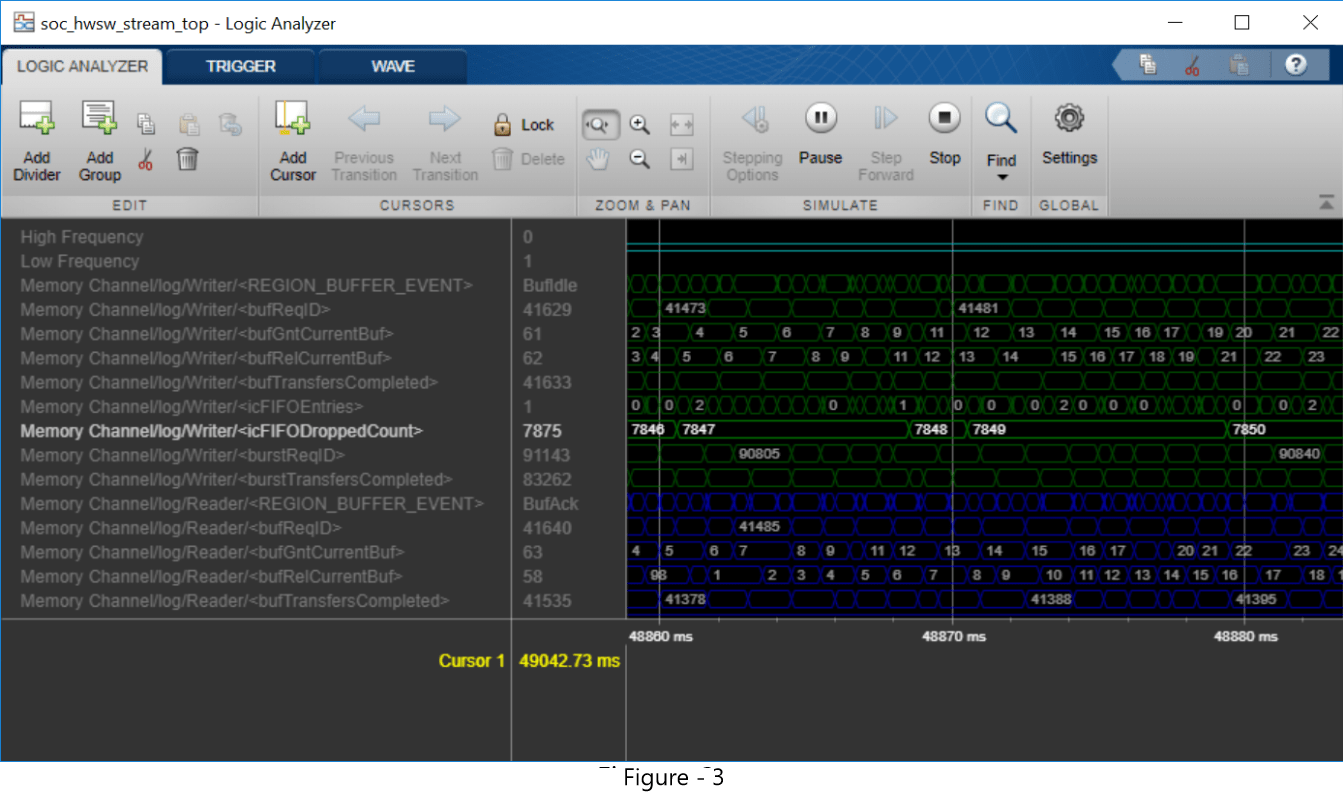
由于1.06 ms的Mean Task Duration大于1.0 ms的Frame Period,数据被丢弃在内存通道中。打开逻辑分析仪并注意那个信号icFIFODroppedCount在整个模拟过程中不断增加,如图3所示,这表明丢失数据的累积量。
由于数据在通过内存从FPGA传输到处理器的过程中被丢弃,这反映为吞吐量的下降。开放内存控制器块,去性能选项卡,然后点击图数据吞吐量按钮,查看内存吞吐量图,如图4所示。注意,吞吐量小于所需的0.4 MBps。由于FPGA输出数据采样时间为10e-6,每个采样宽为4字节,因此系统所需的流吞吐量为4字节/10e-6 = 400kbps。

设计满足下降样品的要求由于任务持续时间可能因许多原因而不同,比如不同的代码执行路径和操作系统切换时间的变化,数据有可能被丢到内存通道中。在“任务管理器”块的掩码中指定任务平均执行时间和任务持续时间的统计分布。大小先进先出相当于一个帧缓冲区。设置FIFO突发大小为16字节,并计算FIFO深度:

现在,为情况# 3-7模拟100秒的模型(10e6采样,每秒10e-6采样)。打开逻辑分析仪并记录在信号上的样品数量icFIFODroppedCount.
soc_hwsw_stream_set_parameters (3);%设置#3的模型参数
打开仿真数据检查器并添加来自内存通道的信号,如下图5所示。注意,作为缓冲区的使用(信号buffAvail)增加到最大11,FIFO的使用(信号isFIFOEntries开始增加。当FIFO完全被使用时,样本被丢弃(信号)isFIFODroppedCount)

所有情况#3-7的模拟结果以及每10000个样本的最终掉落结果如表3所示。
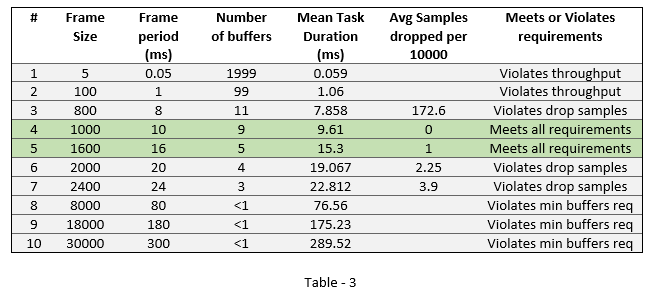
突出显示的条目(第4行和第5行)是有效的设计选择,因为它们满足吞吐量、延迟和drop样例需求。
硬件实现和运行
本节要求的产品如下:下载188bet金宝搏
高密度脂蛋白编码器™
嵌入式编码器®
用于Xilinx设备的So金宝appC Blockset支持包,或
用于英特尔设备的SoC B金宝applockset支持包
有关支持包的更多信息,请参见金宝appSoC Blockset支金宝app持的硬件
为了在一个受支持的SoC板上实现该模型,使用金宝appSoC建设者工具。打开“FPGA”子系统的掩码,选择型号变体为“基于样本的处理”。默认情况下,模型将在上面实现Xilinx®Zynq®ZC706评估试剂盒因为它配置了那个板。打开SoC建设者点击工具条中的“配置、构建和部署”按钮,并遵循以下步骤:
选择构建模型在设置屏幕上。点击下一个.
点击下一个在审查任务地图屏幕上。
点击查看/编辑内存映射查看上的内存映射检查内存映射屏幕上。点击下一个.
指定项目文件夹选择项目文件夹屏幕上。点击下一个.
选择构建、加载和运行在选择构建操作屏幕上。点击下一个.
点击验证检查用于实现的模型的兼容性验证模型屏幕上。点击下一个.
点击构建开始建立模型构建模型屏幕上。当FPGA合成开始时,外部外壳将打开。点击下一个.
点击测试连接在连接硬件屏幕测试主机与SoC板的连通性。点击下一个去运行应用程序屏幕上。
FPGA综合可能需要30分钟以上的时间。为了节省时间,你可以按照以下步骤使用预先生成的比特流:
关闭外壳以终止合成。
通过运行下面的命令将预生成的比特流复制到您的项目文件夹中,然后,
点击加载并运行按钮加载预生成的比特流并在SoC板上运行模型
拷贝文件(fullfile (matlabshared.sup金宝appportpkg.getSupportPackageRoot,“工具箱”,“soc”,...“金宝appsupportpackages”,“xilinxsoc”,“xilinxsocexamples”,“比特流”,...“soc_hwsw_stream_top-zc706.bit”),”。/ soc_prj ');
当应用程序在硬件上运行时,拨动板上的拨码开关,将测试数据从“低”频率更改为“高”频率,并注意板上相应的LED闪烁。您还可以读取在外部模式下运行的模型中的示例丢弃计数。因此,您需要验证SoC Blockset模型的实现是否匹配仿真并满足要求。
在其他委员会实施:若要在Xilinx®Zynq®ZC706评估板以外的其他单金宝app板上实现该型号,必须先将型号配置为支持的单板,并设置示例参数如下所示。
在硬件选项卡上,单击硬件设置打开配置参数窗口。
在硬件实现选项卡,选择您的板硬件板下拉列表在顶部和处理器模型。
导航到目标硬件资源>FPGA设计(顶级)选项卡并启用包括MATLAB作为AXI主IP用于基于主机的交互并设置IP核时钟频率(MHz)10 MHz。
导航到目标硬件资源>FPGA设计(调试)选项卡并启用包括AXI互连监视器.
接下来,打开SoC Builder,并遵循前面提到的Xilinx®Zynq®ZC706的步骤。修改拷贝文件命令匹配与您的板对应的位流。在Altera Arria®10 SoC开发套件和Altera Cyclone®V SoC开发套件的情况下使用如下拷贝文件命令对应您的板。对于Altera Arria®10 SoC开发套件,复制'.periph。rbf’和‘.core。rbf的文件。
拷贝文件(fullfile (matlabshared.sup金宝appportpkg.getSupportPackageRoot,“工具箱”,“soc”,...“金宝appsupportpackages”,“intelsoc”,“intelsocexamples”,“比特流”,...“soc_hwsw_stream_top-c5soc.rbf”),”。/ soc_prj ');
以下是可用的预生成的位流文件:
“soc_hwsw_stream_top-zc706.bit”
“soc_hwsw_stream_top-zedboard.bit”
“soc_hwsw_stream_top-zcu102.bit”
“soc_hwsw_stream_top-XilinxZynqUltraScale_RFSoCZCU111EvaluationKit.bit”
“soc_hwsw_stream_top-c5soc.rbf”
“soc_hwsw_stream_top-a10soc.periph.rbf”
“soc_hwsw_stream_top-a10soc.core.rbf”
总之,这个例子向你展示了一种使用SoC Blockset在硬件逻辑和嵌入式处理器之间设计数据路径的系统方法。您选择了帧大小、帧缓冲区数量、FIFO大小等设计参数,以满足吞吐量、时延和drop samples等系统性能要求。通过模拟和可视化这些参数对包含硬件逻辑、处理器算法、外部内存和处理器任务持续时间的完整模型的影响,可以发现在硬件上实现之前的吞吐量损失、延迟和样本丢失等问题。这个工作流确保设计在实现之前在硬件上工作,并避免长时间的设计-实现迭代。
你也可以从以下列表中选择一个网站: