拟合定制单变量分布,第2部分
这个例子展示了如何使用Statistics和Machine Learning Toolbox™函数来使用一些更高级的技术大中型企业使自定义分布适合于单变量数据。这些技术包括对截尾数据拟合模型,以及用自定义分布拟合一些数值细节的说明。
看到拟合自定义单变量分布有关拟合自定义分布到单变量数据的其他示例。
用截尾数数据拟合自定义分布
极值分布通常用于模拟机械部件的故障时间,并且在这种情况下实验仅用于固定的时间长度。如果不是所有实验单元在该时间内都失败,则数据是右缩放的,即,某些故障时间的值尚未完全清楚,但只知道大于某个值。
统计和机器学习工具箱包括这个功能evfit,拟合数据的极值分布,包括有审查的数据。然而,出于本例的目的,我们将忽略evfit,并演示如何使用大中型企业并利用极值分布自定义分布拟合截尾数据模型。
因为缩短的数据的值尚不完全,所以最大似然估计变得更加困难。特别地,需要PDF和CDF来计算日志似然性。因此,您必须提供大中型企业这两个函数都可以用来拟合经过审查的数据。统计和机器学习工具箱包括这些功能evpdf和evcdf因此,对于这个例子,已经完成了编写代码的工作。
我们将使这个模型与模拟数据相符。第一步是生成一些未经审查的极值数据。
rng (0,“旋风”);n = 50;μ= 5;σ= 2.5;x = evrnd(μ、σ,n, 1);
接下来,通过用截止值替换这些值来审查大于预定截止的任何值。这称为II型审查,并且在7时截止,约12%的原始数据最终被审查。
C = (x > 7);x (c) = 7;和(c) / (c)长度
ans = 0.1200
我们可以绘制出这些数据的直方图,其中包括一个堆叠的条形图来代表被删的观测结果。
[undenscnts,bciturers] = hist(x(〜c));CENSCNTS = HIST(x(c),bcitionrs);酒吧(鸡肉,[undenscnts'censcnts'],“堆叠”);
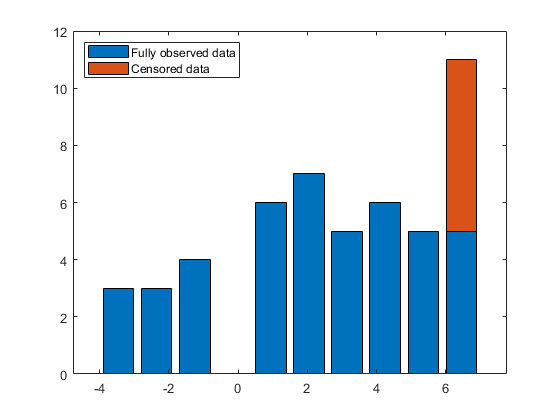
虽然存在截尾现象,但截尾观测值的比例较小,因此矩量法可以为参数估计提供一个合理的起点。我们计算mu和sigma的值,对应于观测的平均值和未删失数据的标准偏差。
sigma0 = sqrt(6) *性病(x (~ c)) /π
Sigma0 = 2.3495.
mu0 =意味着(x ~ (c))ψ(1)* sigma0
mu0 = 3.5629
除了将数据、x和句柄传递给PDF和CDF函数大中型企业,我们也使用‘截尾’参数来通过截尾向量c。因为尺度参数σ必须是正的,所以我们指定了参数的下界。大中型企业返回两个极值分布参数mu和sigma的最大似然估计,以及近似的95%置信区间。
[paramEsts, paramCIs] =大中型企业(x,“审查”c“pdf”@evpdf,“提供”@evcdf,...“开始”, (mu0 sigma0),'降低',[ - inf,0])
paramests =1×24.5530 - 3.0215
paramCIs =2×23.6455 2.2937 5.4605 3.7494
自定义分布拟合中的若干数值问题
拟合自定义分发需要对参数进行初始猜测,并且通常很难知道起点是多么好的或坏的。在前面的示例中,如果我们选择了远离最大可能性估计的起点,则一些观察可能在与起点相对应的极值分布的尾部非常远。那么两件事中的一个可能发生。
首先,一个PDF值可能变得非常小,以至于在双精度运算中溢出为零。其次,其中一个CDF值可能已经变得非常接近1,以至于它以双精度四舍五入。(也有可能是CDF值太小而导致下溢,但事实证明这不是问题。)
这两种情况都会导致问题大中型企业计算对数似然值,因为它们会得到-Inf的对数似然值,而在大中型企业通常不可能走出这些地区。
知道了最大似然估计是什么,让我们看看不同的起点会发生什么。
Start = [1 1];尝试[paramEsts, paramCIs] =大中型企业(x,“审查”c“pdf”@evpdf,“提供”@evcdf,...“开始”开始,'降低',[ - inf,0])抓我disp (ME.message)结束
CDF函数返回大于或等于1的值。
在这种情况下,出现了第二个问题:初始参数猜测处的一些CDF值被精确地计算为1,因此对数似然是无限的。我们可以尝试设置大中型企业'的'FunValCheck'控制参数为'off',这将禁用对非有限似然值的检查,然后希望得到最好的结果。但是解决这个数值问题的正确方法是在它的根上,在这种情况下不难做。
请注意,极值CDF是表单
P = 1 -exp(-exp((x-mu)./sigma))
截尾观测值对对数似然的贡献是生存函数(SF)值的对数,即log(1-CDF)。对于极值分布,SF的对数就是-exp((x)./sigma)。如果我们可以直接使用logSF来计算log的可能性,而不是实际上计算log(1 - (1-exp(logSF))))),我们就可以避免CDF的舍入问题。这是因为CDF值在双精度上与1不可区分的观测值具有对数SF值,这些值仍然很容易表示为非零值。例如,CDF值(1 - 1e-20)在双精度中为1,因为双精度每股收益大约是2e-16。
SFval = 1 e-20;CDFval = 1 - SFval
CDFval = 1
但是,对应SF值的对数,即log(1-CDF),很容易表示。
日志(sfval)
ans = -46.0517.
使用日志PDF而不是PDF本身也可以得到类似的观察结果——未经审查的观察结果对对数可能性的贡献是它们的PDF值的对数。直接使用日志PDF(而不是,实际上,计算日志(exp(logPDF)))可以避免底流问题,在这种情况下,PDF在双精度方面无法与零区分,但日志PDF仍然可以很容易地表示为一个有限的负数。例如,PDF值1e-400以双精度表示,因为双精度逼真大约是2 e - 308。
logPDFval = -921;PDFval = exp (logPDFval)
PDFval = 0
大中型企业通过'logpdf'和'logsf'参数,提供使用日志PDF和日志SF(而不是PDF和CDF)指定定制发行版的语法。不像PDF和CDF函数,没有现有的函数,所以我们将创建匿名函数来计算这些值:
Evlogpdf = @(x,mu,sigma)((x - mu)./ sigma - exp((x - mu)./ sigma)) - log(sigma);Evlogsf = @(x,mu,sigma)-exp((x-mu)./ sigma);
使用相同的起始点,极值分布的备用LogPDF / logsf规范使得解决问题可以解决:
Start = [1 1];[paramEsts, paramCIs] =大中型企业(x,“审查”c“logpdf”,Evlogpdf,“logsf”evlogsf,...“开始”开始,'降低',[ - inf,0])
paramests =1×24.5530 - 3.0215
paramCIs =2×23.6455 2.2937 5.4605 3.7494
但是,这种策略不能总是减少一个糟糕的起点,并且始终建议仔细选择起点。
提供一个梯度
默认情况下,大中型企业使用该功能fminsearch找到最大化数据的日志可能性的参数值。fminsearch使用无导数的优化算法,这通常是一个不错的选择。
然而,对于一些问题,选择一个使用对数似然函数导数的优化算法可能会决定是否收敛于最大似然估计,特别是当起点离最终答案很远的时候。提供衍生品有时也能加快收敛速度。
如果您的Matlab®安装包括优化工具箱™,大中型企业允许您使用该函数fmincon,其中包括可以使用衍生信息的优化算法。来最大限度地利用fmincon,您可以使用日志似然函数指定自定义分发,写入返回返回日志似然本身,但其渐变也是如此。日志似然函数的梯度仅仅是其偏衍生物的矢量相对于其参数。
这种策略需要额外的准备工作,需要编写代码来计算对数似然及其梯度。对于本例,我们已经创建了代码,将极值分布作为一个单独的文件来执行该操作evnegloglike.m.
类型evnegloglike.m
function [nll,ngrad] = evnegloglike(params,x,cens,freq) % evnegloglike极值分布的负对数似然。% Copyright 1984-2004 The MathWorks, Inc. if numel(params)~=2 error(message('stats:probdists:WrongParameterLength',2));End mu = params(1);σ= params (2);nunc =总和(1-cens);Z = (x -) /;expz = exp (z);NLL = sum(expz) - sum(z(~cens)) + NLL .*log(sigma);如果nargout > 1 ngrad =[总和(expz)。/σ+ nunc。/σ,……总和(z。* expz)。/sigma + sum(z(~cens))./sigma + nunc./sigma]; end
注意这个函数evnegloglike.返回负逻辑似然值和梯度值,因为mle最小化负对数似。
为了使用基于梯度的优化算法计算最大似然估计,我们使用“nloglf”参数,指定我们正在为计算负对数可能性的函数提供句柄,以及“optimfun”参数,指定fmincon作为优化功能。大中型企业会自动检测到evnegloglike.可以返回负对数似然及其梯度。
Start = [1 1];[paramEsts, paramCIs] =大中型企业(x,“审查”c“nloglf”,@ evnegloglike,...“开始”开始,'降低',[ - inf,0],“optimfun”,'粉丝')
paramests =1×24.5530 - 3.0215
paramCIs =2×23.6455 2.2937 5.4605 3.7493
您还可以从以下列表中选择一个网站:
