广义线性模型工作流
这个例子说明了如何拟合一个广义线性模型并分析结果。典型的工作流包括导入数据、拟合广义线性模型、测试模型质量、修改模型以提高模型质量以及基于模型进行预测等步骤。在这个例子中,您使用Fisher虹膜数据来计算花在两个类之一中的概率。
加载数据
载入费雪虹膜数据。
负载fisheriris
提取的行51至150,其具有的分类云芝或弗吉尼亚。
X =量(51:最终,);
创建逻辑响应变量真的杂色的,假virginica。
y = strcmp (“花斑癣”、物种(51:结束));
拟合广义线性模型
适合于该数据的二项式广义线性模型。
mdl = fitglm (X, y,“线性”,“分布”,“二项式”)
MDL =广义线性回归模型:分对数(y)的〜1 + X1 + X2 + X3 + X4分布=二项式估计系数:估计SE TSTAT p值________ ______ _______ ________(截距)42.638 25.708 1.6586 0.097204 X1 2.4652 2.3943 1.0296 0.30319×2 6.6809 4.47961.4914 0.13585×3 -9.4294 4.7372 -1.9905 0.046537×4 -18.286 9.7426 -1.8769 0.060529 100观察,95个错误自由度分散体:1驰^ 2统计量与常数模型:127,p值= 1.95e-26
根据模型显示,有些p在 - 值pValue列并不小,这意味着您可以简化模型。
检验和改进模型
确定是否为系数95%置信区间包括0。如果是这样,你可以用这些时间间隔删除模型项。
confint = coefCI(MDL)
confint =5×2-8.3984 93.6740 -2.2881 7.2185 -2.2122 15.5739 -18.8339 -0.0248 -37.6277 1.0554
只有第四个预测者x3具有置信区间不包含0的系数。
的系数x1和x2具有大p-值及其95%置信区间包括0。测试两个系数是否都为零。指定一个假设矩阵来选择的系数x1和x2.
M = [0 1 0 0 0 0];p = coefTest (mdl)
p值= 0.1442
的p-value大约是0.14,这个值不小。删除x1和x2从模型。
mdl1 = removeTerms (mdl,“x1 + x2”)
mdl1 =广义线性回归模型:分对数(y)的〜1个+ X3 + X4分布=二项式估计系数:估计SE TSTAT p值________ ______ _______ __________(截距)45.272 13.612 3.326 0.00088103×3 -5.7545 2.3059 -2.4956 0.012576 X4 -10.447 3.7557 -2.7816 0.0054092 100观察,97个错误自由度分散体:1驰^ 2统计量与常数模型:118,p值= 2.3E-26
另外,您也可以使用识别重要的预测stepwiseglm.
MDL2 = stepwiseglm(X,Y,“不变”,“分布”,“二项式”,“上”,“线性”)
1.加x4, Deviance = 33.4208, Chi2Stat = 105.2086, PValue = 1.099298e-24加上x3, Deviance = 20.5635, Chi2Stat = 12.8573, PValue = 0.000336166加上x2, Deviance = 13.2658, Chi2Stat = 7.29767, PValue = 0.00690441
mdl2 =广义线性回归模型:logit(y) ~ 1 + x2 + x3 + x4估计SE tStat pValue ________ ______ _______ ________ (Intercept) 50.527 23.995 2.1057 0.035227 x2 8.3761 4.7612 1.7592 0.078536 x3 -7.8745 3.8407 -2.0503 0.040334 x4 -21.43 10.707 -2.0014 0.04535 100个观测值,96个误差自由度
的p值(pValue)x2在系数表中大于0.05,但是stepwiseglm包括x2在模型中,因为p值(PValue)添加x2小于0.05。的stepwiseglm函数计算PValue使用适合的和没有x2,而函数计算pValue仅基于从最终模型计算的近似标准误差。所以,PValue比更可靠pValue.
识别离群值
检查杠杆情节寻找有影响力的异常值。
plotDiagnostics(MDL2,'杠杆作用')
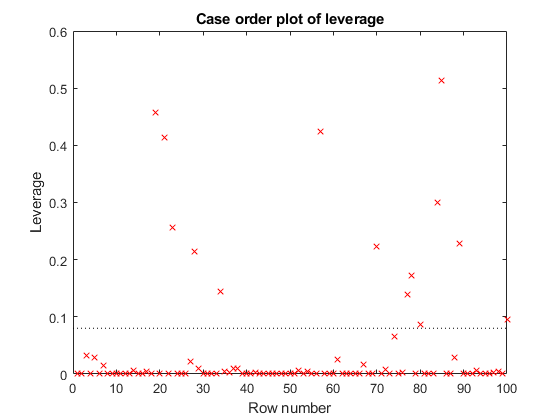
如果其杠杆实质上超过的观察可以被认为是异常值p / n,在那里p系数的个数是和吗n是观测值的数量。虚线参考线是一个推荐的阈值时,通过计算2 * P / N,这对应于0.08这个情节。有些观测杠杆值大于10 * p / n(即0.40)。确定这些观察点。
idxOutliers =找到(mdl2.Diagnostics。利用> 10 * mdl2.NumCoefficients / mdl2.NumObservations)
idxOutliers =4×119 21 57 85
当你适合排除这些点的模型看看模型系数发生改变。
oldCoeffs = mdl2.Coefficients.Estimate;mdl3 = fitglm(X,Y,“线性”,“分布”,“二项式”,...“PredictorVars”2:4,'排除', idxOutliers);newCoeffs = mdl3.Coefficients.Estimate;disp ([oldCoeffs newCoeffs])
50.5268 44.0085 8.3761 5.6361 -7.8745 -6.1145 -21.4296 -18.1236
在该模型的系数mdl3与那些在MDL2不同。这一结果意味着,在高杠杆点的反应是不与简化模型的预测值一致。
预测花斑的概率
用mdl3用平均尺寸来预测一朵花是花斑的概率。生成预测的置信区间。
[newf, newc] =预测(mdl3,意味着(X))
newf = 0.4558
NEWC =1×20.1234 - 0.8329
该模型给出了几乎46%的概率,平均花是云芝,具有广泛的置信区间。
另请参阅
fitglm|stepwiseglm|GeneralizedLinearModel|预测|removeTerms|coefCI|plotDiagnostics
相关话题
您还可以从以下列表中选择一个网站:
