自动检测和识别自然图像中的文本
此示例显示如何检测包含文本的图像中的区域。这是在非结构化场景上执行的常见任务。非结构化场景是包含未确定或随机方案的图像。例如,您可以从捕获的视频自动检测和识别文本,以提醒驱动程序了解道路标志。这与结构化场景不同,其中包含文本的位置预先已知的已知场景。
来自非结构化场景的分割文本极大地有助于诸如光学字符识别(OCR)等附加任务。此示例中的自动文本检测算法检测到大量文本区域候选,并且逐步地删除那些不太可能包含文本的候选。
步骤1:使用MSER检测候选文本区域
MSER功能检测器适用于查找文本区域[1]。它适用于文本,因为文本的一致颜色和高对比度导致稳定的强度配置文件。
用来检测器饲料功能要在图像中找到所有区域并绘制这些结果。请注意,与文本一起检测到许多非文本区域。
colorimage = imread('handcapsign.jpg');i = im2gray(colorimage);%检测MSER区域。[MSERREGIONS,MSERCONNCCOMP] = DEVICEMSERFEATURES(I,......'RegionArange',[200 8000],'thresholddelta'4);图imshow(i)持有在绘图(MSERREGIONS,'showpixellist',真实,'showlipses',假)标题('mser地区'抱紧关闭

第2步:基于基本几何属性删除非文本区域
虽然MSER算法拾取了大部分文本,但它还检测到没有文本的图像中的许多其他稳定区域。您可以使用基于规则的方法来删除非文本区域。例如,文本的几何属性可用于使用简单阈值过滤掉非文本区域。或者,您可以使用机器学习方法来培训文本与非文本分类器。通常,两种方法的组合产生了更好的结果[4]。此示例使用简单的基于规则的方法来基于几何属性过滤非文本区域。
有几个几何属性,可善于区分文本和非文本区域[2,3],包括:
宽高比
偏心
欧拉号码
范围
坚固
使用regionprops测量这些属性中的一些,然后根据其属性值删除区域。
%使用RegionProps来测量MSER属性母兽= RegionProps(MserconnComp,'绑定盒'那'偏心'那......“稳健”那'范围'那'euler'那'图像');%使用边界框数据计算宽高比。bbox = Vertcat(mserstats.boundingbox);W = BBOX(:,3);H = BBOX(:,4);Aspectratio = W./h;%阈值数据以确定要删除的区域。这些阈值可能需要调整%的其他图像。filteridx = Aspectratio'> 3;FilterIDX = FilterIdX |[Mserstats.Eccentricity]> .995;FilterIDX = FilterIdX |[Mserstats.silidy] <.3;FilterIDX = FilterIdX |[mserstats.extent] <0.2 |[mserstats.extent]> 0.9;FilterIDX = FilterIdX |[Mserstats.eulernumber] <-4;%删除地区母兽(FilteridX)= [];MSERREGIONS(FilterIDX)= [];%显示剩余地区图imshow(i)持有在绘图(MSERREGIONS,'showpixellist',真实,'showlipses',假)标题(“基于几何属性删除非文本区域”抱紧关闭

步骤3:基于行程宽度变化删除非文本区域
用于区分文本和非文本的另一个常见度量是笔划宽度。行程宽度是构成角色的曲线和线宽的尺寸。文本区域往往具有很小的行程宽度变化,而非文本区域往往具有更大的变化。
为了帮助了解行程宽度如何用于去除非文本区域,估计其中一个检测到的MSER区域的行程宽度。您可以使用距离变换和二进制细化操作来执行此操作[3]。
得到一个区域的二值图像,并填充它以避免边界影响在笔划宽度计算期间%。RegionImage =母兽(6).Image;RegionImage = PadArray(RegionImage,[1 1]);%计算笔划宽度图像。骑马= BWDIST(〜RegionImage);steletonimage = bwmorph(区域图像,'瘦',INF);Strokewidthimage =拆卸;StrokeWidthimage(〜骨骼贴图)= 0;%显示与行程宽度图像旁边的区域图像。图副区(1,2,1)于imagesc(regionImage)标题(地区形象的)子图(1,2,2)ImageC(StrokeWidthimage)标题('行程宽度图像')
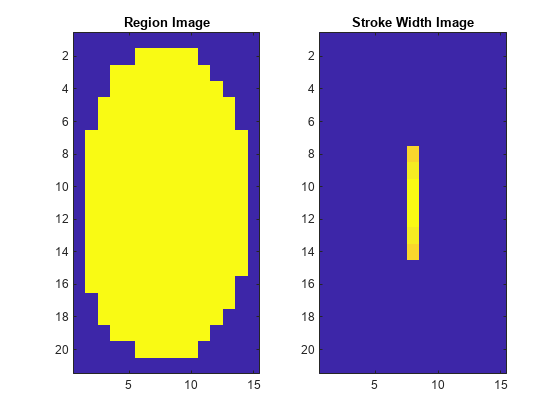
在上面所示的图像中,请注意笔划宽度图像在大部分区域上的变化很小。这表明该区域更可能是文本区域,因为构成该区域的线和曲线都具有相似的宽度,这是人类可读文本的共同特征。
为了使用笔划宽度变化来使用阈值删除非文本区域,必须将整个区域的变化量定量为单个度量,如下所示:
%计算行程宽度变化度量Strokewidthvalues =拆卸(骨骼贴图);Strokewidthmetric = std(strokewidthvalues)/平均值(strokewidthvalues);
然后,可以应用阈值来删除非文本区域。注意,该阈值可能需要调整具有不同字体样式的图像。
笔画宽度变化的阈值strokeWidthThreshold = 0.4;strokeWidthFilterIdx = strokeWidthMetric > strokeWidthThreshold;
上面所示的过程必须单独应用于每个检测到的MSER区域。以下用于循环处理所有区域,然后示出使用笔划宽差越差去除非文本区域的结果。
%处理剩余的区域对于J = 1:Numel(MSSterats)RegionImage = MserStats(J).Image;RegionImage = PadArray(RegionImage,[1 1],0);骑马= BWDIST(〜RegionImage);steletonimage = bwmorph(区域图像,'瘦',INF);Strokewidthvalues =拆卸(骨骼贴图);Strokewidthmetric = std(strokewidthvalues)/平均值(strokewidthvalues);Strokewidthfilteridx(j)= Strokewidthmetric> Strokewidthreshold;结束%拆下基于行程宽度变化的区域mserregions(strokewidthfilteridx)= [];母兽(Strokewidthfilteridx)= [];%显示剩余地区图imshow(i)持有在绘图(MSERREGIONS,'showpixellist',真实,'showlipses',假)标题(“基于行程宽度变化去除非文本区域之后”抱紧关闭

步骤4:合并用于最终检测结果的文本区域
此时,所有检测结果都由各个文本字符组成。要使用这些结果进行识别任务,例如OCR,则必须将各个文本字符合并为单词或文本行。这使得能够识别图像中的实际单词,其携带比只有各个字符更有意义的信息。例如,识别字符串'退出'与该组的单个字符{'x','e','t','i'},在没有正确的排序的情况下丢失这个词的含义。
将单个文本区域合并为单词或文本行的一种方法是首先找到相邻的文本区域,然后在这些区域周围形成边界框。要查找邻居区域,请展开先前计算机计算的边界框regionprops。这使得邻近文本区域的边界框重叠,使得具有相同单词或文本线的一部分的文本区域形成重叠边界框的链。
%收到所有区域的边界框bboxes = Vertcat(mserstats.boundingbox);%从[x y宽高]边框格式转换为[xmin ymin]%xmax ymax]为方便起见。xmin = bboxes(:,1);ymin = bboxes(:,2);xmax = xmin + bboxes(:,3) - 1;ymax = ymin + bboxes(:,4) - 1;%将边界框扩展少量。扩展= 0.02;xmin =(1-soceantamount)* xmin;ymin =(1-soceantamount)* ymin;XMAX =(1 + expansionAmount)* XMAX;Ymax =(1 + expansionAmount)* Ymax;%剪辑边界框以在图像边界内xmin = max(xmin,1);ymin = max(ymin,1);Xmax = min(Xmax,尺寸(I,2));Ymax = min(Ymax,尺寸(i,1));%显示展开的边界框ExpandedBboxes = [Xmin Ymin xmax-xmin + 1 Ymax-ymin + 1];iExpandedBboxes = insertshape(colorimage,'矩形',expandedBBoxes,'linewidth',3);图imshow(iExpandedBboxes)标题('扩展边界框文本')

现在,可以将重叠边界框合并在一起,以形成各个单词或文本行周围的单个边界框。为此,计算所有边界框对之间的重叠比。这量化了所有文本区域之间的距离,以便通过查找非零重叠比来找到相邻文本区域的组。一旦计算了一对重叠比率,请使用a图表通过非零重叠率查找“连接”的所有文本区域。
用来bboxOverlapRatio为所有扩展边界框计算成对重叠比的功能,然后使用图表找到所有连接的区域。
%计算重叠率Overlapratio = Bboxoverlapratio(ExpandedBboxes,ExpandedBboxes);%将边界框之间的重叠率设置为零%简化了图形表示。n =大小(重叠,1);重叠(1:n + 1:n ^ 2)= 0;%创建图表g =图(重叠);%在图中找到连接的文本区域ComponentIndices = Conncomp(g);
输出conncomp是每个边界框所属的连接文本区域的索引。使用这些索引通过计算构成构成每个连接组件的各个边界框的最小和最多,将多个相邻边界框合并到单个边界框中。
%基于最小和最大维度合并框。Xmin = Accularray(ComponentIndices',Xmin,[],@min);ymin = Accumarray(ComponentIndices',Ymin,[],@min);Xmax = Accumarray(ComponentIndices',Xmax,[],@max);Ymax = Accumarray(ComponentIndices',Ymax,[],@max);%使用[x y宽度高度]格式组成合并边界框。textbboxes = [xmin ymin xmax-xmin + 1 ymax-ymin + 1];
最后,在显示最终检测结果之前,通过删除由一个文本区域组成的边界框来抑制错误的文本检测。这将删除不太可能是实际文本的孤立区域,因为通常以组(单词和句子)找到文本。
删除只包含一个文本区域的边界框numregionsingroup = histcounts(componentindices);textBboxes(numregionsingroup == 1,:) = [];%显示最终的文本检测结果。ItextRegion = insertshape(colorimage,'矩形',textbboxes,'linewidth',3);数字imshow(ItextRegion)标题('检测到的文字')

第5步:使用OCR识别检测到的文本
检测到文本区域后,使用OCR.函数识别每个边界框内的文本。注意,如果没有首先找到文本区域,则输出OCR.功能会更加嘈杂。
OCRTXT = OCR(i,textbboxes);[ocrtxt.text]
ANS ='Handicixpped停车特种板需要未经授权的车辆,可以在业主费用中拖曳
这个示例向您展示了如何使用MSER特征检测器检测图像中的文本,首先找到候选文本区域,然后描述了如何使用几何测量来删除所有非文本区域。这个示例代码是开发更健壮的文本检测算法的良好起点。请注意,无需进一步增强,此示例可以为各种其他图像生成合理的结果,例如,posters.jpg或licensePlates.jpg。
参考文献
[1]陈,惠忠,等。“具有边缘增强最大稳定的极值区域的自然图像中的强大文本检测。”图像处理(ICIP),2011年第18届IEEE国际会议。IEEE,2011年。
[2] Gonzalez,Alvaro,等。“复杂图像中的文本位置。”模式识别(ICPR),2012年第21届国际会议。IEEE,2012年。
[3]李,姚明和慧川陆。“场景文本通过行程宽度检测。”模式识别(ICPR),2012年第21届国际会议。IEEE,2012年。
[4] Neumann,Lukas和Jiri Matas。“实时场景文本本地化和识别。”计算机愿景和模式识别(CVPR),2012年IEEE会议。IEEE,2012年。
您还可以从以下列表中选择一个网站:
