iforest
适合隔离森林异常检测
语法
描述
使用iforest函数以适应一个与世隔绝的森林异常值检测和新奇检测模型。
异常值检测(检测异常的训练数据)——使用输出参数
特遣部队的iforest在训练数据异常识别。新奇检测(检测异常在新数据与未被污染的训练数据),创建一个
IsolationForest对象通过未被污染的训练数据(数据没有异常值)iforest。检测异常新数据通过对象和新的数据对象的功能isanomaly。
森林= iforest (资源描述)IsolationForest为预测表中的数据对象资源描述。
森林= iforest (___,名称=值)ContaminationFraction= 0.1
例子
检测异常值
检测异常值(在训练数据异常)使用iforest函数。
加载示例数据集NYCHousing2015。
负载NYCHousing2015
数据集包括10变量信息属性的销售在2015年在纽约。显示一个总结的数据集。
总结(NYCHousing2015)
变量:区:91446 x1双重价值:1分钟3马克斯5社区中位数:91446 x1单元阵列的特征向量BUILDINGCLASSCATEGORY: 91446 x1单元阵列的特征向量RESIDENTIALUNITS: 91446 x1双重价值:最小值0 8759 Max COMMERCIALUNITS中位数:91446 x1双重价值:最小值0最大612 LANDSQUAREFEET: 91446 x1双重价值:最小值0 1700 Max 2.9306 e + 07 GROSSSQUAREFEET中位数:91446 x1双重价值:最小值0 1056 Max 8.9422 e + 06 YEARBUILT中位数:91446 x1双重价值:最小值0 1939 Max 2016 SALEPRICE中位数:91446 x1双重价值:最小0值3.3333 e + 05年最大4.1111 e + 09 SALEDATE: x1 datetime值:91446分钟01 - 2015年1月- 2015位数09年7月- Max 31 - 12月- 2015
的SALEDATE列是datetime数组,这是不支持的金宝appiforest。创建列的月和日数据datetime值,删除SALEDATE列。
[~,NYCHousing2015.MM NYCHousing2015。DD] = ymd (NYCHousing2015.SALEDATE);NYCHousing2015。SALEDATE = [];
列区,社区,BUILDINGCLASSCATEGORY包含分类预测。显示类别的分类预测的数量。
长度(独特(NYCHousing2015.BOROUGH))
ans = 5
长度(独特(NYCHousing2015.NEIGHBORHOOD))
ans = 254
长度(独特(NYCHousing2015.BUILDINGCLASSCATEGORY))
ans = 48
与64多个类别,类别变量iforest函数使用一个近似分割方法,该方法可以减少隔离森林模型的准确性。删除社区列,其中包含254个类别的类别变量。
NYCHousing2015。社区=(];
火车一个隔离森林模型NYCHousing2015。指定的比例异常的训练观察为0.1,并指定第一个变量(区)作为分类预测。第一个变量是一个数值数组,所以iforest假设这是一个连续变量,除非你指定变量作为分类变量。
rng (“默认”)%的再现性(Mdl, tf,分数)= iforest (NYCHousing2015 ContaminationFraction = 0.1,…CategoricalPredictors = 1);
Mdl是一个IsolationForest对象。iforest还返回异常指标(特遣部队)和异常分数(分数训练数据)NYCHousing2015。
画一个柱状图的分数值。创建一个垂直线的分数阈值对应于指定的分数。
直方图(分数)参照线(Mdl.ScoreThreshold,“r -”,(“阈值”Mdl.ScoreThreshold])
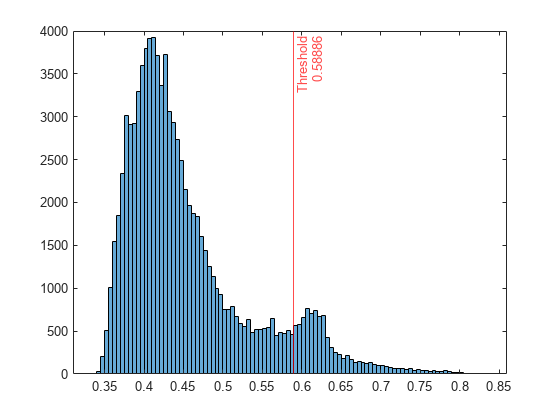
如果你想确定异常污染有不同的分数(例如,0.01),你可以训练一个新的隔离森林模型。
rng (“默认”)%的再现性(newMdl newtf,分数)= iforest (NYCHousing2015,…ContaminationFraction = 0.01, CategoricalPredictors = 1);
如果你想确定异常有不同的分数阈值(例如,0.65),你可以通过IsolationForest对象,训练数据,和一个新的阈值isanomaly函数。
[newtf,分数]= isanomaly (Mdl、NYCHousing2015 ScoreThreshold = 0.65);
注意,改变污染分数或分数阈值变化异常指标,并且不影响异常的分数。因此,如果你不想计算异常分数再次利用iforest或isanomaly,您可以获得一个新的异常指标与现有的评分值。
改变训练数据中的异常的分数为0.01。
newContaminationFraction = 0.01;
找到一个新的分数阈值使用分位数函数。
1-newContaminationFraction newScoreThreshold =分位数(分数)
newScoreThreshold = 0.7045
获得一个新的异常指标。
newtf = > newScoreThreshold得分;
发现新奇事物
创建一个IsolationForest未被污染的培训对象观察使用iforest函数。然后检测小礼品(新数据异常)通过对象和新的数据对象的功能isanomaly。
1994年的人口普查数据加载存储census1994.mat。数据集由人口数据来自美国人口普查局预测一个人是否使每年超过50000美元。
负载census1994
census1994包含了训练数据集adultdata和测试数据集成人。
火车一个隔离森林模型adultdata。假设adultdata不包含异常值。
rng (“默认”)%的再现性[Mdl, tf, s] = iforest (adultdata);
Mdl是一个IsolationForest对象。iforest还返回异常指标特遣部队和异常分数年代的训练数据adultdata。如果你不指定ContaminationFraction名称参数值大于0,iforest对待所有正常训练观察观察,这意味着所有的值特遣部队是逻辑0 (假)。这个函数设置分数阈值最大的分数值。显示阈值。
Mdl.ScoreThreshold
ans = 0.8600
发现异常成人通过训练有素的隔离森林模型。
[tf_test, s_test] = isanomaly (Mdl,成人);
的isanomaly函数的作用是:返回异常指标tf_test和分数s_test为成人。默认情况下,isanomaly确定观测分数高于阈值(Mdl.ScoreThreshold)异常。
创建直方图异常分数年代和s_test。创建一个垂直线阈值的异常分数。
直方图(年代,规范化=“概率”)举行在直方图(s_test正常化=“概率”)参照线(Mdl.ScoreThreshold“r -”,加入([“阈值”Mdl.ScoreThreshold]))传说(“训练数据”,“测试数据”位置=“西北”)举行从
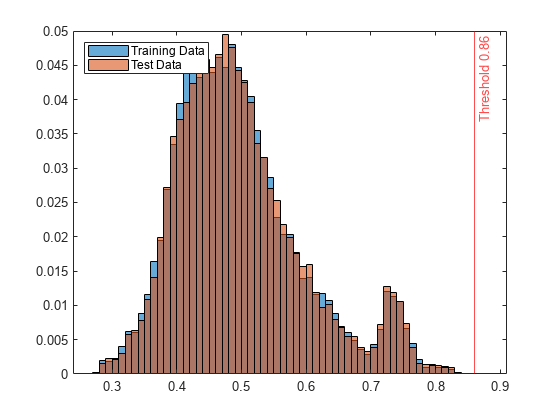
显示异常的观测指标的测试数据。
找到(tf_test)
ans = 15655
的异常分数分布测试数据与训练数据,isanomaly检测到少量的测试数据与异常默认阈值。您可以指定一个不同的阈值使用ScoreThreshold名称-值参数。例如,看到的指定异常分数阈值。
输入参数
输出参数
更多关于
算法
iforest认为南,”(空字符向量),”“(空字符串),<失踪>,<定义>值资源描述和南值X缺失值。
iforest不使用观测与所有缺失值。函数分配1和异常指标的异常分数假(逻辑0)的观察。iforest使用观察一些缺失值找到分裂这些观测变量的有效值。
引用
[1],f . T。,K. M. Ting, and Z. Zhou. "Isolation Forest,"2008第八届IEEE国际会议数据挖掘。比萨,意大利,2008年,页413 - 422。
扩展功能
版本历史
介绍了R2021b