可视化多元数据
这个例子说明了如何使用各种统计图可视化多变量数据。许多统计分析只涉及两个变量:一个预测变量和因变量。这样的数据很容易使用二维散点图,二元直方图,箱图等,这也是可能的可视化的三维散点图,或2D散点图三变量数据与编码的第三可变,例如彩色可视化。然而,许多数据集涉及的变量数量较多,使直接可视化更加困难。这个例子探讨了一些可视化的MATLAB®高维数据,使用统计和机器学习工具箱™的方式。
在这个例子中,我们将使用carbig数据集,其中包含约400个从1970年的汽车和1980年的各种测量变量的数据集。我们将使用值的燃料效率(在每加仑英里,MPG),加速度(从时间0-60MPH在秒),发动机排量(以立方英寸),重量,和马力说明多元可视化。我们将使用的气缸数量,以组的意见。
加载carbigX = [MPG,加速度,位移,重量,马力];varNames = {'MPG';“加速”;'移位';'重量';'马力'};
散点图矩阵
通过低维子空间查看切片是部分地解决两个或三个维度的限制的一种方法。例如,我们可以使用gplotmatrix函数来显示所有二元散点图的阵列提供五个变量之间,其中每个变量单变量直方图沿。
图gplotmatrix(X,[],缸,['C''B''M''G''R'],[],[],假);文本(,repmat([08 0.24 0.43 0.66 0.83。] - 1,1,5-),varNames,'字体大小',8);文本(repmat( - 12,1,5),[0.86 0.62 0.41 0.25 0.02],varNames,'字体大小'8,'回转',90);

在每个散布图中的点是通过气缸的数量颜色编码:蓝色为4个气缸,绿色为6,和红色8.还有5台筒车屈指可数,和旋转引擎的汽车被列为具有3缸。地块的这种阵列可以很容易地挑选出图案对变量之间的关系。然而,有可能在更高维度的重要方式,而这些都不是容易在此图来识别。
平行坐标地块
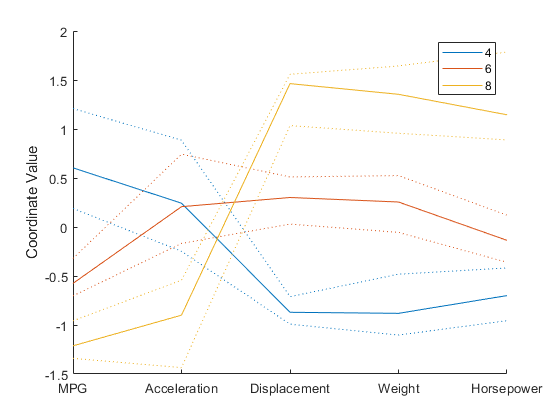
散点图矩阵只显示二元关系。然而,也有显示所有的变量一起其他替代方案,让您调查变量之间的高维的关系。最直接的多元情节是平行坐标图。在该图中,坐标轴都水平排列,而是采用正交轴作为在通常的笛卡尔图。每个观测在情节作为一系列相连的线段代表。例如,我们可以把所有的汽车的曲线与4,6或8缸,并通过组颜色的观察。
Cyl468 = ismember(缸,[4 6 8]);parallelcoords(X(Cyl468,:),'组',圆柱体(Cyl468),...“规范”,'上','标签',varNames)

在该图中,水平方向表示的坐标轴,并且垂直方向表示的数据。每个观测包括五个变量的测量,并且每次测量被表示为在其相应的线横穿各坐标轴的高度。由于五个变量具有广泛不同的范围,该曲线用标准化的值,其中,每个变量已经被标准化为具有零均值和单位方差制成。与彩色编码,该图所示,例如,8辆汽缸汽车通常具有用于位移,重量和马力MPG和加速度,以及高的值低的值。
即使有颜色由组编码,一个平行坐标曲线图具有大量观测可能难以读出。我们也可以做一个平行坐标图,其中仅中位数和每个组四分位数(25%和75%分)所示。这使得各组间典型的异同比较容易区分。在另一方面,它可能是每个组最感兴趣的异常值,而这个情节完全不显示它们。
parallelcoords(X(Cyl468,:),'组',圆柱体(Cyl468),...“规范”,'上','标签',varNames,“位数”,0.25)
安卓地块
另一个类似的类型多元可视化的是安卓的情节。该曲线图表示各观察为在区间[0,1]的平滑函数。
andrewsplot(X(Cyl468,:),'组',圆柱体(Cyl468),“规范”,'上')

每个函数是一个傅里叶级数,具有系数等于相应观测的值。在这个例子中,该系列具有五个方面:一个常数,与周期1和1/2 2个正弦项,并且两个相似的余弦项。由于三个主要方面影响的功能的形状在一个安德鲁斯情节最明显的,所以在第一三个变量模式往往是最容易识别的那些。
有在t = 0基团之间存在明显的差异,表明第一可变,MPG,是4,6,和8汽缸轿厢之间的显着特征之一。更有趣的是在大约t = 1/3,三组之间的差异。堵这个值代入公式为安卓积函数,我们得到一组系数的定义变量的线性组合,群体之间的区分。
T1 = 1/3;[1 / SQRT(2)SIN(2 * PI * T1)COS(2 * PI * T1)SIN(4 * PI * T1)COS(4 * PI * T1)]
ANS = 0.7071 0.8660 -0.5000 -0.8660 -0.5000
从这些系数中,我们可以看到,一个办法从8辆气缸汽车区分4辆气缸汽车在于前者有MPG和加速度和位移,马力,并且特别重量的较低值的较高的值,而后者则具有相反的。这是我们从平行坐标情节引起了同样的结论。
地块雕文
可视化多元数据的另一种方法是使用“字形”来表示的尺寸。功能glyphplot金宝app支持两种类型的字形:明星,切尔诺夫脸。例如,这里是在汽车数据前9种机型的明星地块。在星形每个辐条表示一个可变的,并且所述辐条长度正比于该变量为观测值。
H = glyphplot(X(1:9,:),“字形”,'星','varLabels',varNames,'obslabels',模型(1:9,:));组(H(:,3),'字体大小',8);

在现场MATLAB数字窗口,该地块将允许数据值的互动探索,利用数据游标。例如,点击星福特都灵的右手点,则表明它具有17的MPG值。
雕文地块和多维尺度
在网格上绘制的星星,没有特定的顺序,可能会导致被迷惑的人物,因为邻近的恒星最终会完全不同的外观。因此,可以存在用于眼睛捕捉没有平滑图案。这往往是有用的多维尺度(MDS)与字形情节结合起来。为了说明这一点,我们将首先从1977年选择所有的汽车,并使用zscore功能规范这五个变量具有零均值和单位方差。然后,我们会计算这些规范性意见相异的措施之间的欧氏距离。这种选择可能是在实际应用中过于简单化,但在这里提供用于说明目的。
models77 =查找((Model_Year == 77));相异度= pdist(zscore(X(models77,:)));
最后,我们使用mdscale以在两个维度上其INTERPOINT距离近似原始高维数据中的不同点创建一组位置,并绘制使用这些位置的字形。在这个二维图中的距离可能只能大致再现数据,但对于这种类型的情节,这是不够好。
Y = mdscale(相异,2);glyphplot(X(models77,:),“字形”,'星',“中心”,Y,...'varLabels',varNames,'obslabels',模型(models77,:),'半径',0.5);标题(“1977年车型年”);

在该图中,我们使用MDS作为降维方法,来创建一个2D绘图。通常情况下,这将意味着信息的损失,但通过绘制字形,我们已经将所有的数据高维信息。采用MDS的目的是要征收一定的规律性,以在数据的变化,从而使字形中模式是比较容易看到。
正如前面的剧情,互动的探索将在现场图窗口是可能的。
字形的另一种类型是脸部切尔诺夫。此字形编码数据值对于每个观测到面部特征,诸如脸部的尺寸,面的形状,眼睛的位置等
glyphplot(X(models77,:),“字形”,'面对',“中心”,Y,...'varLabels',varNames,'obslabels',模型(models77,:));标题(“1977年车型年”);
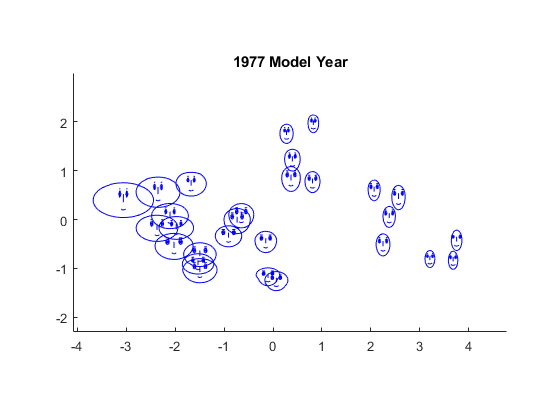
这里,两个最明显的特征,面部尺寸和相对前额/颚大小,编码MPG和加速度,而额头和颚形状编码位移和重量。眼睛编码马力之间的宽度。这是值得注意的是,有几面具有广泛的前额和窄钳口,或反之亦然,指示变量的位移和重量之间的正线性相关。这也是我们在散点图矩阵看见。
的特征变量对应确定哪些关系是最容易看到的,和glyphplot允许选择被轻易改变。
关
您还可以选择从下面的列表中的网站:
