逐步
交互式逐步回归
句法
逐步
逐步(x,y)
逐步(x,y,Inmodel,penter,mefrove)
描述
逐步使用示例数据hald.mat显示用于执行响应值的逐步回归的图形用户界面热关于预测术语配料。
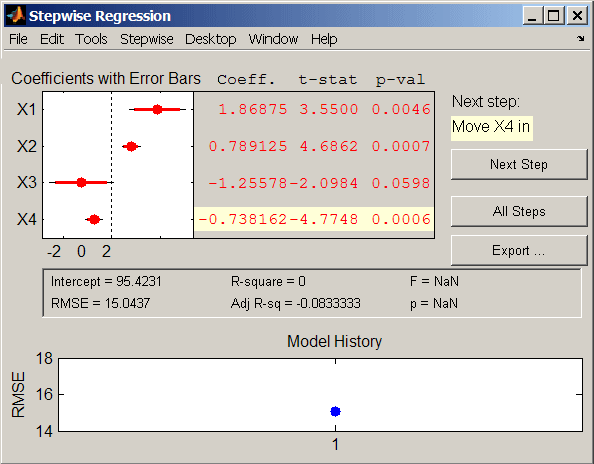
界面的左上方显示所有潜在术语的系数的估计,水平条表示90%(有色)和95%(灰色)置信区间。红色表示,最初,术语不在模型中。表中显示的值是那些会导致术语添加到模型中的值。
界面的中间部分显示整个模型的摘要统计信息。每步更新这些统计信息。
界面的下部,模型历史,显示模型的RMSE。绘图跟踪从步骤转到步骤的RMSE,因此您可以比较不同模型的最优性。将鼠标悬停在历史中的蓝色点上,以了解特定步骤的模型中的术语。单击历史记录中的蓝色点,以打开该步骤中模型中的术语初始化的界面的副本。
初始模型,以及入口/退出公差P.- 值F-statistics,使用其他输入参数指定逐步。默认值是一个初始模型,没有术语,入口容差为0.05,出口公差为0.10。
居中并缩放输入数据(计算Z.- 为改善底层最小二乘问题的调节,选择规模输入来自逐步菜单。
您以两种方式之一通过逐步回归:
点击下一步选择推荐的下一步。推荐的下一步要么添加最重要的术语或删除最不重要的术语。当回归达到局部最少的RMSE时,推荐的下一步是“没有术语。”您可以单击一次执行所有推荐步骤所有步骤。
单击绘图中的行或表中的一行以切换相应术语的状态。单击一个红线,对应于当前在模型中的术语,将术语添加到模型中,并将行更改为蓝色。单击对应于模型中的术语的蓝线,从模型中删除术语,并将行更改为红色。
打电话添加了varplot.并生成来自的添加变量图逐步接口,选择添加了变量图来自逐步菜单。显示一个术语列表。选择要添加的术语,然后单击行。
点击出口要显示一个对话框,允许您从接口中选择信息以保存到MATLAB®工作区。检查要导出的信息,然后选择要更改要创建的工作区变量的名称。点击行导出信息。
逐步(x,y)使用使用的接口P.预测术语N-经过-P.矩阵X以及响应值N-By-1矢量y。明显的预测术语应出现在不同的列中X。
笔记
逐步在所有型号中自动包括常数术语。不要直接进入1s的一列X。
逐步对待南任何一个值X要么y作为缺少的值,忽略它们。
逐步(x,y,Inmodel,penter,mefrove)此外指定初始模型(inmodel.)和入口(p)出口(主体)公差P.- 值F-统计数据。inmodel.是长度等于列数的逻辑向量X或指数的矢量,值从1到列数X。的价值p必须小于或等于价值主体。
算法
逐步回归是基于回归中的统计学意义,从多线性模型添加和移除术语的系统方法。该方法从初始模型开始,然后比较递增更大且较小模型的解释性。在每一步,P.AN的价值F- 可以计算与潜在术语的模型测试模型。如果术语当前不是该模型中,则返回null假设是如果添加到模型中,术语将具有零系数。如果有足够的证据来拒绝空假设,则该术语将添加到模型中。相反,如果术语当前在模型中,则空假设是该术语具有零系数。如果没有足够的证据来拒绝零假设,则从模型中删除该术语。该方法如下所示:
适合初始模型。
如果模型中没有任何术语P.-Values比入射公差小于(即,如果它们不太可能在模型中添加零系数),则将其添加最小的P.价值并重复此步骤;否则,转到第3步。
如果模型中的任何术语都有P.-Values大于出口容差(即,如果可以拒绝零系数的假设不太可能),请将其删除最大的P.价值并转到步骤2;否则,结束。
根据初始模型中包含的条款和术语中移动的顺序,该方法可以从相同的潜在术语构建不同的模型。当没有单步改善模型时,该方法终止。但是,没有保证,不同的初始模型或不同的步骤序列不会导致更好的拟合。从这个意义上讲,逐步模型是局部最佳的,但可能不是全局最佳的。
也可以看看
您还可以从以下列表中选择一个网站:
