对考试成绩进行因素分析
这个例子展示了如何使用Statistics和Machine Learning Toolbox™执行因子分析。
多元数据通常包括大量测量变量,有时这些变量“重叠”在某种意义上,它们的组可能是相互依赖的。例如,在十项全能比赛中,每个运动员参加10个项目,但其中有几个项目可以被认为是“速度”项目,而其他项目可以被认为是“力量”项目,等等。因此,一个竞争者的10个项目得分可能被认为很大程度上依赖于较小的3或4种运动能力。
因素分析是一种将模型与多元数据相匹配以估计这种相互依赖性的方法。
因素分析模型
在因素分析模型中,被测变量依赖于少量未观测到的(潜在的)因素。因为每个因素可能影响几个共同的变量,所以它们被称为“共同因素”。每个变量都假定依赖于公共因素的线性组合,这些系数被称为载荷。每个测量变量还包括一个独立随机变异性的组成部分,称为“特定方差”,因为它是特定于一个变量。
具体来说,因素分析假设数据的协方差矩阵是这样的形式
SigmaX = * +
其中是载荷矩阵,对角矩阵的元素是具体的方差。这个函数factoran使用最大似然拟合因子分析模型。
例如:寻找影响考试成绩的共同因素
120名学生每人参加五次考试,前两次涉及数学,后两次涉及文学,第五次是综合考试。对于一个学生来说,五个等级之间应该有联系,这似乎是合理的。有些学生两门都擅长,有些学生只擅长一门,等等。这一分析的目的是确定是否有定量证据表明,学生在五种不同考试中的成绩在很大程度上取决于两种能力。
首先加载数据,然后调用factoran并要求模型符合单一公因数。
负载examgrades[Loadings1 specVar1 T,统计]= factoran(等级1);
factoran的前两个返回参数是估计的装载量和估计的特定方差。从估计的负荷中,你可以看到这个模型中的一个共同因素在所有五个变量上都有很大的正权重,但大多数权重在第五次综合考试上。
Loadings1
Loadings1 = 0.6021 0.6686 0.7704 0.7204 0.9153
对这种契合的一种解释是,人们可能会根据学生的“综合能力”来考虑他们,对此,综合考试将是最好的衡量标准。学生在特定学科的测试中所取得的成绩不仅取决于他们的综合能力,还取决于该学生在该领域是否优秀。这就解释了前四门考试的低负荷。
从估计的特定方差中,你可以看到,该模型表明,特定学生在特定测试中的成绩变化很大,超出了由于公共因素造成的变化。
specVar1
specVar1 = 0.6375 0.5530 0.4065 0.4810 0.1623
一个特定的方差为1表示存在没有该变量的公因子分量,而特定方差为0则表示该变量为完全由公共因素决定。这些考试成绩似乎介于两者之间,尽管综合考试的具体变化最小。这与上述对该模型中单一公共因素的解释是一致的。
函数中返回的p值统计数据结构拒绝了单一公因式的原假设,因此我们重新构建了模型。
stats.p
ans = 0.0332
接下来,用两个常见的因素来试着更好地解释考试成绩。对于多个因素,您可以旋转估计的负载,试图使它们的解释更简单,但目前,要求一个不旋转的解决方案。
[Loadings2 specVar2 T,统计]= factoran(等级2“旋转”,“没有”);
从估计的负载中,您可以看到第一个非旋转因素对所有五个变量的权重大致相同,而第二个因素将前两个变量与后两个变量进行对比。
Loadings2
Loadings2 = 0.6289 0.3485 0.6992 0.3287 0.7785 -0.2069 0.7246 -0.2070 0.8963 -0.0473
你可以将这些因素解释为“综合能力”和“定量与定性能力”,扩展了之前对单因素匹配的解释。
变量的绘图(其中每个加载都是相应因素轴上的坐标)图形化地说明了这种解释。前两种考试对第二种因素有积极的影响,表明它们依赖于“定量”能力,而后两种考试显然依赖于相反的能力。第五次考试对第二个因素的影响很小。
biplot (Loadings2“varlabels”num2str ((1:5) '));标题(不旋转的解决方案的);包含(“潜在因素1”);ylabel (《潜在因素2》);

从估计的特定方差中,你可以看到,这个双因素模型表明,由于公共因素,比单因素模型的变化更少。同样,第五次考试的特定差异最小。
specVar2
specVar2 = 0.4829 0.4031 0.3512 0.4321 0.1944
的统计数据结构表明,该双因素模型只有一个自由度。
stats.dfe
ans = 1
只有五个测量变量,你不能用两个以上的因素来拟合一个模型。
来自协方差/相关矩阵的因素分析
您可以使用原始测试分数进行上述匹配,但有时您可能只有一个总结数据的样本协方差矩阵。factoran接受协方差或相关矩阵,使用“Xtype”参数,并给出与原始数据相同的结果。
σ= x(成绩);[LoadingsCov, specVarCov] =...factoran(σ2“Xtype”,“浸”,“旋转”,“没有”);LoadingsCov
LoadingsCov = 0.6289 0.3485 0.6992 0.3287 0.7785 -0.2069 0.7246 -0.2070 0.8963 -0.0473
因子旋转
有时候,来自因素分析模型的估计负荷可能会为一些测量变量的几个因素赋予很大的权重,使得解释这些因素所代表的含义变得困难。因子旋转的目标是找到每个变量只有少量的大负荷,即受少量的因素,最好只有一个因素影响的解。
如果你把载荷矩阵的每一行看作是m维空间中一个点的坐标,那么每个因子对应于一个坐标轴。因子旋转相当于旋转这些轴,并在旋转的坐标系中计算新的载荷。有很多方法可以做到这一点。一些方法使坐标轴正交,而另一些方法是倾斜的,改变了它们之间的角度。
方差是正交旋转的一个常见判据。factoran默认情况下执行varimax旋转,所以不需要显式地请求它。
[LoadingsVM, specVarVM rotationVM] = factoran(等级2);
快速检查返回的最大旋转矩阵factoran确认它是正交的。Varimax实际上是旋转上图中的因子轴,但使它们保持直角。
rotationVM‘* rotationVM
Ans = 1.0000 0.0000 0.0000 1.0000
五个变量对旋转因子的双图显示了最大旋转的影响。
biplot (LoadingsVM“varlabels”num2str ((1:5) '));标题(“最大方差法解决方案”);包含(“潜在因素1”);ylabel (《潜在因素2》);
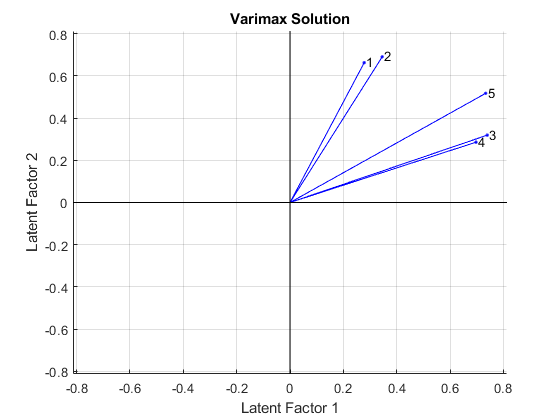
Varimax刚性旋转轴,试图使所有载荷接近零或一。前两种考试最接近第二因素轴,而第三和第四种考试最接近第一因素轴,第五种考试处于中间位置。这两个旋转的因素可以最好地解释为“定量能力”和“定性能力”。然而,由于没有一个变量靠近因子轴,双图显示正交旋转不能成功地提供一组简单的因子。
由于正交旋转不是完全令人满意的,您可以尝试使用promax,一种常见的斜旋转标准。
[LoadingsPM, specVarPM rotationPM] =...factoran(等级2“旋转”,的电子产品品牌);
对返回的promax旋转矩阵进行检查factoran证明了它不是正交的。Promax实际上是单独旋转第一个图形中的因子轴,使它们之间有一个斜角。
rotationPM‘* rotationPM
Ans = 1.9405 -1.3509 -1.3509 1.9405
新旋转因子上变量的双图显示了promax旋转的影响。
biplot (LoadingsPM“varlabels”num2str ((1:5) '));标题(“电子产品品牌解决方案”);包含(“潜在因素1”);ylabel (《潜在因素2》);

Promax实现了轴的非刚性旋转,并且在创建“简单结构”方面比varimax做得更好。前两次考试接近第二因素轴,而第三和第四次考试接近第一因素轴,第五次考试处于中间位置。这使得对这些旋转因素的“定量能力”和“定性能力”的解释更加精确。
不是在不同的旋转轴上绘制变量,而是可以将旋转轴覆盖在一个未旋转的双图上,以更好地了解旋转和未旋转的解是如何关联的。金宝搏官方网站
h1 = biplot (Loadings2,“varlabels”num2str ((1:5) '));包含(“潜在因素1”);ylabel (《潜在因素2》);持有在invRotVM =发票(rotationVM);h2 = line([-invRotVM(1,1) invRotVM(1,1) NaN -invRotVM(2,1) invRotVM(2,1)],...[-invRotVM(1,2) invRotVM(1,2) NaN -invRotVM(2,2) invRotVM(2,3)],“颜色”, (1 0 0));invRotPM =发票(rotationPM);h3 = line([-invRotPM(1,1) invRotPM(1,1) NaN -invRotPM(2,1) invRotPM(2,1)],...[-invRotPM(1,2) invRotPM(1,2) NaN -invRotPM(2,2) invRotPM(1,2)],“颜色”[0 1 0]);持有从轴广场lgndHandles = [h1(1) h1(end) h3]; / /结束lgndLabels = {“变量”,不旋转的轴的,“方差极大旋转坐标轴”,“电子产品品牌旋转坐标轴”};传奇(lgndHandles lgndLabels,“位置”,“东北”,“字体名”,“arial窄”);

预测因子得分
有时,能够根据其因子得分对观察结果进行分类是有用的。例如,如果您接受双因素模型和promax旋转因子的解释,您可能想要预测一个学生在未来的数学考试中会有多好。
因为这些数据是原始的考试成绩,而不仅仅是它们的协方差矩阵,我们可以factoran返回每个学生的两个旋转公因数的预测值。
(载荷、specVar旋转,统计,仅仅]=...factoran(等级2“旋转”,的电子产品品牌,“麦克斯特”, 200);biplot(载荷,“varlabels”num2str ((1:5) '),“分数”,仅仅);标题(“Promax解决方案的预测因子得分”);包含(“文学能力”);ylabel (“数学能力”);

这张图显示了模型在原始变量(向量)和每个观测值(点)的预测分数方面的拟合。这种契合性表明,虽然一些学生在某一科目上表现很好,但在其他科目(第二和第四象限)上表现不佳,但大多数学生在数学和文学(第一和第三象限)上要么表现得很好,要么表现得很差。你可以通过观察这两个因素的估计相关矩阵来证实这一点。
发票(旋转的旋转*)
Ans = 1.0000 0.6962 0.6962 1.0000
因子分析与主成分分析的比较
主成分分析(PCA)和因子分析(FA)在术语和目标上有很多重叠。很多关于这两种方法的文献并没有区分它们,一些拟合FA模型的算法涉及到主成分分析。这两种方法都是降维技术,从某种意义上说,它们可以用一组较小的新变量来替换一组大的观测变量。他们也经常给出相似的结果。然而,这两种方法的目标和底层模型是不同的。粗略地说,当您仅仅需要使用更少的维度来总结或近似您的数据时(例如,可视化它),您应该使用PCA;当您需要一个解释数据之间相关性的模型时,您应该使用FA。
你也可以从以下列表中选择一个网站:
