语义分割凭借深厚的学习
分析语义分割的培训数据
要培训语义分割网络,您需要一系列图像及其相应的像素集合标记图像。标记图像的像素是图像,其中每个像素值表示该像素的分类标签。
以下代码加载了一小组图像及其标记图像的相应像素:
datadir = fullfile(toolboxdir('想象'),'visiondata');imdir = fullfile(datadir,'建造');pxdir = fullfile(datadir,'buildingpixellabels');
使用一个加载图像数据imageageAtastore..图像数据存储可以有效地表示大量的图像集合,因为只有在需要时才将图像读入内存。
IMDS = imageageAtastore(IMDIR);
读取并显示第一个图像。
i = ReadImage(IMDS,1);图imshow(i)

使用。加载像素标签图像PixellabeldAtastore.定义标签ID和分类名称之间的映射。在这里使用的数据集中,标签是“sky”,“草”,“建筑”和“人行道”。这些类的标签ID分别为1,2,3,4。
定义类名。
一会= [“天空”“草”“建造”“人行道”];
为每个类名定义标签ID。
Pixellabelid = [1 2 3 4];
创建一个PixellabeldAtastore..
pxds = pixelLabelDatastore(pxDir,类名,pixelLabelID);
读取第一个像素标签图像。
C = ReadImage(PXD,1);
输出C是一个分类矩阵在哪里C(I,J)是像素的分类标签我(我,j).
C (5,5)
ans =.分类天空
覆盖在图像上的像素标签怎么看图像的不同部分被标记。
B = Labeloverlay(I,C);图imshow(b)

分类输出格式简化了需要按类名进行事项的任务。例如,您可以创建一个刚建筑物的二进制蒙版:
建筑物= C =='建造';图imshowpair(i,bubjectmask,'剪辑')

创建语义分段网络
创建一个简单的语义分段网络,并了解在许多语义分段网络中发现的常见层。语义分割网络中的常见模式需要卷积和Relu层之间的图像的下采样,然后将输出上置以匹配输入大小。该操作类似于使用图像金字塔的标准刻度空间分析。然而,在此过程中,网络使用针对要段的特定类集合的非线性滤波器执行操作。
创建图像输入层
语义分割网络从一个开始imageInputLayer,它定义了网络可以处理的最小图像大小。大多数语义分割网络是完全卷积的,这意味着它们可以处理大于指定输入大小的图像。这里,[32 32 3]的图像大小用于网络处理64x64 RGB图像。
inputSize = [32 32 3];imgLayer = imageInputLayer (inputSize)
Imglayer =具有属性的ImageInputLayer:name:''输入:[32 32 3] HyperParameters DataAugmentation:'无'标准化:'Zerocenter'
创建取样网络
从卷积和relu层开始。选择卷积层填充,使得卷积层的输出尺寸与输入大小相同。这使得更容易构建网络,因为大多数层之间的输入和输出大小随着通过网络的进步而保持相同。
filtersize = 3;numFilters = 32;CONV = convolution2dLayer(filterSize,numFilters,'填充',1);Relu = Rululayer();
使用最大池层执行下采样。通过设置'创建一个最大池池层以将输入缩小为2倍。跨越“参数为2。
poolsize = 2;maxpooldownsample2x = maxpooling2dlayer(poolsize,'走吧',2);
堆叠卷积,RELU和最大池层来创建由4倍下采样其输入的网络。
downsamplingLayers = [CONV RELU maxPoolDownsample2x CONV RELU maxPoolDownsample2x]
downsamplingLayers = 6×1层阵列层:1 '' 卷积32分3×3的卷积与步幅[1 1]和填充[1 1 1 1] 2 '' RELU RELU 3 '' 最大池2x2的最大蓄留与步幅[2 2]和填充[0 0 0 0] -4 '' 卷积32分3×3的卷积与步幅[1 1]和填充[1 1 1 1]的5 '' RELU RELU 6 '' 最大池2x2的最大蓄留与步幅[2 2]和填充[00 0 0]
创建上采样网络
上采样是使用转置卷积层(也通常称为“deconv”或“deconvolution”层)完成的。当使用转置卷积进行上采样时,它同时进行上采样和滤波。
创建的转置卷积层由2上采样。
filtersize = 4;transpodingconvupsample2x = transposedconv2dlayer(4,numfilters,'走吧'2,'裁剪',1);
'裁剪'参数设置为1,使输出大小等于输入大小的两倍。
堆叠转置的卷积和relu层。该组图层的输入载于4。
UpsamplingLayers = [TranspostConvupsample2x Relu TranspodingConvupsample2x Relu]
upsamplingLayers = 4X1层阵列层:1 '' 转置卷积32个的4×4转置卷积与步幅[2 2]和输出裁剪[11] 2 '' RELU RELU 3 '' 转置卷积32个的4×4转置卷积与步幅[2 2]和输出裁剪[11] 4“” RELU RELU
创建像素分类层
最后一组层中的有责任像素分类。这些最终层处理具有相同的空间尺寸(高度和宽度)作为输入图像的输入。然而,信道的数量(第三维度)较大并且是最近互换的卷积层等于滤波器数目。这第三个维度需要被压缩到我们希望段的类的数量。这可以使用一个1×1的卷积层,其的过滤器数目等于类的数量来进行,例如3.
创建一个卷积图层,以将输入特征的第三维度组合到映射到类的数量。
numclasses = 3;conv1x1 = Convolution2Dlayer(1,Numcrasses);
在此1×1卷积层之后是Softmax和像素分类层。这两层组合以预测每个图像像素的分类标签。
finalLayers = [conv1x1 softmaxLayer()pixelClassificationLayer()]
FINALLAYERS = 3x1层阵列,带有层:1''卷积3 1x1卷绕升温[11]和填充[0 0 0 0] 2''softmax softmax 3''像素分类层跨熵丢失
堆叠所有层
堆叠中的所有层,完成语义分割网络。
net = [Imglayer DownsamplingLayers UpsamplingLayers finAllayers]
net = 14x1 Layer array with layers:1”的形象输入32 x32x3图像zerocenter正常化2”卷积32 3 x3的隆起与步幅[1]和填充[1 1 1 1]3”ReLU ReLU 4”马克斯池2 x2马克斯池步(2 - 2)和填充[0 0 0 0]5“卷积32 3 x3的隆起与步幅[1]和填充1 1 1 1 6”ReLU ReLU 7”麦克斯池2 x2马克斯池步(2 - 2)和填充[0 0 0 0]8“转置卷积32 4 x4转置运算与步幅[2 2]和输出裁剪[1]9”ReLU ReLU 10“转置卷积32 4 x4转置运算与步幅[2 2]和输出裁剪[1]11“ReLU ReLU 12“卷积3 1 x1[1]和隆起与进步填充[0 0 0]13 " Softmax Softmax 14 "像素分类层交叉熵损失
该网络已准备好使用Trainnetwork.来自深度学习工具箱™。
训练一个语义分割网络
加载培训数据。
datasetdir = fullfile(toolboxdir('想象'),'visiondata'那'triangleimages');IMAGEDIR =完整文件(dataSetDir,'培训码');labelDir = fullfile (dataSetDir,'训练标签');
为图像创建图像数据存储。
IMDS = IMAGEDATASTORE(IMAGEDIR);
创建一个PixellabeldAtastore.对于地面真相像素标签。
一会= [“三角形”那“背景”];labelids = [255 0];pxds = pixellabeldataStore(Labeldir,ClassNames,LabelIds);
可视化训练图像和地面实况像素的标签。
我=读(imd);C =阅读(pxds);I = imresize (5);L = imresize (uint8 (C {1}), 5);imshowpair (L,我'剪辑')

创建语义分段网络。该网络基于下采样和上采样设计使用简单的语义分割网络。
numfilters = 64;filtersize = 3;numclasses = 2;图层= [imageInputlayer([32 32 1])卷积2dlayer(过滤,numfilters,'填充',1)rululayer()maxpooling2dlayer(2,'走吧',2)卷积2dlayer(过滤,numfilters,'填充',1)reluLayer()transposedConv2dLayer(4,numFilters,'走吧'2,'裁剪',1);卷积2dlayer(1,numcrasses);softmaxlayer()pixelclassificationlayer()]
图层= 10×1层阵列,图层:1''图像输入32×32×1图像,带有'Zerocenter'归一化2''卷积64 3×3卷绕升温[11]和填充[1 1 1 1] 3''Relu Relu 4''最大汇集2×2最大汇集步进[2 2]和填充[0 0 0 0] 5''卷积64 3×3卷绕步进[1 1]和填充[1 1 1 1]6 '' ReLU ReLU 7 '' Transposed Convolution 64 4×4 transposed convolutions with stride [2 2] and cropping [1 1 1 1] 8 '' Convolution 2 1×1 convolutions with stride [1 1] and padding [0 0 0 0] 9 '' Softmax softmax 10 '' Pixel Classification Layer Cross-entropy loss
设置培训选项。
OPTS = trainingOptions('sgdm'那......'italllearnrate',1E-3,......“MaxEpochs”,100,......'MiniBatchSize',64);
结合图像和像素标签数据存储进行训练。
trainingdata = pixellabelimagedataStore(IMDS,PXD);
训练网络。
净= trainNetwork(trainingData,层,OPTS);
单CPU培训。初始化输入数据归一化。| ========================================================================================|时代|迭代|经过时间的时间迷你批量|迷你批量|基础学习| | | | (hh:mm:ss) | Accuracy | Loss | Rate | |========================================================================================| | 1 | 1 | 00:00:00 | 58.11% | 1.3458 | 0.0010 | | 17 | 50 | 00:00:11 | 97.30% | 0.0924 | 0.0010 | | 34 | 100 | 00:00:23 | 98.09% | 0.0575 | 0.0010 | | 50 | 150 | 00:00:34 | 98.56% | 0.0424 | 0.0010 | | 67 | 200 | 00:00:46 | 98.48% | 0.0435 | 0.0010 | | 84 | 250 | 00:00:58 | 98.66% | 0.0363 | 0.0010 | | 100 | 300 | 00:01:09 | 98.90% | 0.0310 | 0.0010 | |========================================================================================|
读取并显示测试图像。
testImage = imread ('triangletest.jpg');imshow(testImage)
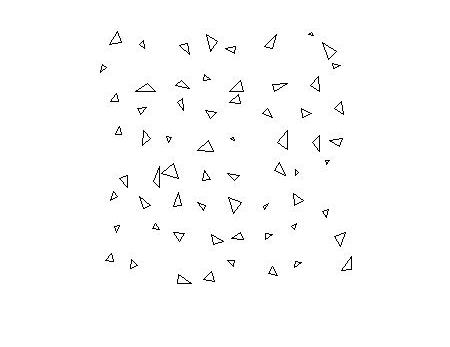
段中的测试图像,并显示结果。
C = SemanticSeg(Testimage,Net);B = Labeloverlay(Testimage,C);imshow(b)

改善结果
网络无法段分割三角形并将每个像素分类为“背景”。培训似乎与大于90%的训练准确性进展顺利。但是,该网络仅学习以对背景类进行分类。要了解为什么发生这种情况,您可以在数据集中计算每个像素标签的发生。
TBL = countEachLabel(pxds)
TBL =2×3表名称PixelCount ImagePixelCount ______________ __________ _______________ { '三角形'} 10326 2.048e + 05 { '背景'} 1.9447e + 05 2.048e + 05
大多数像素标签用于背景。结果不佳是由于阶级不平衡。类别不平衡偏见了学习过程,支持主导类。这就是为什么每个像素被归类为“背景”。要解决此问题,请使用类加权来平衡类。有几种计算类别的方法。一种常用方法是逆频加权,其中类权重是类频率的倒数。这会增加给代表欠款的类别。
TotalNumberofpixels = SUM(TBL.PIXELCOUNT);频率= tbl.pixelcount / totalnumberofpixels;Classweights = 1./罚款
classWeights =2×119.8334 1.0531
类权重可以使用PixelclassificationLayer..更新最后一个图层以使用aPixelclassificationLayer.用逆类权重。
层(结束)= pixelClassificationLayer(“类”资源描述。的名字,'classweight',类别);
再次火车网络。
净= trainNetwork(trainingData,层,OPTS);
单CPU培训。初始化输入数据归一化。| ========================================================================================|时代|迭代|经过时间的时间迷你批量|迷你批量|基础学习| | | | (hh:mm:ss) | Accuracy | Loss | Rate | |========================================================================================| | 1 | 1 | 00:00:00 | 72.27% | 5.4135 | 0.0010 | | 17 | 50 | 00:00:11 | 94.84% | 0.1188 | 0.0010 | | 34 | 100 | 00:00:23 | 96.52% | 0.0871 | 0.0010 | | 50 | 150 | 00:00:35 | 97.29% | 0.0599 | 0.0010 | | 67 | 200 | 00:00:47 | 97.46% | 0.0628 | 0.0010 | | 84 | 250 | 00:00:59 | 97.64% | 0.0586 | 0.0010 | | 100 | 300 | 00:01:10 | 97.99% | 0.0451 | 0.0010 | |========================================================================================|
尝试再次分割测试图像。
C = SemanticSeg(Testimage,Net);B = Labeloverlay(Testimage,C);imshow(b)

使用类加权来平衡类生成了更好的分段结果。提高结果的其他步骤包括增加用于培训的时期的数量,添加更多培训数据,或修改网络。
评估和检查语义分割的结果
导入测试数据集,运行备用语义分段网络,并评估和检查预测结果的语义分割质量指标。
导入数据集
这三角形数据集有100个测试图像,带有地面真理标签。定义数据集的位置。
datasetdir = fullfile(toolboxdir('想象'),'visiondata'那'triangleimages');
定义测试图像的位置。
testimagesdir = fullfile(DataSetdir,'testimages');
创建imageageAtastore.物体保持测试图像。
IMDS = IMAGEDATASTORE(TESTIMAGESDIR);
定义地面真值标签的位置。
testLabelsDir = fullfile (dataSetDir,'testlabels');
定义类名及其关联的标签id。标签id是图像文件中用于表示每个类的像素值。
一会= [“三角形”“背景”];labelids = [255 0];
创建一个PixellabeldAtastore.持有用于测试图像的地面真相像素标签的对象。
pxdstruth = pixellabeldataStore(testlabelsdir,classnames,labelids);
运行语义分段分类器
加载已接受过培训的训练图像语义分割网络三角形.
net = load('trianglesemationnationnetwork.mat');net = net.net;
在测试图像上运行网络。预测标签将在临时目录中写入磁盘并返回为aPixellabeldAtastore.对象。
pxdsresults = semanticseg(IMDS,NET,“writepocation”,TEMPDIR);
运行语义分割网络------------------------------- * Processed 100图像。
评估预测的质量
将预测的标签与地面真理标签进行比较。虽然正在计算语义分割度量,但是将进度打印到命令窗口。
度量= evaluateSemanticSegmentation(pxdsResults,pxdsTruth);
---------------------------------------- *选择指标:全局准确率,类准确率,IoU,加权IoU, BF评分。*处理100张图片。*完成......完成。*数据集指标:GlobalAccuracy MeanAccuracy MeanIoU WeightedIoU MeanBFScore ______________ ____________ _______ ___________ ___________ 0.90624 0.95085 0.61588 0.87529 0.40652
检查类指标
显示分类准确性,联盟(iou)的交叉点,以及数据集中每个类的边界f-1分数。
指标。ClassMetrics
ans =.2×3表精度IOU MeanBFScore ________ _______ ___________三角形1 0.33005 0.028664背景0.9017 0.9017 0.78438
显示混乱矩阵
显示混淆矩阵。
指标。ConfusionMatrix
ans =.2×2表三角背景________ __________三角4730 0背景9601 88069
将标准化的混淆矩阵可视化为图形窗口中的热图。
normConfMatData = metrics.NormalizedConfusionMatrix.Variables;图h = heatmap(classNames,classNames,100*normConfMatData);h.XLabel =“预测类”;h.YLabel =真正的类的;h.Title =“归一化混淆矩阵(%)”;

检查图像度量
可视化所述每图像交点超过联盟(IOU)的直方图。
imageiou = metrics.imagemetrics.meaniou;图表直方图(ImageIou)标题('图像意味着iou')
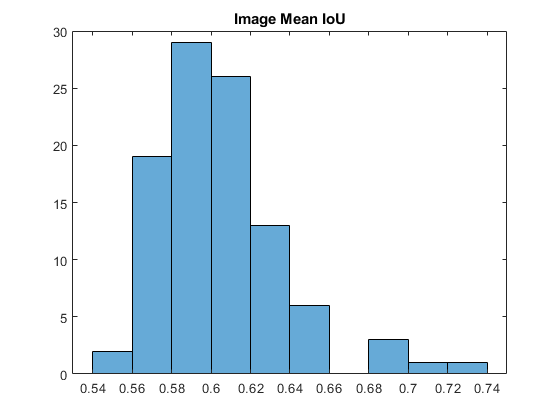
找出IoU最低的测试图像。
[minIoU,worstImageIndex] =分钟(imageIoU);minIoU = minIoU(1);worstImageIndex = worstImageIndex(1);
用最糟糕的IOU,其地面真理标签及其预测标签阅读测试图像进行比较。
WorstTestImage = ReadImage(IMDS,WorstImageIndex);Worsttruelabels = ReadImage(PXDStruth,WorstImageIndex);WorstPredIndetLabels = ReadImage(PXDSResults,WorstImageIndex);
将标签图像转换为可在图形窗口中显示的图像。
worsttruelabelimage = im2uint8(Worsttruelabels == ClassNames(1));ortstpredictedlabelimage = im2uint8(ortpredightlabels == classnames(1));
显示最糟糕的测试图像,地面真理和预测。
谷物ortage =猫(4,Worsttestimage,Worsttrueabelimage,ortstpredidetlabelimage);ortstmontage = imresize(谷物ortmontage,4,“最近”);图蒙太奇(最糟糕的),'尺寸',[1 3])标题(['测试图像与真理与预测。iou ='num2str(minIoU)])

同样,找到最高iou的测试图像。
[maxiou,bestimageindex] = max(imageiou);maxiou = maxiou(1);BestimageIndex = BestimageIndex(1);
重复前面的步骤,读取、转换和显示带有最优IoU的测试图像,该IoU具有基本真实值和预测标签。
bestImageIndex bestTestImage = readimage (imd);bestTrueLabels = readimage (pxdsTruth bestImageIndex);bestPredictedLabels = readimage (pxdsResults bestImageIndex);bestTrueLabelImage = im2uint8(bestTrueLabels == classNames(1));bestPredictedLabelImage = im2uint8(bestPredictedLabels == classNames(1));bestMontage =猫(4 bestTestImage bestTrueLabelImage bestPredictedLabelImage);bestMontage = imresize (bestMontage 4“最近”);图蒙太奇(BESTMONTAGE,'尺寸',[1 3])标题(['测试图像与真理与预测。iou ='num2str(maxIoU)])

指定评估以评估
可选地,列出您想要使用“指标”范围。
定义指标以计算。
评估媒体= [“准确性”“iou”];
计算这些指标三角形测试数据集。
指标= evaluateSemanticSegmentation (pxdsResults pxdsTruth,“指标”,评估梅测定);
评估语义分割结果----------------------------------选定的指标:课程准确性,iou。*处理100张图片。*完成......完成。*数据集指标:意味着意思是____________ _______ 0.61588
显示每个类的所选度量标准。
指标。ClassMetrics
ans =.2×2表准确性iou ________ _______三角形1 0.33005背景0.9017 0.9017
进口像素标记的数据集语义分割
这个例子说明了如何导入语义网络分割像素标记数据集。
标记的数据集是图像的集合和用于训练语义分割网络的相应的地面真理像素标签。有许多公共数据集可以提供具有每个像素标签的带注释图像。为了说明导入这些类型的数据集的步骤,该示例使用剑桥大学[1]中的Camvid DataSet。
Camvid数据集是包含在驾驶时获得的街道级视图的图像集合。DataSet为32种语义课程提供像素级标签,包括汽车,行人和道路。导入Camvid的步骤可用于导入其他像素标记的数据集。
下载Camvid DataSet.
从以下网址下载CamVid图像数据:
imageurl =.'http://web4.cs.ucl.ac.uk/staff/g.brostow/motionsegrecdata/files/701_stillsraw_full.zip';LabelURL =.'http://web4.cs.ucl.ac.uk/staff/g.brostow/motionsegrecdata/data/labeledappoved_full.zip';outputFolder =完整文件(TEMPDIR,'camvid');IMAGEDIR =完整文件(outputFolder,'图片');labeldir = fullfile(outputfolder,“标签”);如果〜存在(outputFolder,'dir')disp('下载557 MB Camvid数据集...');解压缩(imageURL imageDir);解压缩(labelURL labelDir);结尾
注意:数据的下载时间取决于您的Internet连接。上面使用的命令将阻止MATLAB®,直到下载完成。或者,您可以使用Web浏览器首先将数据集下载到本地磁盘。要使用从Web下载的文件,请更改导出目录可变上面的下载文件的位置。
CamVid像素标签
Camvid数据集将像素标签作为RGB图像进行编码,其中每个类由RGB颜色表示。以下是数据集与其RGB编码一起定义的类。
一会= [......“动物”那......“拱道”那......“自行车运动员”那......“桥”那......“建造”那......“车”那......“CartLuggagePram”那......“孩子”那......“column_pole”那......“栅栏”那......“LaneMkgsDriv”那......“lanemkgsnondriv”那......“misc_text”那......“摩托车障碍物”那......“overthmoving”那......“停车盆”那......“行人”那......“路”那......“Roadshoulder”那......“人行道”那......“signsymbol”那......“天空”那......“SUVPickupTruck”那......“交通拥挤”那......“红绿灯”那......“训练”那......“树”那......“卡车_bus”那......“隧道”那......“植被媒体”那......“墙”];
定义标签索引和类名之间的映射Classnames(k)对应于labelIDs(K,:).
labelIDs = [......064 128 064;......% “动物”192 000 128;......%“拱门”000 128 192;......%“骑自行车的人”000 128 064;......% “桥”128 000 000;......% “建造”064 000 128;......% “车”064 000 192;......%”CartLuggagePram”192 128 064;......% “孩子”192 192年128;......%“column_pole”064 064 128;......% “栅栏”128 000 192;......%”LaneMkgsDriv”192 000 064;......%“lanemkgsnondriv”128 128 064;......%“misc_text”192 000 192;......% “MotorcycleScooter”128 064 064;......%”OtherMoving”064 192 128;......%”ParkingBlock”064 064 000;......% “行人”128 064 128;......%的“路”128 128 192;......%“Roadshoulder”000 000 192;......%“人行道”192 128 128;......%“signsymbol”128 128 128;......%“天空”064 128 192;......%“suvpickuptruck”000 000 064;......%”TrafficCone”000 064 064;......% “红绿灯”192 064 128;......% “火车”128 128 000;......% “树”192 128 192;......%“Truck_bus”064 000 064;......% “隧道”192 192 000;......%“植被媒体”064 192 000]。% “墙”
请注意,其他数据集具有不同的编码数据格式。例如,Pascal VOC [2] DataSet使用0到21之间的数字标签ID来对其类标签进行编码。
可视化其中一个CamVid图像的像素标签。
标签= imread(fullfile(labeldir,'0001tp_006690_l.png'));图imshow(标签)%添加颜色栏显示类到颜色映射。N =元素个数(类名);蜱虫= 1 / (N * 2): 1 / N: 1;colorbar ('ticklabels',cellstr(classnames),'蜱',蜱虫,'ticklength',0,'ticklabelinterpreter'那'没有任何');Colormap(Labelids./255)
![]()
加载CamVid数据
可以使用一个像素标记的数据集使用imageageAtastore.和一个PixellabeldAtastore..
创建imageageAtastore.加载CamVid图像。
imds = imageageataStore(fullfile(imagedir,701 _stillsraw_full));
创建一个PixellabeldAtastore.加载Camvid像素标签。
pxds = pixellabeldataStore(Labeldir,ClassNames,LabelIds);
读取第10图像和对应的像素标签图像。
I = readimage (imd, 10);C = ReadImage(PXD,10);
像素标签图像作为分类阵列返回C(I,J)是分配给像素的分类标签我(我,j).在图像的顶部显示像素标签图像。
b = labeloverlay(i,c,'colormap',labelids。/ 255);图imshow(b)%添加一个彩色键。N =元素个数(类名);蜱虫= 1 / (N * 2): 1 / N: 1;colorbar ('ticklabels',cellstr(classnames),'蜱',蜱虫,'ticklength',0,'ticklabelinterpreter'那'没有任何');Colormap(Labelids./255)
![]()
未定义或无效标签
这是常见的像素标记的数据集包括“未定义”或“空隙”的标签。这些用于指定了未标记像素。例如,在CamVid,标签ID [0 0 0]被用于指定的“空隙”级。预计不会训练算法和评估算法,包括在任何计算这些标签。
使用时不需要明确命名“void”类PixellabeldAtastore..未映射到类名的任何标签ID都会自动标记为“未定义”,并从计算中排除。要查看未定义的像素,请使用却创建掩码,然后在图像的顶部显示它。
undefinedpixels = isundefined(c);B = Labeloverlay(i,undefinedpixels);数字imshow(b)标题('未定义的像素标签')
![]()
结合课程
使用公共数据集时,您可能需要将某些类组合以更好地适合您的应用程序。例如,您可能希望培训一个语义分段网络,将场景分成4级:道路,天空,车辆,行人和背景。要使用Camvid DataSet执行此操作,请将上面定义的标签ID进行组以适合新类。首先,定义新类名。
newclassnames = [“路”那“天空”那“汽车”那“行人”那“背景”];
接下来,使用MY-3矩阵的单元格数组组标记ID。
Groupedlabelids = {% 路[128 064 128;......%的“路”128 000 192;......%”LaneMkgsDriv”192 000 064;......%“lanemkgsnondriv”000 000 192;......%“人行道”064 192 128;......%”ParkingBlock”128 128 192;......%“Roadshoulder”]%“天空”[128 128 128;......%“天空”]% “车辆”[064 000 128;......% “车”064 128 192;......%“suvpickuptruck”192 128 192;......%“Truck_bus”192 064 128;......% “火车”000 128 192;......%“骑自行车的人”192 000 192;......% “MotorcycleScooter”128 064 064;......%”OtherMoving”]%“行人”[064 064 000;......% “行人”192 128 064;......% “孩子”064 000 192;......%”CartLuggagePram”064 128 064;......% “动物”]% “背景”[128 128 000;......% “树”192 192 000;......%“植被媒体”192 128 128;......%“signsymbol”128 128 064;......%“misc_text”000 064 064;......% “红绿灯”064 064 128;......% “栅栏”192 192年128;......%“column_pole”000 000 064;......%”TrafficCone”000 128 064;......% “桥”128 000 000;......% “建造”064 192 000;......% “墙”064 000 064;......% “隧道”192 000 128;......%“拱门”]};
创建一个PixellabeldAtastore.使用新类和标签ID。
pxds = pixellabeldataStore(Labeldir,Newclassnames,Groupedlabelids);
读取第10像素标签图像并将其显示在图像的顶部。
C = ReadImage(PXD,10);CMAP = JET(NUMER(NewClassNames));b = labeloverlay(i,c,'colormap',CMAP);图imshow(b)%加彩条N = numel(newClassNames);蜱虫= 1 / (N * 2): 1 / N: 1;colorbar ('ticklabels',cellstr(newclassnames),'蜱',蜱虫,'ticklength',0,'ticklabelinterpreter'那'没有任何');颜色表(CMAP)
![]()
这PixellabeldAtastore.与新的类名,现在可以用于训练的4类的网络,而不必修改原CamVid像素标签。
参考
Brostow, Gabriel J., Julien Fauqueur和Roberto Cipolla。"视频中的语义对象类:高清晰度地面真实数据库"模式识别字母30.2(2009):88-97。
[2] Everhingham,M.等人。“Pascal Visual对象课程挑战2012结果。”请参阅http:// www。帕斯卡尔网络。ORG /挑战/ VOC / VOC2012 / WORKSHOP / INDEX。HTML..卷。5. 2012。
你也可以从以下列表中选择一个网站:
