CVPartition.
交叉验证的分区数据
描述
CVPartition.在数据集上定义随机分区。使用此分区定义使用交叉验证验证统计模型的培训和测试集。采用训练提取培训指数和测试提取用于交叉验证的测试指标。采用重新开始定义与给定相同类型的新随机分区CVPartition.目的。
创建
句法
描述
C= cvpartition(团体“KFold”,K.,'分层',stratifyOption.)CVPartition.目的C定义随机分区K.- 折扣交叉验证。如果您指定'stratify',假, 然后CVPartition.忽略课堂信息团体并创建一个非增长的随机分区。否则,函数默认实现分层。
C= cvpartition(团体“坚持”,P.,'分层',stratifyOption.)C它将随机分区定义为培训集和测试或熔断集。如果您指定'stratify',假, 然后CVPartition.创建一个非增长的随机分区。否则,函数默认实现分层。
输入参数
属性
例子
使用交叉验证错误估算分类新数据的准确性
使用交叉验证误分类误差来估计模型在新数据上的表现。
加载电离层数据集。创建包含预测器数据的表X和响应变量y.
加载电离层tbl = array2table(x);tbl.y = y;
使用随机的非分层分区HPartition.将数据分成训练数据(tbltrain)和保留的数据集(tblNew)。保留约30%的数据。
RNG('默认')重复性的%n =长度(tbl.y);hpartition = cvpartition(n,“坚持”,0.3);%不加以分区Idxtrain =培训(HPartition);tbltrain = tbl(idxtrain,:);Idxnew =测试(HPartition);tblnew = tbl(idxnew,:);
使用培训数据列车金宝app支持向量机(SVM)分类模型tbltrain.计算训练数据的错误分类错误和分类准确性。
mdl = fitcsvm(tbltrain,'是');TrainError = Resubloss(MDL)
TrainError = 0.0569
TrainAccuracy = 1-TrainError
TrainAccuracy = 0.9431.
通常,训练数据上的错误分类错误并不是估计模型如何在新数据上执行的估计,因为它可以低估在新数据上的错误分类率。更好的估计是交叉验证错误。
创建一个分区模型cvmdl..计算10倍交叉验证错误分类错误和分类准确性。默认情况下,横梁确保每个折叠中的类比例保持大致与响应变量中的类比例大致相同tblTrain。y.
cvmdl = crossval(mdl);%执行分层10倍交叉验证cvtrainError = kfoldLoss (cvMdl)
cvtrainError = 0.1220
cvtrainAccuracy = 1-CVtrainError
cvtrainAccuracy = 0.8780.
请注意,交叉验证错误cvtrainerror.是否大于再替换错误trainError.
将新数据分类tblNew使用训练有素的SVM模型。将新数据的分类准确性与准确率估算进行比较训练疗法和CVTrainAccuracy..
newerror =损失(mdl,tblnew,'是');newaccuracy = 1-newerror
NewAccuracy = 0.8700.
交叉验证误差会更好地估计新数据上的模型性能而不是重新提交错误。
使用K-Fold交叉验证发现误分类率
使用相同的分层分区进行5倍交叉验证,计算两个模型的误分类率。
加载渔民数据集。矩阵测定包含150种不同的花朵的花测量。变量物种列出每朵花的物种。
加载渔民
为分层5倍交叉验证创建一个随机分区。培训和测试集具有大约相同的花卉种类的比例物种.
RNG('默认')重复性的%c = cvpartition(物种,“KFold”5);
利用该方法建立分区判别分析模型和分区分类树模型C.
discrCVModel = fitcdiscr(量、种类、'cvpartition',C);treecvmodel = fitctree(meas,speies,'cvpartition',C);
计算两种划分模型的误分类率。
discrRate = kfoldLoss (discrCVModel)
差异= 0.0200.
treeRate = kfoldLoss (treeCVModel)
trestate = 0.0333.
判别分析模型具有较小的交叉验证错误分类率。
创建非增长的分区
在5倍的非增长分区中观察测试集(折叠)类比例渔民数据。各层的比例各不相同。
加载渔民数据集。这物种变量包含每个花(观察)的种名(类)。转换物种到A.分类变量。
加载渔民物种=分类(物种);
找到每个班级的观测数量。请注意,三个类别以平等的比例发生。
C =类别(物种)%类名称
C =3x1细胞{'setosa'} {'versicolor'} {'virginica'}
numClasses =大小(C, 1);n = countcats(物种)每个班级的观察数
n =3×150 50 50
创建一个随机的非分层的5层分区。
RNG('默认')重复性的%cv = cvpartition(物种,“KFold”,5,“分层”,错误的)
CV = k折叠交叉验证分区NumObServations:150 NumTestSets:5列塔:120 120 120 120测试:30 30 30 30 30 30
表明,三个类别在五个测试集中的每一个或折叠中的每一个中都不发生。使用for-循环更新ntestdata.矩阵让每个条目ntestdata(I,J)对应于测试集中的观测数量一世和班级C(j).从数据中创建条形图ntestdata..
numfolds = cv.numtestsets;ntestdata =零(numfolds,numcrasses);为了i = 1:numfolds testclasses =物种(cv.test(i));ncounts = countcats(testcrasses);每个类中的测试集合观测值ntestdata(我,:) = ncounts';结尾酒吧(ntestdata)xlabel('测试集(折叠)')ylabel('观察数') 标题('无刺激的分区')传奇(c)
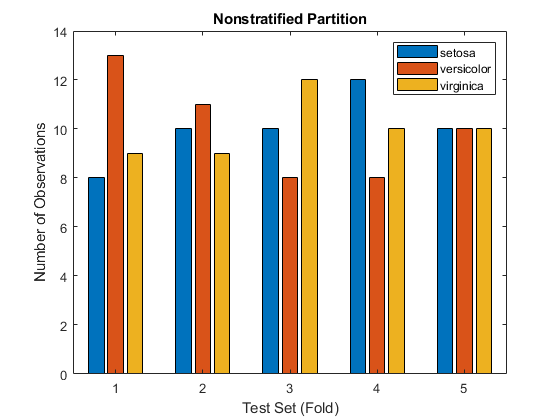
注意,在一些测试集中,类的比例是不同的。例如,第一个测试集包含8朵蔷薇花、13朵花斑和9朵virginica花,而不是每个物种10朵。因为简历是一种随机的不增长的分区渔民数据,每个测试集(折叠)中的类比例不能保证等于类比例物种.也就是说,类在每个测试集中的出现并不总是相同的,就像它们在物种.
为高阵列创建非增值和分层熔断分区
为高数组创建一个非分层抵抗分区和一个分层抵抗分区。对于两组坚持者,比较每一类的观察次数。
在高阵列上执行计算时,MATLAB®使用并行池(如果您有并行计算工具箱™)或本地MATLAB会话。要使用Parallated Computing Toolbox使用本地MATLAB会话运行示例,请使用“使用”控件“工具箱”来更改“全局执行环境”mapreduce功能。
Mapreducer(0)
创建一个数字矢量的两个类,其中类1和班级2发生在比率中1:10.
Group = [α(20,1); 2 *(200,1)]
组=220×11 1 1 1 1 1 1 1 1⋮
从中创建一个高大的数组团体.
tgroup = tall(group)
TGroup = 220x1高级双列向量1 1 1 1 1 1 1 1::
坚持是唯一的CVPartition.高大阵列支持的选项。金宝app创建随机的非增强的熔断分区。
cv0 = cvpartition(tgroup,“坚持”,1/4,“分层”,错误的)
CV0 =保持交叉验证分区NumObServation:[1x1高] NumTestSets:1列车:[1x1高]测试:[1x1高]
返回结果cv0.test.通过使用收集功能。
testidx0 =收集(cv0.test);
使用本地MATLAB会话评估高表达: - 通过1的1:0.49秒的评估完成为0.66秒
查找测试中每个类发生的次数,或持有,设置。
Accularray(组(testidx0),1)% holdout集合中每个类的观察数
ans =.2×15 51
CVPartition.在结果中产生随机性,所以你在每个类中的观察数可能与显示的不同。
因为CV0是一个不增种的分区,课程1观察和课堂2熔断集中的观察不保证以与相同的比例发生TGROUP..但是,由于内在的随机性CVPartition.,有时可以获得一个熔断集,其中类以与相同的比率发生TGROUP.,即使你指定'stratify',假.因为训练集是守恒集的补充,所以不包括任何南或缺少观察,您可以获得培训集的类似结果。
返回结果cv0.tring.记忆。
trainidx0 =聚集(cv0.training);
using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.18 sec
找出每个类在训练集中出现的次数。
Accularray(Group(TrainIDX0),1)培训集中每节课的观察数
ans =.2×115 149.
非分层训练集中的类不能保证以相同的比例出现TGROUP..
创建一个随机分层的阻止分区。
cv1 = cvpartition(tgroup,“坚持”,1/4)
nummobservations: [1x1 tall] NumTestSets: 1 TrainSize: [1x1 tall] TestSize: [1x1 tall]
返回结果cv1.test.记忆。
testidx1 =收集(cv1.test);
使用本地MATLAB会话评估高表达: - 通过1的第1条:0.11秒评估完成0.15秒
查找测试中每个类发生的次数,或持有,设置。
Accularray(组(TestidX1),1)% holdout集合中每个类的观察数
ans =.2×15 51
在分层熔断分区的情况下,HoldOut集中的类比和类比例TGROUP.是相同的(1:10).
使用休假分区找到有影响力的观察
创建一个随机分区的休假交叉验证。计算和比较培训集手段。重复具有显着不同的平均值表明存在影响的观察。
创建数据集X包含一个比其他值要大得多的值。
x = [1 2 3 4 5 6 7 8 9 20]'
创建一个CVPartition.对象有10次观察和10次重复的训练和测试数据。对于每一个重复,CVPartition.选择一个观察,以从训练集中删除并为测试集保留。
c = cvpartition(10,'忽略')
C =休留一张交叉验证分区NumObServation:10 NumTestSets:10列车:9 9 9 9 9 9 9 9 9 9 Testsize:1 1 1 1 1 1 1 1 1 1 1
将休假次分区应用于X,并采用每次重复的培训观测的平均值横梁.
值= crossval (@ (Xtrain Xtest)意味着(Xtrain), X,“分区”,C)
值=10×16.5556 6.4444 7.0000 6.3333 6.6667 7.1111 6.8889 6.7778 6.2222 5.0000
查看培训集意味着使用框图(或框图)。绘图显示一个异常值。
boxchart(值)
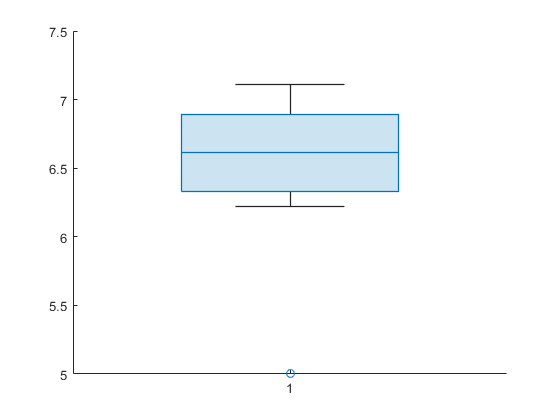
找出与离群值对应的重复值。对于这个重复,在测试集中找到观察值。
[〜,repetitiondidx] = min(值)
RepetitionDX = 10.
observationIdx =测试(c, repetitionIdx);influentialObservation = X (observationIdx)
富有影响力= 20.
包含观察的训练集具有培训集的平均值的基本不同的方法,而无需观察。这种显着的变化表明了价值20.在X是一种有影响力的观察。
提示
如果您指定
团体作为第一个输入参数CVPartition.,然后函数丢弃对应于缺失值的观测行团体.如果您指定
团体作为第一个输入参数CVPartition.,然后默认情况下函数实现分层。您可以指定'stratify',假创建非增长的随机分区。您可以指定
'stratify',真实只有当第一个输入参数CVPartition.是团体.
扩展功能
您还可以从以下列表中选择一个网站:
