canoncorr
典型相关
语法
[A, B] = canoncorr (X, Y)
(A、B r) = canoncorr (X, Y)
[A, B, r, U, V] = canoncorr (X, Y)
[A, B, r, U, V,统计]= canoncorr (X, Y)
描述
[A, B] = canoncorr (X, Y)的样本正则系数n——- - - - - -d1和n——- - - - - -d2数据矩阵X和Y。X和Y必须有相同数量的观察值(行),但可以有不同数量的变量(列)。一个和B是d1——- - - - - -d和d2——- - - - - -d矩阵,d = min(等级(X)等级(Y))。的jth的列一个和B包含正则系数,即的线性组合j第个正则变量X和Y,分别。列一个和B按比例缩放,使正则变量的协方差矩阵成为单位矩阵(见U和V下文)。如果X或Y小于满秩,canoncorr的行中返回零一个或B对应于的相关列X或Y。
(A、B r) = canoncorr (X, Y)也会返回一个1-by-d包含样本典型相关的向量。的jth元素r两者之间有关联吗jth的列U和V(见下文)。
[A, B, r, U, V] = canoncorr (X, Y)还返回规范变量scores。U和V是n——- - - - - -d矩阵计算,
U = (X-repmat(意味着(X), N, 1)) * V = (Y-repmat(意味着(Y), N, 1)) * B
[A, B, r, U, V,统计]= canoncorr (X, Y)也会返回一个结构统计数据包含与序列有关的信息d零假设
,那…k + 1)圣d这些相关性都是零k = 0 (d 1):。统计数据包含七个字段,每个字段一个1——- - - - - -d向量,其元素对应于的值k,如下表所述:
| 场 | 描述 |
|---|---|
威尔 |
Wilks' lambda(似然比)统计量 |
DF1 |
卡方统计量的自由度,分子自由度F统计 |
DF2 |
分母自由度F统计 |
F |
饶是近似的F统计的 |
pF |
右尾显著性水平为 |
chisq |
Bartlett近似卡方统计量 域名的修改 |
pChisq |
右尾显著性水平为 |
统计数据还有其他两个字段(教育部和p),它们等于DF1和pChisq,因为历史原因而存在。
例子
计算样本典型相关
加载示例数据。
负载carbig;X =[位移马力重量加速度MPG];nans = sum(isnan(X),2) > 0;
计算样本典型相关。
[A, B, r, U, V] = canoncorr (X (~ nan, 1:3), (~ nan, 4:5));
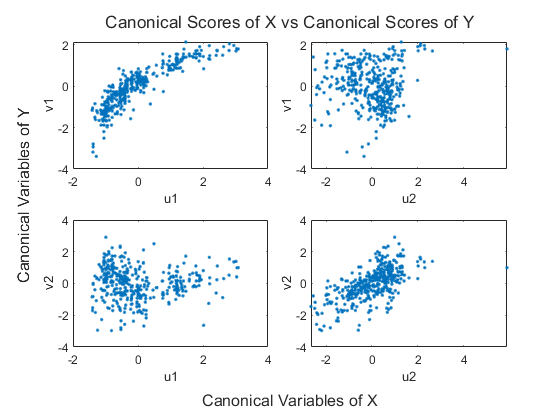
绘制典型变量得分。
情节(U (: 1), V (: 1),“。”)包含(“0.0025 * Disp + 0.020 *惠普- 0.000025 *重量的)ylabel (* accel - 0.092 * -0.17英里/加仑的)
参考
克扎诺夫斯基,w。多元分析原理:一个用户的视角。纽约:牛津大学出版社,1988年。
[2] Seber, g.a.f。多变量的观察。新泽西州霍博肯:约翰威利父子公司,1984年。
之前介绍过的R2006a
你也可以从以下列表中选择一个网站:
