提升过滤器组
这个例子展示了如何使用提升来逐步改变一个完美重构滤波器组的特性。下图显示了提升的三个规范步骤:分割、预测和更新。
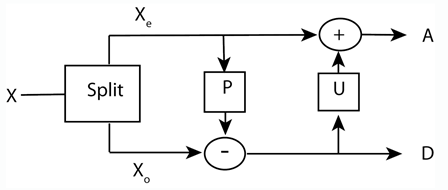
提升的第一步是简单地将信号分解为偶数和奇数索引的样本。这些被称为多相分量,在提升过程中这个步骤通常被称为“懒惰”的提升步骤,因为你真的没有做那么多的工作。您可以在MATLAB™中通过使用创建一个“懒惰”提升方案来实现这一点提升方案使用默认设置。
LS=提升方案;
使用提升方案获得随机信号的1级小波分解。
1 x = randn(8日);[ALazy, DLazy] =轻型(x,“提升计划”,LS,“水平”1);
MATLAB索引从1开始ALazy包含x和的奇索引样本DLazy包含偶数索引样本。大多数提升解释都假设信号从样本0开始,因此ALazy是偶数索引的样本吗DLazy奇数索引样本。这个例子遵循后一个惯例。“惰性”小波变换将信号的一半视为小波系数,DLazy,另一半作为标度系数,ALazy.在提升的环境中,这是完全一致的,但简单的数据分割确实会稀疏或捕获任何相关的细节。
提升方案的下一步是基于偶数样本预测奇数样本。其理论基础是大多数自然信号和图像在相邻样本之间表现出相关性。因此,您可以使用偶索引样本“预测”奇索引样本。你的预测和实际值之间的差异是预测器错过的数据的“细节”。这个缺失的细节就是小波系数。
在方程形式中,您可以将预测步骤编写为 在哪里 小波系数是否在更精细的尺度上 是一些精细尺度的缩放系数。 是预测运算符。
添加一个简单的(Haar)预测步骤,从奇数(细节)系数中减去偶数(近似)系数 .换句话说,它根据前面的偶样本预测奇样本。
Elemlifstep=提升步骤(“类型”,“预测”,“系数”,-1,“MaxOrder”,0);
上面的代码说“创建一个基本的预测提升步骤使用一个多项式 拥有最高权力 。系数为-1。更新延迟提升方案。
LSN=添加提升(LS,Elemlifstep);
对信号应用新的提升方案。
[A,D]=lwt(x,“提升计划”LSN,“水平”1);
请注意一个与中的相同ALazy.这是预期的,因为你没有修改近似系数。
[阿拉齐语]
ans =4×20.5377 0.5377 -2.2588 -2.2588 0.3188 0.3188 -0.4336 -0.4336
如果你看一下D{1},你可以看到它们等于DLazy {1} -ALazy.
Dnew = DLazy {1} -ALazy;(Dnew D {1})
ans =4×21.2962 1.2962 3.1210 3.1210 -1.6265 -1.6265 0.7762 0.7762
比较Dnew来D.假设有这样一个例子,信号每两个采样都是分段常数。
V = [1 -1 1 -1 1 -1];u = repelem (v, 2)
u=1×121 1 -1 -1 1 1 -1 -1 1 1 -1 -1
将新的提升方案应用于u.
(非盟,Du) =轻型(u,“提升计划”LSN,“水平”,1);Du{1}
ans =6×10 0 0 0 0
你看到所有的杜为零。这个信号已经被压缩了,因为所有的信息现在包含在6个样本中,而不是12个样本中。你可以很容易地重建原始信号
urecon = ilwt (Au,杜“提升计划”, LSN);马克斯(abs (u (:) -urecon (:)))
ans = 0
在预测步骤中,您预测信号中相邻的奇数样本的值与前一个偶数样本的值相同。显然,这只适用于琐碎的信号。小波系数捕捉预测值和实际值之间的差异(奇数样本)。最后,使用更新步骤根据在预测步骤中获得的差异更新偶数样本。在这种情况下,请使用以下命令进行更新 .它用偶数和奇数系数的算术平均值替换每个偶数索引系数。
elsUpdate = liftingStep (“类型”,“更新”,“系数”,1/2,“MaxOrder”,0);LSupdated=addlift(LSN,elsUpdate);
用改进后的提升方案对信号进行小波变换。
[A,D]=lwt(x,“提升计划”LSupdated,“水平”1);
如果你比较一个原始信号,x,您可以看到信号平均值被捕获到近似系数中。
[平均值(A)平均值(x)]
ans =1×2-0.0131 - -0.0131
事实上一个很容易从x由以下。
n = 1;为2 = 1:2:元素个数(x) meanz (n) =意味着([x (ii) x (2 + 1)]);n = n + 1;结束
比较梅恩兹和一个.与往常一样,您可以反转提升方案以获得数据的完美重构。
xrec = ilwt (A, D,“提升计划”, LSupdated);马克斯(abs (x-xrec))
ans = 2.2204 e-16
通常在末尾添加一个标准化步骤,以使信号中的能量( 范数)保留为标度系数和小波系数中的能量之和。如果没有此归一化步骤,则不会保留能量。
规范(x, 2) ^ 2
ans=11.6150
规范(2)^ 2 +规范(D {1}, 2) ^ 2
ans = 16.8091
添加必要的规范化步骤。
LSsteps = LSupdated.LiftingSteps;LSscaled = liftingScheme (“提升步骤”LSsteps,“NormalizationFactors”,[sqrt(2)];[A,D]=lwt(x,“提升计划”LSscaled,“水平”1);规范(2)^ 2 +规范(D {1}, 2) ^ 2
ans=11.6150
现在, 信号的范数等于标度系数和小波系数中的能量之和。您在本例中开发的提升方案是Haar提升方案。
小波工具箱™通过支持许多常用的提升金宝app方案提升方案使用预定义的预测和更新步骤以及归一化因子。
lshaar = liftingScheme (“小波”,“哈雾”);
要看到不是所有的提升方案都由单一的预测和更新提升步骤组成,检查对应的提升方案生物3.1小波。
lsbior3_1=提升方案(“小波”,“bior3.1”)
lsbior3_1=小波:“bior3.1”提升步骤:[3×1]提升步骤规格化因子:[2.1213 0.4714]自定义低通滤波器:[]提升步骤详细信息:类型:“更新”系数:-0.3333 MaxOrder:-1类型:“预测”系数:[-0.3750-1.1250]MaxOrder:1类型:“更新”系数:0.4444 MaxOrder:0
您还可以从以下列表中选择网站: